Seaborn可视化基础
- Matplotlib是高度可定制的,但快速实施出吸引人的细节就变得有些复杂。
- Seaborn作为一个带着定制主题和高级界面控制的Matplotlib扩展包,能让绘图变得更轻松
采用seaborn的默认全局配置
# 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 采用seaborn的默认全局配置
sns.set()- axes_style 画布风格配置
- context 线条配置
- palette 调色板
样式控制
axes_style:获取设置背景样式的属性字典
set_style(style, rc):设置背景样式
style可选的5个seaborn默认主题:
- darkgrid 黑色网格(默认)
- whitegrid 白色网格
- dark 黑色背景
- white 白色背景
- ticks 有刻度线的白背景
rc 背景样式的属性字典设置接口
sns.axes_style()函数可以返回当前可以设置的属性字典
# 查看当前画布风格的各种设置
sns.axes_style()
# 返回
{'axes.facecolor': '#EAEAF2',
'axes.edgecolor': 'white',
'axes.grid': True,
'axes.axisbelow': True,
'axes.labelcolor': '.15',
...
'ytick.right': False,
'axes.spines.left': True,
'axes.spines.bottom': True,
'axes.spines.right': True,
'axes.spines.top': True}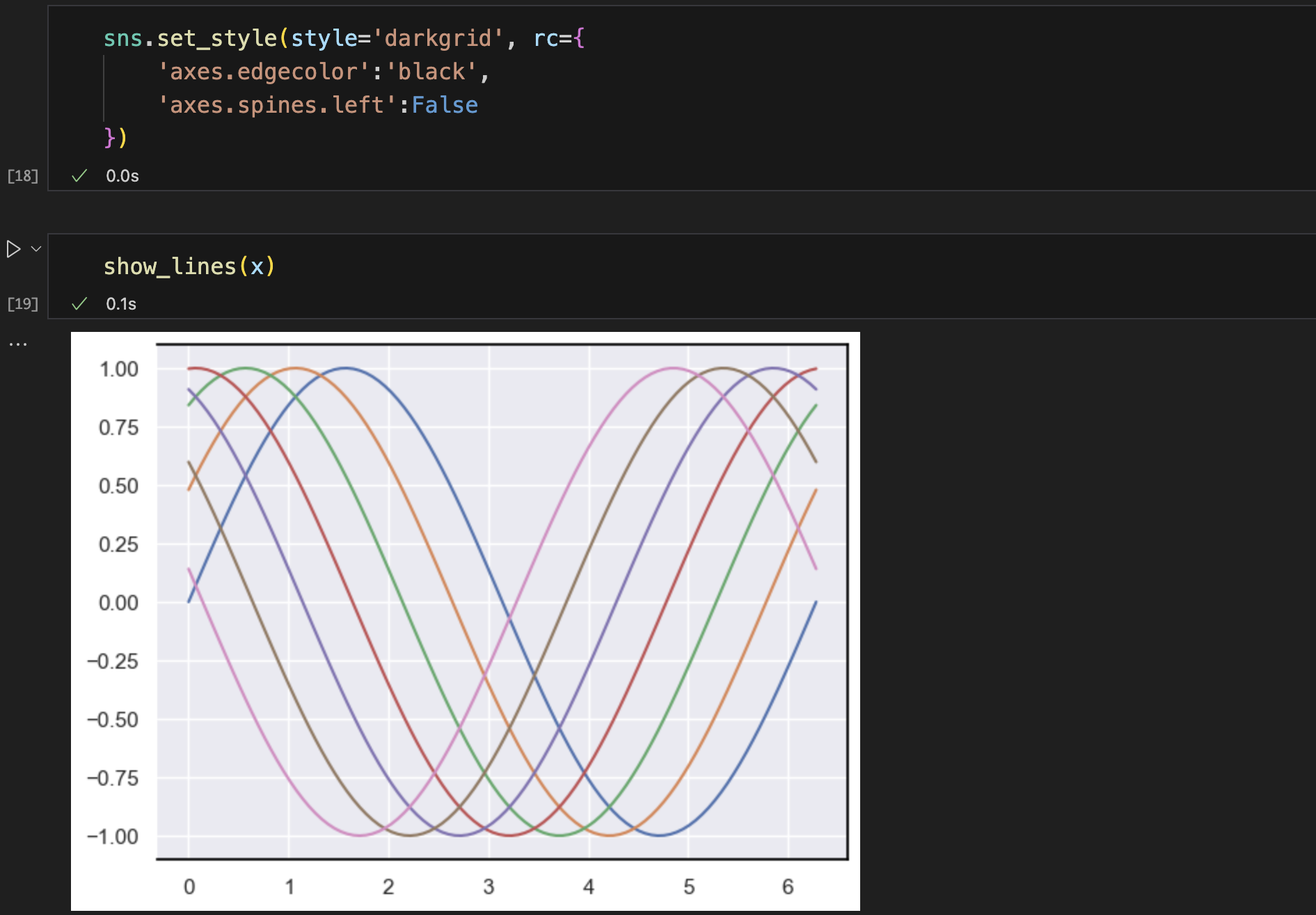
