Lesson 4.1.1 逻辑回归模型构建与多分类学习方法(上)
,模型效果好,可解释性强,在后面的特征工程,和集成学习中也非常经常使用。因此要花大篇幅来学逻辑回归的理论和使用,同时补充机器学习的相关知识。
逻辑回归的基本原理,从整体上来划分可以分为两个部分:
- 其一是关于模型方程的构建,也就是方程的基本形态,当然也包括模型的基本性质及其结果解读;
- 其二则是模型参数求解,即在构建完模型之后如何利用数学工具求解最佳参数。
而这两部分其实都可以从多个角度出发进行理解,基本划分情况如下
- 模型构建部分:
- 可以从广义线性回归(Generalized liner model)+对数几率函数(logit function)角度理解
- 也可以从随机变量的逻辑斯蒂分布(logistic distribution)角度出发进行理解;
- 参数求解部分:
- 可以借助极大似然估计(Maximum Likelihood Estimate)方法求解,
- 也可以借助KL离散度基本理论构建二分类交叉熵损失函数求解。
而无论这些基础理论难易程度如何,其对于此后的机器学习都是至关重要的,因此将先从简单角度出发,先构建对逻辑回归基本理论体系的完整认知,然后再补充更加复杂的理论体系,为后续其他算法的学习做铺垫。
广义线性模型(Generalized liner model)的基本定义
在Lesson3中我们曾谈到关于线性回归的局限性,这种局限性的根本由模型本身的简单线性结构(自变量加权求和预测因变量)导致的。如果说线性回归是在一个相对严格的条件下建立的简单模型,那么在后续实践应用过程中,人们根据实际情况的不同,在线性回归的基础上又衍生出了种类繁多的线性类模型。
。如下图所示:
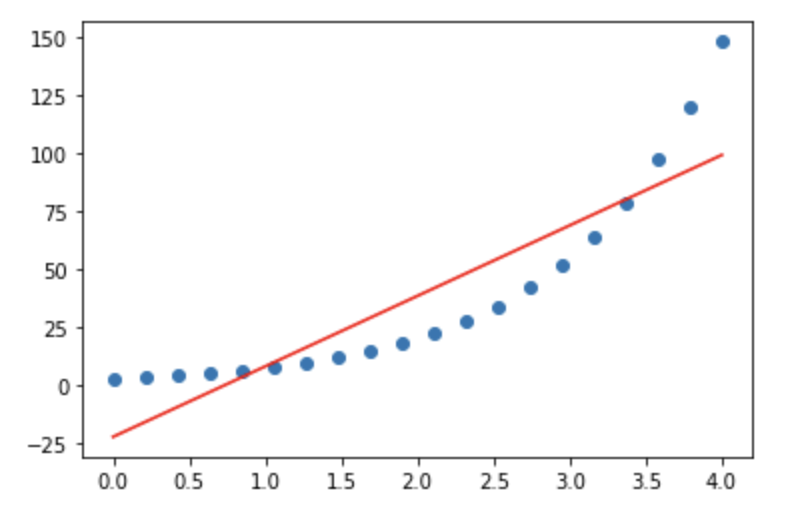
上图中蓝点是真实数据,由$y=e^{(x+1)}$生成,红线是使用线性回归模型预测的结果,为$y=30.44x-22.38$,可以看出预测结果和真实数据存在巨大差异,但此时如果我们在等号右边加上以$e$为底的指数运算,也就是将线性方程输出结果进行以$e$为底的指数运算转换之后去预测y,即将方程改写为$$y=e^{(\hat w^T \cdot \hat x)}$$,等价于$$lny = \hat w^T \cdot \hat x$$即相当于是线性方程输出结果去预测$y$取以$e$为底的对数运算之后的结果。
此时我们可以带入𝑙𝑛𝑦lny进行建模,可得到方程$$lny=x+1$$等价于$$y=e^{(x+1)}$$即解出原方程。
上述过程的具体代码去代码.ipynb看。
通过上面的过程,我们不难发现, 而在上例中,这种捕捉非线性规律的本质,是在方程加入𝑙𝑛ln对数函数之后,能够使得模型的输入空间(特征所在空间)到输出空间(标签所在空间)进行了非线性的函数映射。
。
广义线性模型的一般形式可表示如下: $$ g(y)=\hat w^T \cdot \hat x $$ 等价于 $$ y = g^{-1}(\hat w^T \cdot \hat x) $$ 其中$g(z)$为联系函数(link function),$g^{-1}(z)$为联系函数的反函数(inverse function)。
而如上例中的情况,
注:一般来说广义线性模型要求联系函数必须是单调可微函数。
从广义线性模型的角度出发,当联系函数为$g(x)=x$时,$g(y)=y=\hat w^T \cdot \hat x$,此时就退化成了线性模型。而能够通过联系函数拓展模型捕捉规律的范围,这也就是广义的由来。
所有的联系函数都是默认加到等号左边的,即对
y使用联系函数
如果是从数理统计分析角度出发进行建模,对数线性模型建模的基本要求是观测数据服从泊松分布。机器学习由于是后验,可省略相关检验过程。
对数几率模型与逻辑回归
逻辑回归也被称为对数几率回归。接下来,我们从广义线性模型角度理解逻辑回归。
先搞数学
对数几率模型(logit model)
几率(odd)与对数几率
几率不是概率,而是一个事件发生与不发生的概率的比值。假设某事件发生的概率为p,则该事件不发生的概率为1-p,该事件的几率为: $$ odd(p)=\frac{p}{1-p} $$ 在几率的基础上取(自然底数的)对数,则构成该事件的对数几率(logit): $$ logit(p) = ln\frac{p}{1-p} $$