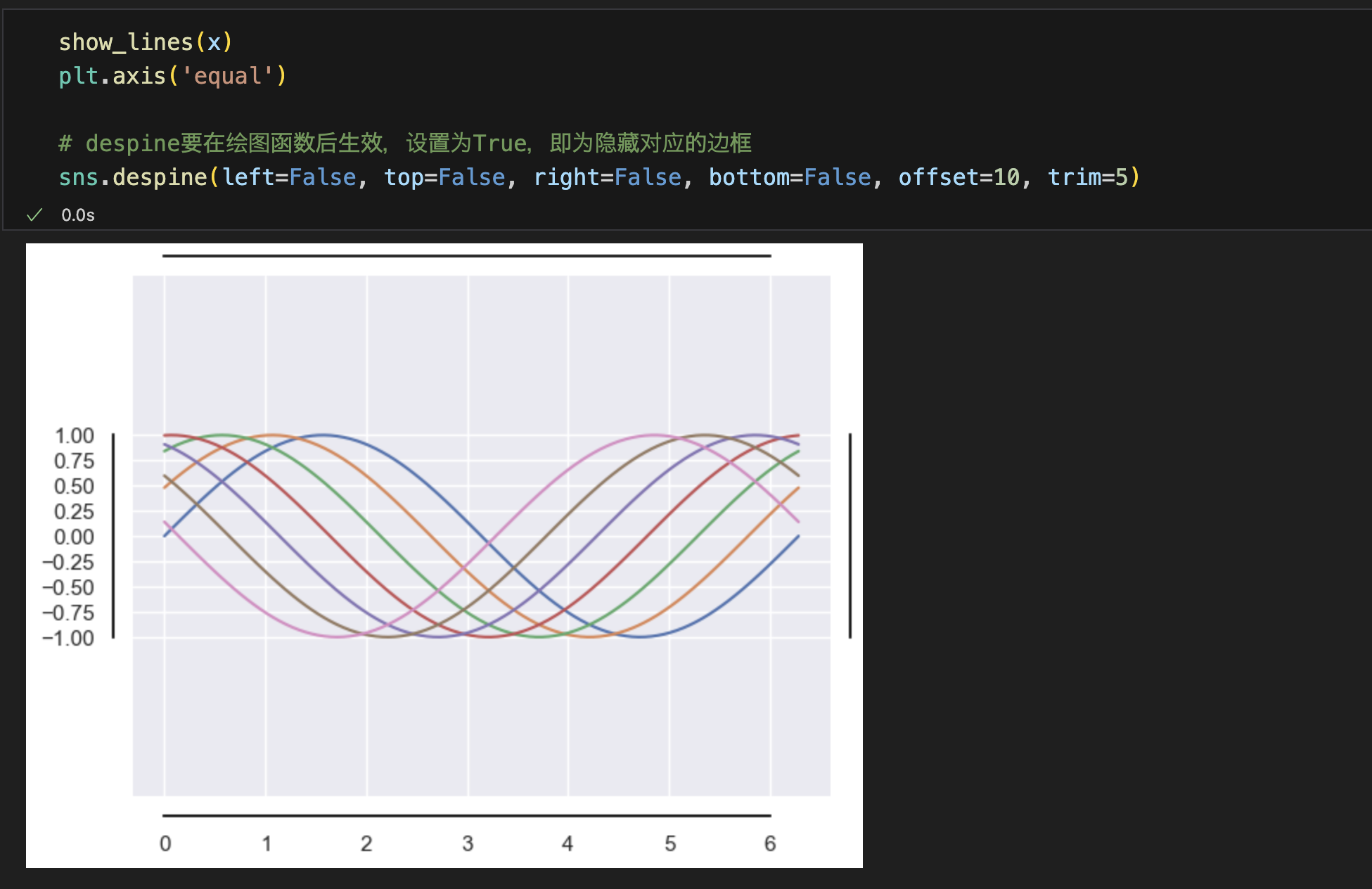
边框控制 despine()
- 默认删除上方和右方的边框
- offset 两坐标轴分开的距离
- trim True False限制留存的边框范围,没有图像的地方会舍弃
- top right bottom left (True\False)指定是否删除对应的边框
- 注意边框控制的代码应放在绘图之后
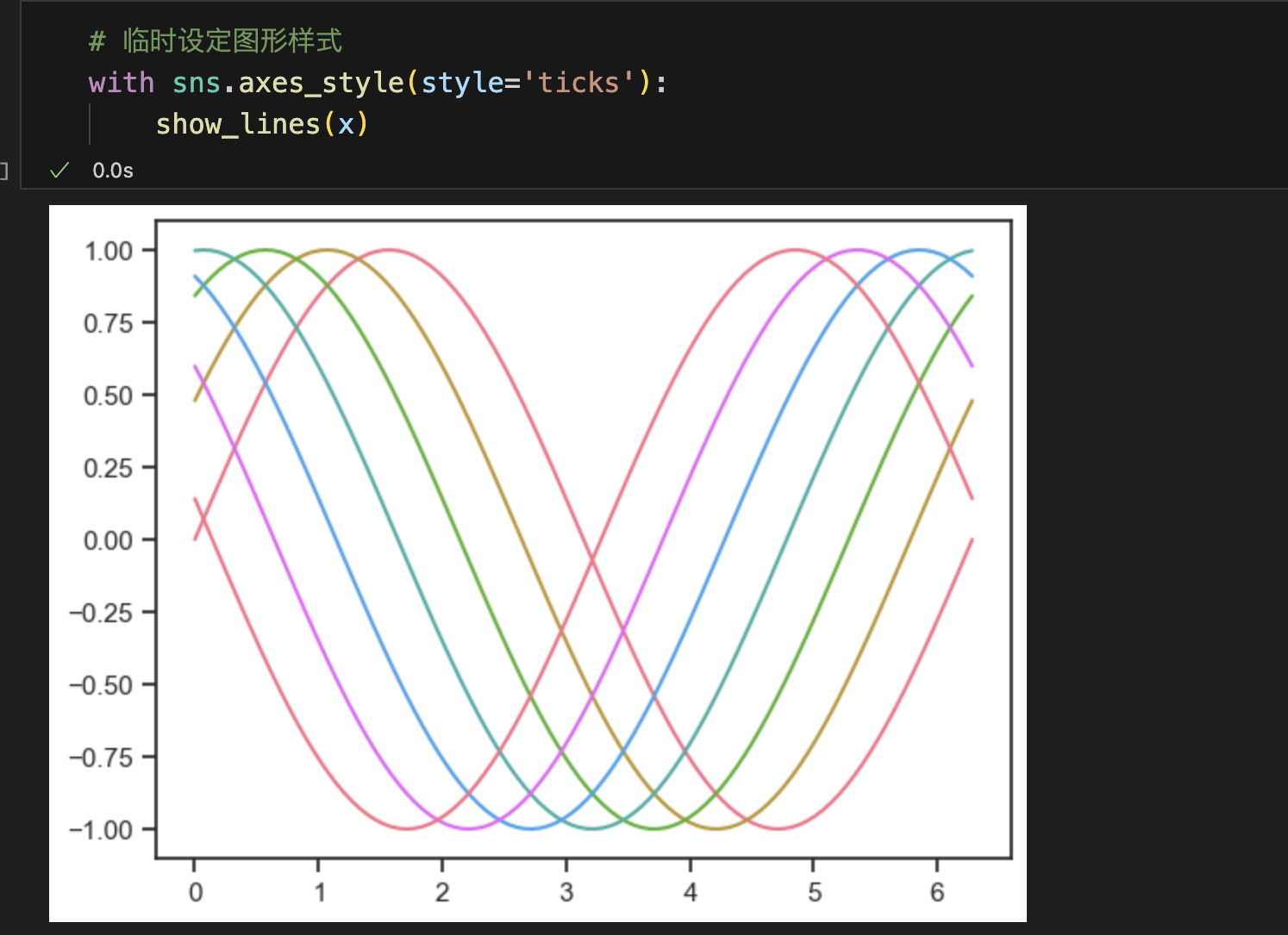
临时设定图形样式
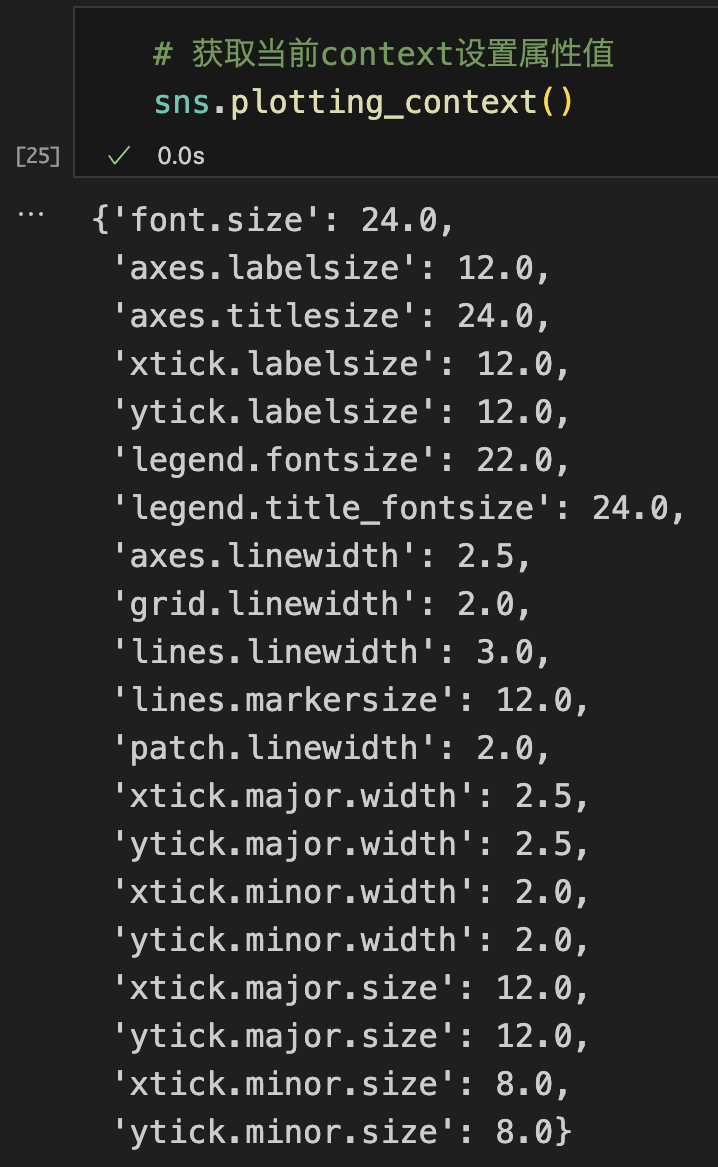
控制线条粗细
- sns.set()可以重置所有设置
- 四种预设,按相对尺寸的顺序(线条越来越粗),分别是paper,notebook, talk, and poster。notebook的样式是默认的。