注,logit的是log unit对数单元的简写,和中文中的“逻辑”一词并没有关系。对数几率模型也被称为对数单位模型(log unit model)。
对数几率模型
,即$$ g(y)=ln\frac{y}{1-y} $$
所有的联系函数都是默认加到等号左边的,即对
y使用联系函数
则该广义线性模型为: $$ g(y)=ln\frac{y}{1-y}=\hat w^T \cdot \hat x $$ 此时模型就被称为对数几率回归(logistic regression),也被称为逻辑回归。
国内很多学者认为,logistic regression一词和逻辑的含义相差甚远,将其译为逻辑回归并不妥当。
数理统计分析方法构建逻辑回归时,基本假设要求变量y必须服从伯努利分布(Bernoulli)。机器学习由于是后验,可省略相关检验过程。
逻辑回归与Sigmoid函数
对数几率函数与Sigmoid函数
当然,更进一步的,如果我们希望将上述对数几率函数“反解”出来,也就是改写为$y = f(x) = \hat w^T \cdot \hat x$形式,则可参照下述形式: $$ y = \frac{1}{1+e^{-(\hat w^T \cdot \hat x)}} $$ 同时我们也能发现,对对数几率函数的反函数为: $$ y = f(z) = \frac{1}{1+e^{-z}} $$ 其中 $$ z = \hat{w}^T \cdot \hat{x} $$ 我们可以简单观察该函数的函数图像:
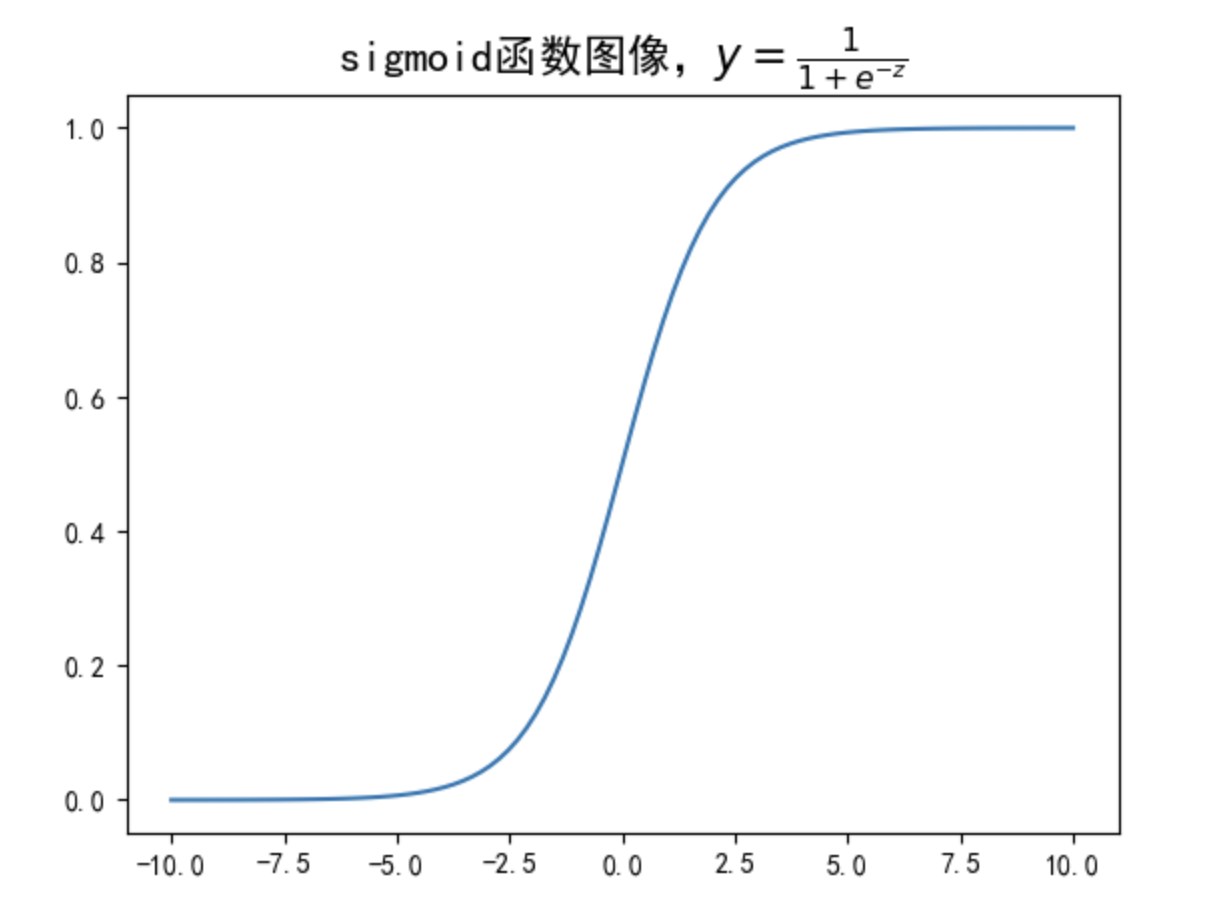
能够看出该函数的图像近似S形,这种类似S形的函数,也被称为Sigmoid函数。
注:Sigmoid严格定义是指形如S型的函数,并不是特指某个函数,也就是说,从严格意义来讨论,函数$f(z) = \frac{1}{1+e^{-z}}$只能被称为是Sigmoid函数的一种。但实际上,由于该函数是最著名且通用的Sigmoid函数,因此大多数时候,我们在说Sigmoid函数的时候,其实就是在指$f(z) = \frac{1}{1+e^{-z}}$函数。后续对该概念不做区分,Sigmoid函数即指$f(z) = \frac{1}{1+e^{-z}}$函数。