- sns.plotting_context() 可以获取所有默认设置的属性字典
获取当前context设置属性值
- sns.plotting_context()
使用默认值设置线条粗细
sns.set()使用字典控制绘图元素
# 对context做全局的配置修改
sns.set_context(context='poster', rc={
'axes.labelsize':12.0,
'xtick.labelsize': 12.0,
'ytick.labelsize': 12.0,
})
临时配置
调色板
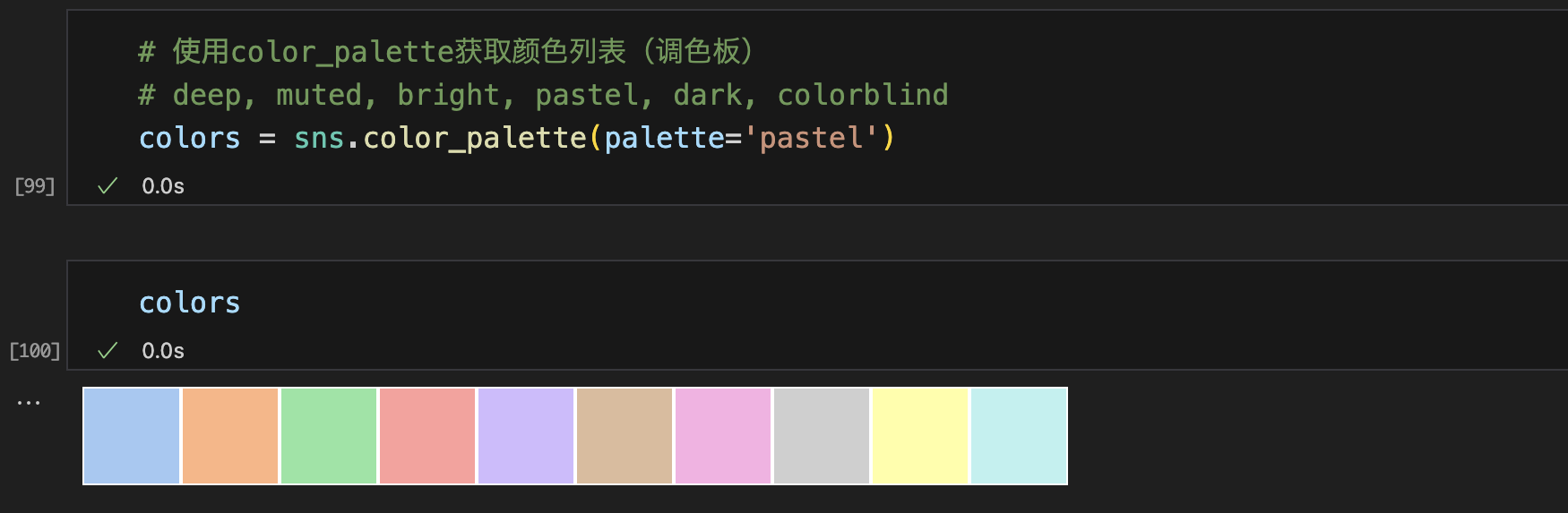
最重要的直接设置调色板的函数就是color_palette()。
这个函数提供了许多(并非所有)在seaborn内生成颜色的方式。并且它可以用于任何函数内部的palette参数设置