Sigmoid函数性质
对于Sigmoid函数来说,函数是单调递增函数,并且自变量在实数域上取值时,因变量取值范围在(0,1)之间。并且当自变量取值小于0时,因变量取值小于0.5,当自变量取值大于0时,因变量取值大于0.5。
其次,我们简单查看Sigmoid导函数性质,
令 $$ Sigmoid(x) = \frac{1}{1+e^{-x}} $$ 对其求导可得: $$ \begin{aligned} Sigmoid'(x) &= (\frac{1}{1+e^{-x}})' \ &=((1+e^{-x})^{-1})' \ &=(-1)(1+e^{-x})^{-2} \cdot (e^{-x})' \ &=(1+e^{-x})^{-2}(e^{-x}) \ &=\frac{e^{-x}}{(1+e^{-x})^{2}} \ &=\frac{e^{-x}+1-1}{(1+e^{-x})^{2}} \ &=\frac{1}{1+e^{-x}} - \frac{1}{(1+e^{-x})^2} \ &=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}}) \ &=Sigmoid(x)(1-Sigmoid(x)) \end{aligned} $$
在后续求梯度时,大大提升了计算效率
据此,我们可以画出sigmoid导函数的图像
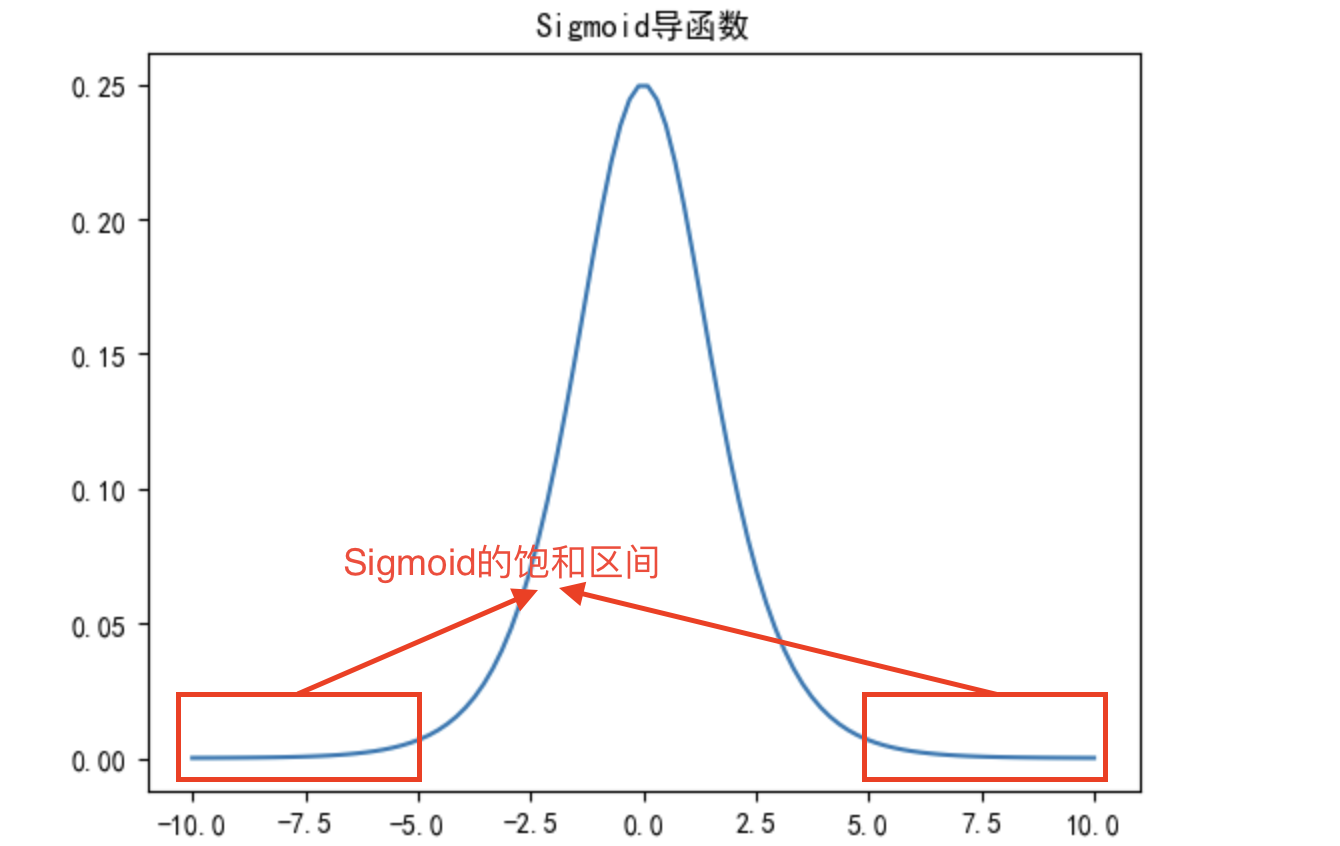
可以发现,Sigmoid导函数在实数域上取值大于0,并且函数图像先递增后递减,并在0点取得最大值。
据此我们也可以进一步讨论Sigmoid函数性质:
- 由于导函数始终大于0,因此Sigmoid函数始终递增
- 并且导函数在0点取得最大值,因此Sigmoid在0点变化率最快,
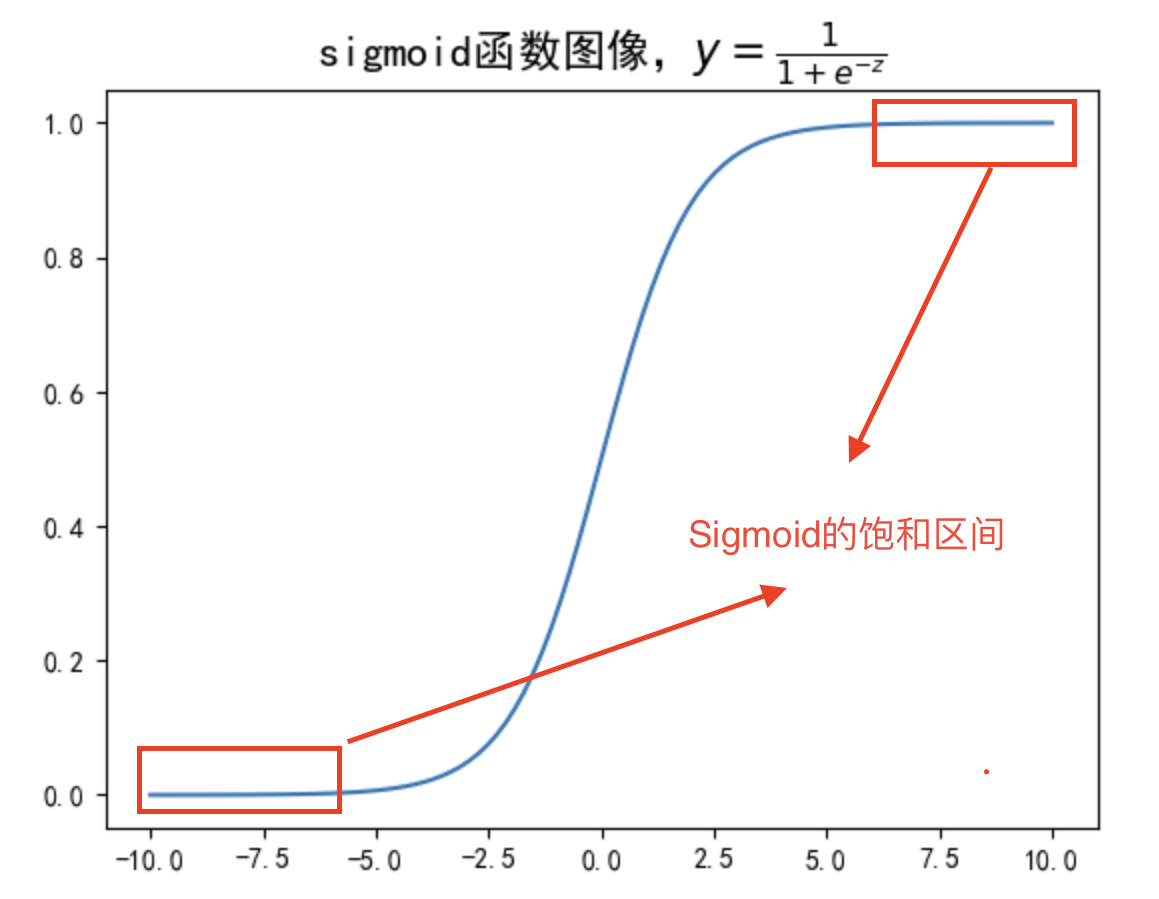
- 而在远离零点的点,Sigmoid导函数取值较小,因此该区间Sigmoid函数变化缓慢。该区间也被称为Sigmoid的饱和区间。
对应的Sigmoidhanshu饱和区间如下图所示:
总结,Sigmoid性质如下:
| 性质 | 说明 |
|---|---|
| 单调性 | 单调递增 |
| 变化率 | 0点变化率最大,越远离0点变化率越小 |
| 取值范围 | (0,1) |
| 凹凸性 | 0点为函数拐点,0点之前函数为凸函数,此后函数为凹函数 |
逻辑回归模型输出结果与模型可解释性
从整体情况来看,逻辑回归在经过Sigmoid函数处理之后,是将线性方程输出结果压缩在了0-1之间,因此在实际模型应用过程中,逻辑回归主要应用于二分类问题的预测。
一般来说,我们会将二分类的类别用一个两个分类水平取值的离散变量来代表,两个分类水平分别为0和1。该离散变量也被称为0-1离散变量。
连续型输出结果转化为分类预测结果
对于逻辑回归输出的(0,1)之间的连续型数值,我们只需要确定一个“阈值”,就可以将其转化为二分类的类别判别结果。通常来说,这个阈值是0.5,即以0.5为界,调整模型输出结果: $$ \begin{equation} y_{cla}=\left{ \begin{aligned} 0, y<0.5 \ 1, y≥0.5 \end{aligned} \right. \end{equation} $$ 其中,$y_{cla}$为类别判别结果,而$y$为逻辑回归方程输出结果$sigmoid(\hat w^T \cdot \hat x)$。
例子去看代码.ipynb
逻辑回归输出结果Y是否是概率
在中,逻辑回归要求因变量(即目标)满足伯努利分布,可以通过假设检验确保这些条件成立。这时,模型的输出结果才可以解释为严格意义上的概率。
在中,逻辑回归模型的自变量(特征)没有严格的分布要求,主要是通过算法来提升预测效果。因此,模型输出的值虽然在0到1之间,但不一定是真正的概率,只是近似的概率值,适用于具体的业务场景。
在现实场景中,逻辑回归的输出结果常常被解释为事件发生的概率,即 P(y=1),尽管这种解读在统计学上不总是严谨的。在机器学习的实用导向下,只要这种解释能够在业务中产生有用的指导意义,便被广泛接受。
逻辑回归函数的可解释性
可解释性一