color_palette()允许任意的seaborn调色板或matplotlib的颜色映射。它还可以使用任何有效的matplotlib格式指定的颜色列表(RGB元组、十六进制颜色代码或HTML颜色名称)。返回值总是一个RGB元组的列表。
使用color_palette()获取调色板
- 6个主题
分类调色板
分类色板(定性)是在区分没有固定顺序的数据时最好的选择, 类似matplotlib的标准颜色循环
默认颜色主题共有六种不同的变化分别是:deep, muted, pastel, bright, dark, 和 colorblind。类似下面的方式直接传入即可。
圆形调色板
- 分类调色板每个组合只有十个颜色,当不够用时选择圆形调色板
- 你有十个以上的分类要区分时,最简单的方法就是在一个圆形的颜色空间中画出均匀间隔的颜色(这样的色调会保持亮度和饱和度不变)。这是大多数的当他们需要使用比当前默认颜色循环中设置的颜色更多时的默认方案。
hls的颜色
是RGB值的一个简单转换
sns.color_palette(palette='hls',n_colors=数字)
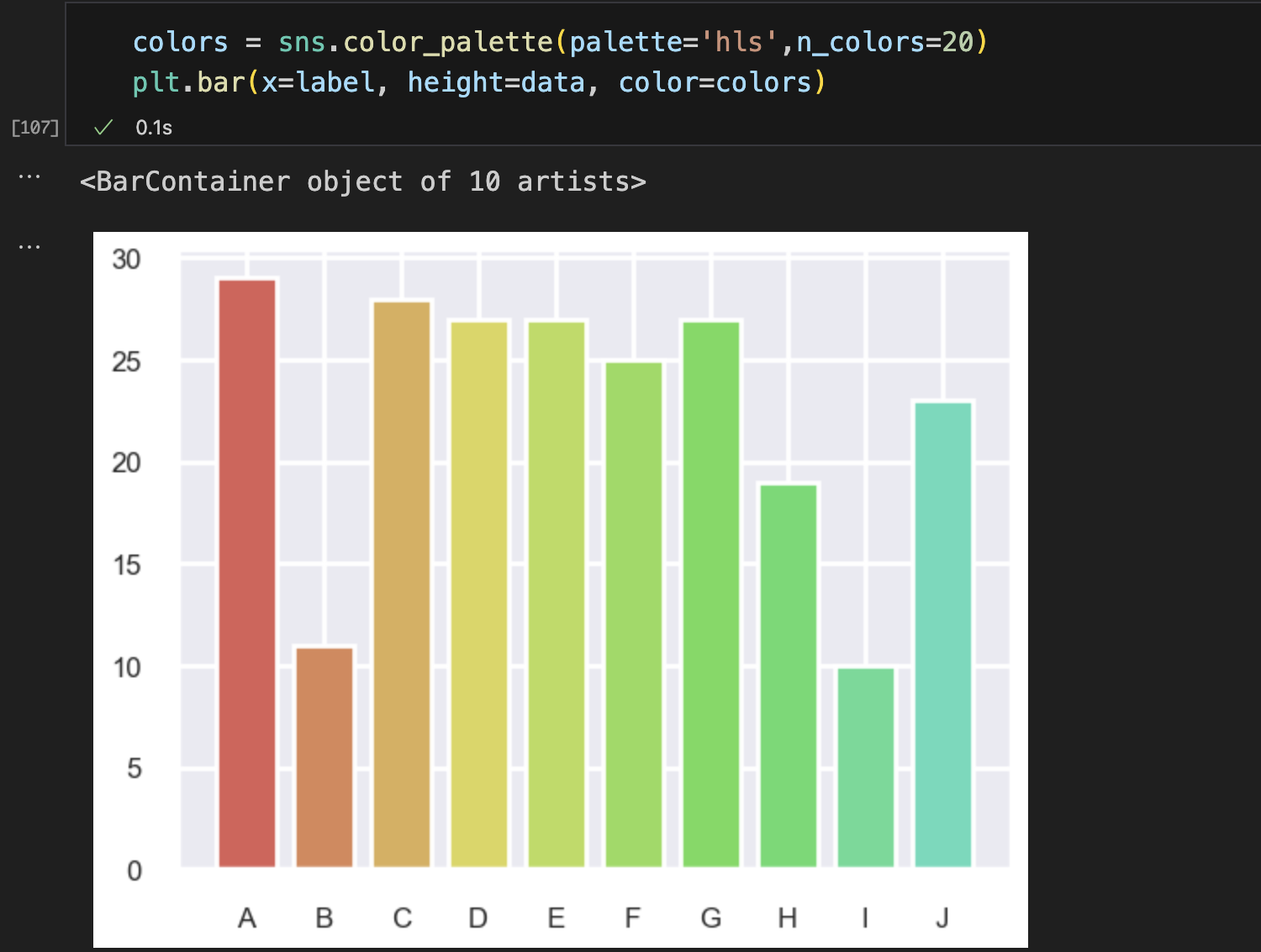
也可以使用hls_palette()函数来控制颜色的亮度和饱和。
l - 亮度 lightness
s - 饱和度 saturation
h - 控制起始颜色的值
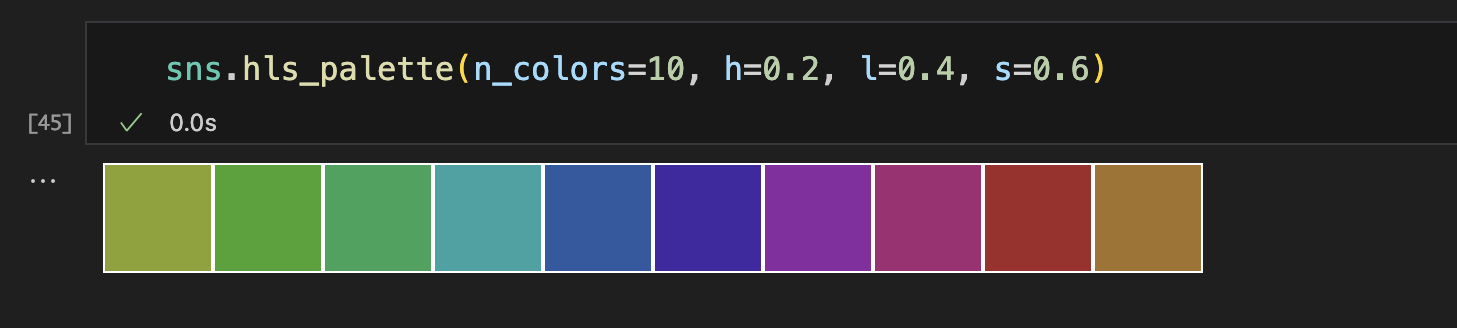
husl颜色
由于人类视觉系统的工作方式,会导致在RGB度量上强度一致的颜色在视觉中并不平衡。比如,我们黄色和绿色是相对较亮的颜色,而蓝色则相对较暗,使得这可能会成为与hls系统一致的一个问题。
为了解决这一问题,seaborn为husl系统提供了一个接口,这也使得选择均匀间隔的色彩变得更加容易,同时保持亮度和饱和度更加一致。