举个例子,根据逻辑回归方程: $$ y = \frac{1}{1+e^{-(1-x)}} $$ 可解读为x每增加1,样本属于1的概率的对数几率就减少1。(此处是对数几率$\ln \frac{y}{1-y} $,不是y)
此时的可解释性也就是自变量变化对因变量变化的贡献程度的解读
可解释性二
而这种基于自变量系数的可解释性不仅可以用于自变量和因变量之间的解释,还可用于自变量重要性的判别当中,例如,假设逻辑回归方程如下: $$ ln\frac{y}{1-y} = x_1+2x_2-1 $$ 则可解读为$x_2$的重要性是$x_1$的两倍,$x_2$每增加1的效果(令样本为1的概率的增加)是$x_1$增加1效果的两倍。
逻辑回归概率的表现形式
如果我们将逻辑回归模型输出结果视作样本属于1类的概率,则可将逻辑回归模型改写成如下形式: $$ p(y=1|\hat x;\hat w) =\frac{1}{1+e^{-(\hat w^T \cdot \hat x)}} $$
$$ p(y=0|\hat x;\hat w) =\frac{e^{-(\hat w^T \cdot \hat x)}}{1+e^{-(\hat w^T \cdot \hat x)}} $$
Lesson 4.1.2 逻辑回归模型构建与多分类学习方法(下)
多分类学习与多分类逻辑回归
此前的讨论都是基于二分类问题(0-1分类问题)展开的讨论,而如果要使用逻辑回归解决多分类,则需要额外掌握一些技术手段。
总的来说,如果要使用逻辑回归解决多分类问题,一般来说有两种方法:
将逻辑回归模型改写为多分类模型
- Softmax回归
使用多分类学习方法:,也就是先将数据集进行拆分,然后多个数据集可训练多个模型,然后再对多个模型进行集成。这里所谓集成,指的是使用这多个模型对后续新进来数据的预测方法。具体来看,依据该思路一般有三种实现策略:
一对一(One-vs-One, OvO)
一对剩余(One-vs-Rest, OvR)
多对多(Many vs Many,MvM)
OvO策略
拆分策略
基本过程是将每个类别对应数据集单独拆分成一个子数据集,然后令其两两组合,再来进行模型训练。例如,对于下图中的四分类数据集,根据标签类别可将其拆分成四个数据集,然后再进行两两组合,总共有6种组合,也就是$C^2_4$种组合。拆分过程如下所示:
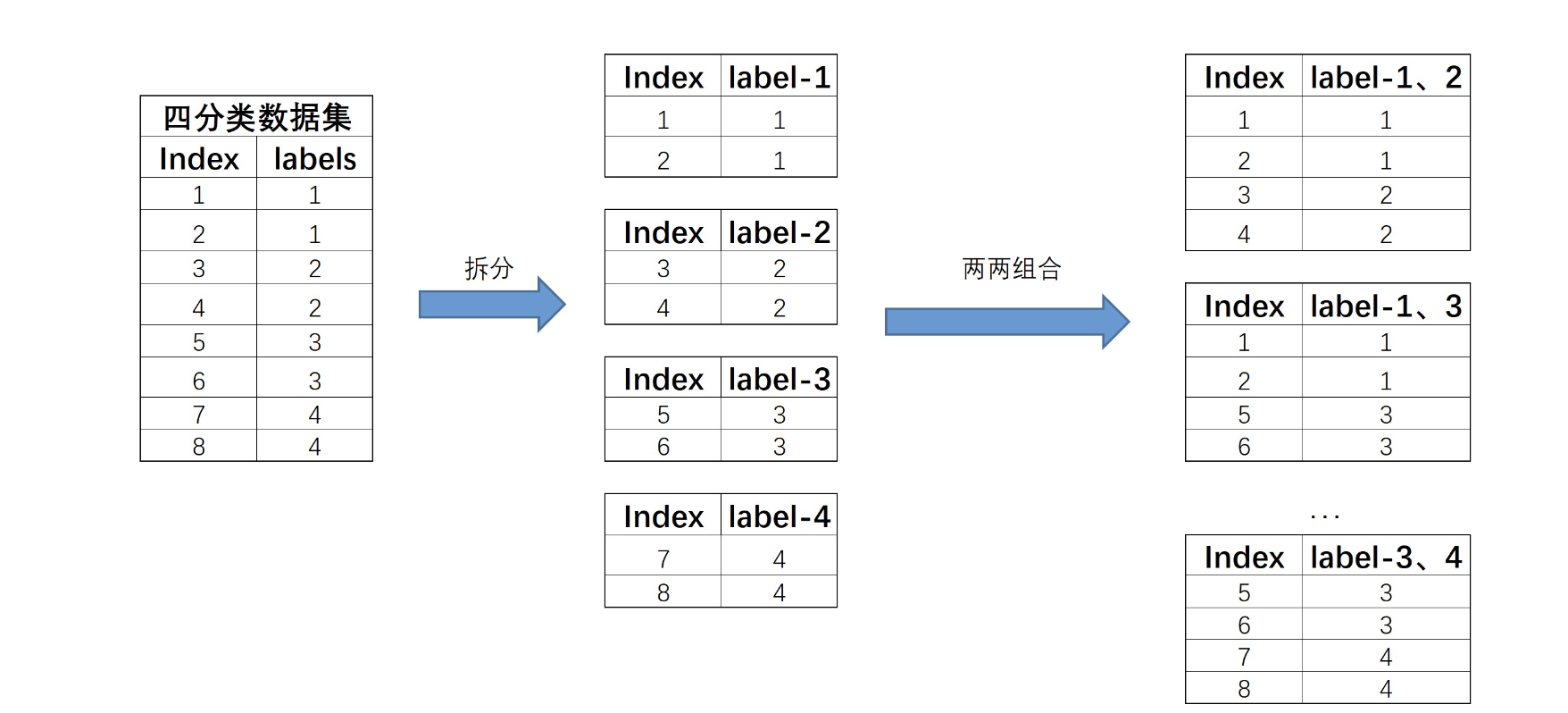
然后在这6个新合成的数据集上,我们就能训练6个分类器。
集成策略
当模型训练完成之后,接下来面对新数据集的预测,可以使用投票法从6个分类器的判别结果中挑选最终判别结果。

根据少数服从多数的投票法能够得出,某条新数据最终应该属于类别1。
OvR策略
拆分策略
和OvO的两两组合不同,OvR策略则是每次将一类的样例作为正例、其他所有数据作为反例来进行数据集拆分。对于上述四分类数据集,OvR策略最终会将其拆分为4个数据集,基本拆分过程如下:
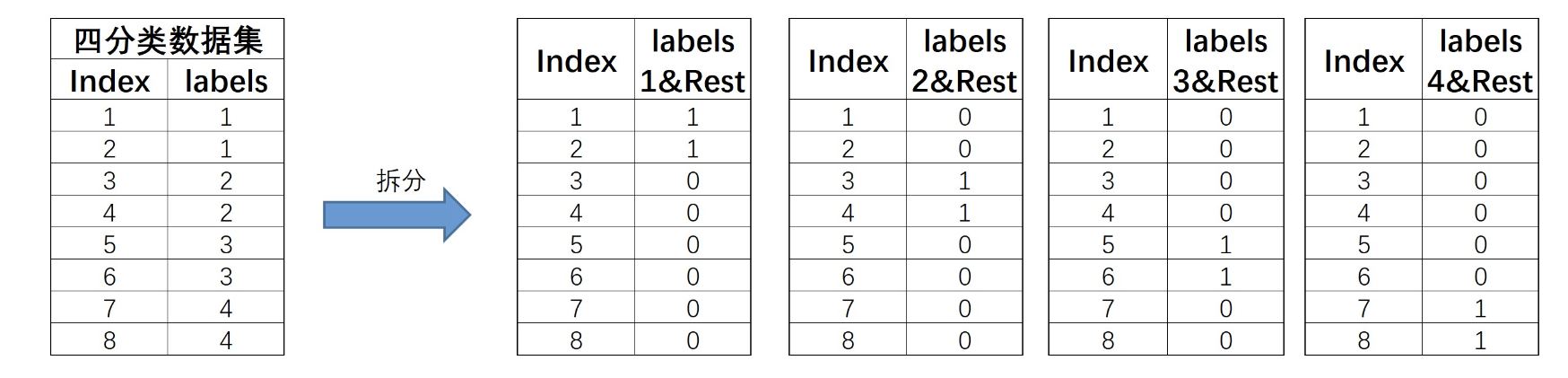
此4个数据集就将训练4个分类器。注意,在OvR的划分策略种,是将rest无差别全都划分为负类。
集成策略
在对新样本进行分类时,OvR 方法会使用所有训练好的分类器来进行预测。对于每个分类器,输出一个预测结果(正类或负类):

OvO和OvR的比较
MvM策略(结合了ECOC使用)
相比于OvO和OvR,MvM是一种更加复杂的策略。MvM要求同时将若干类化为正类、其他类化为负类,并且要求多次划分,再进行集成。一般来说,通常会采用一种名为“纠错输入码”(Error Correcting Output Codes,简称ECOC)的技术来实现MvM过程。
ECOC 方法则不同,它通过编码矩阵为每个类别分配一个独特的编码向量,从而将多分类问题分解成多个二分类问题,且引入了“错误纠正”机制以提升鲁棒性。因此,ECOC 的关键在于编码,而不是简单的类别分组。
拆分策略(MvM思想)
此时对于上述4分类数据集,拆分过程就会变得更加复杂,我们可以任选其中一类作为正类、其余作为负类,也可以任选其中两类作为正类、其余作为负数,以此类推。由此则诞生出了非常多种子数据集,对应也将训练非常多个基础分类器。
当然,将某一类视作正类和将其余三类视作正类的预测结果相同,对调下预测结果即可,此处不用重复划分。
例如,对于上述4分类数据集,则可有如下划分方式:
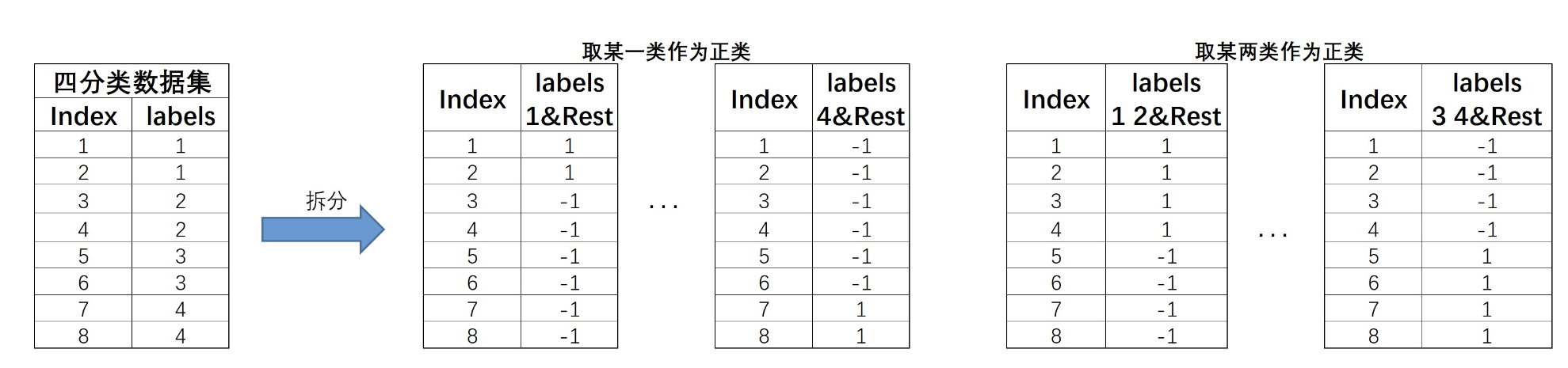
由此OvR实际上是MvM的一种特例。
集成策略(ECOC评估方法)
在下面的示例中,将 MvM 的分组策略与 ECOC 的编码思想结合起来。
我们定义一个编码矩阵。这个矩阵的行代表类别,列代表二分类器,每一列的值表示该类别在这个分类器中的标签(+1表示正类,-1表示负类,0表示不参与该分类器)。假设我们用以下编码矩阵:
| 类别 | 分类器 1 | 分类器 2 | 分类器 3 |
|---|---|---|---|
| A | +1 | -1 | +1 |
| B | -1 | +1 | +1 |
| C | +1 | +1 | -1 |
解释:编码矩阵中的第一行[+1,−1,+1],表示类别 A 在分类器 1 中为正类(+1),在分类器 2 中为负类(-1),在分类器 3 中为正类(+1)。
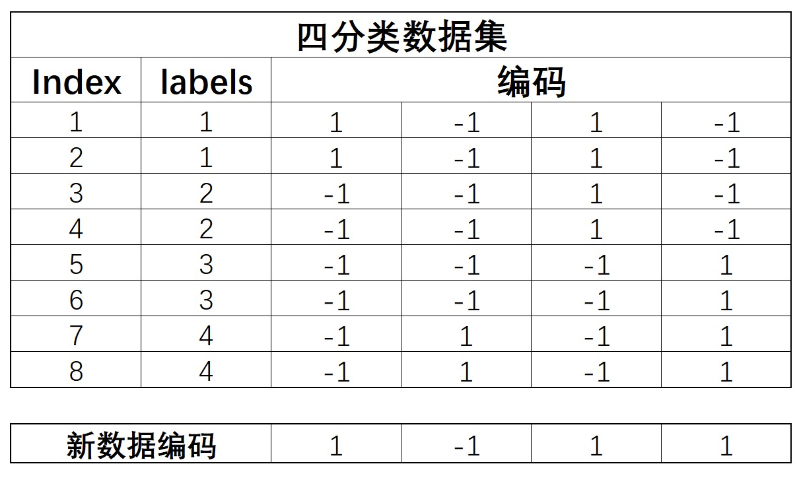
解释:新数据的编码[1,-1,1,1],表示该数据在分类器1中为正类,在分类器2中为负类,在分类器3中为正类,在分类器4中为正类。
同时,我们使用训练好的四个基础分类器对新数据进行预测,也将产生四个结果,而这四个结果也可构成一个四位的新数据的编码,如上图。
不难发现,如果预测足够准确,编码其实是和类别一一对应的。
距离计算就是传统的三种:
L1曼哈顿距离$(p = 1)$:
- $$d(x, y) =\sum_{i = 1}^{n}(|x_i-y_i|)$$
L2欧几里得距离$(p = 2)$:
- $d(x, y) = \sqrt{\sum_{i = 1}^{n}(x_i-y_i)^2}$
切比雪夫距离$(p = ∞)$:
- $d(x, y) = max∣xi−yi∣$
闵可夫斯基距离:
- $$d(x, y) = \sqrt[p]{\sum_{i = 1}^{n}(|x_i-y_i|)^p}$$
L1距离和L2距离都是闵可夫斯基距离的在n=1和n=2时的特例
ECOC方法评估
对于ECOC方法来说,**编码越长预测结果越准确,**不过编码越长也代表着需要耗费更多的计算资源,并且由于模型本身类别有限,因此数据集划分数量有限,编码长度也会有限。不过一般来说,相比OvR,MvM方法效果会更好。