sns.color_palette(palette='husl', n_colors=数字)
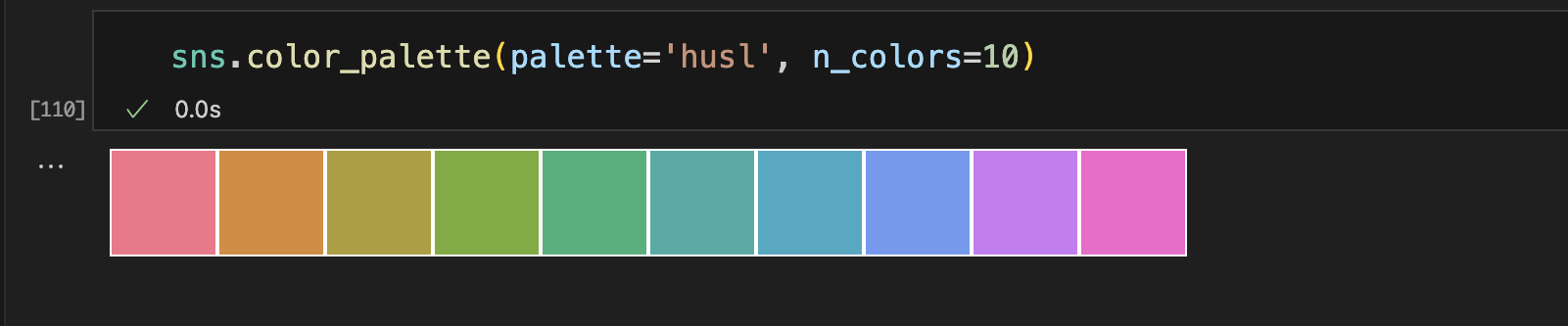
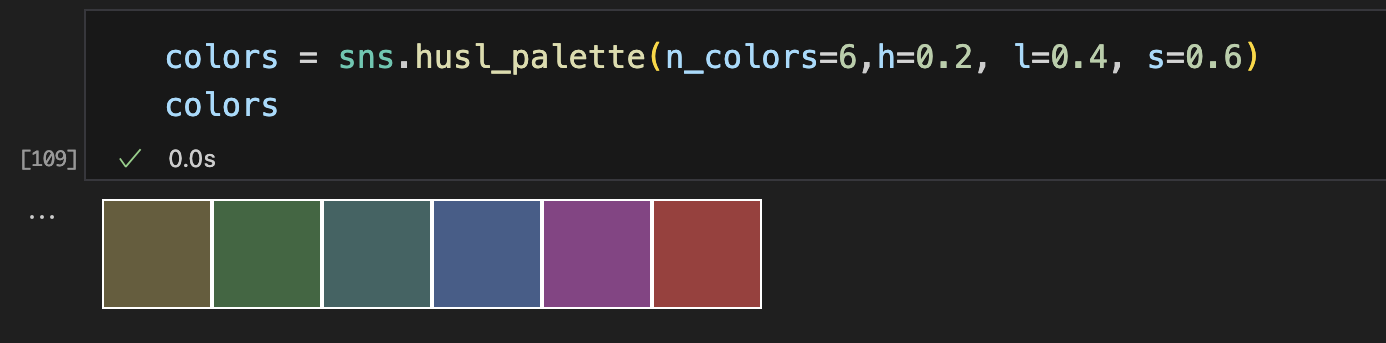
也可以使用husl_palette()函数来控制颜色的亮度和饱和。
l - 亮度 lightness
s - 饱和度 saturation
h - 控制起始颜色的值
启动调色板小工具Color Brewer自定义颜色
使用choose_colorbrewer_palette()函数启动调色板小工具Color Brewer来挑选喜欢的颜色参数
as_cmap 设置颜色范围是离散还是连续
sequential 连续的 渐变色
diverging 发散的 两极分化(表达两端的数据都需要被重视)
qualitative 定性的 分类表示
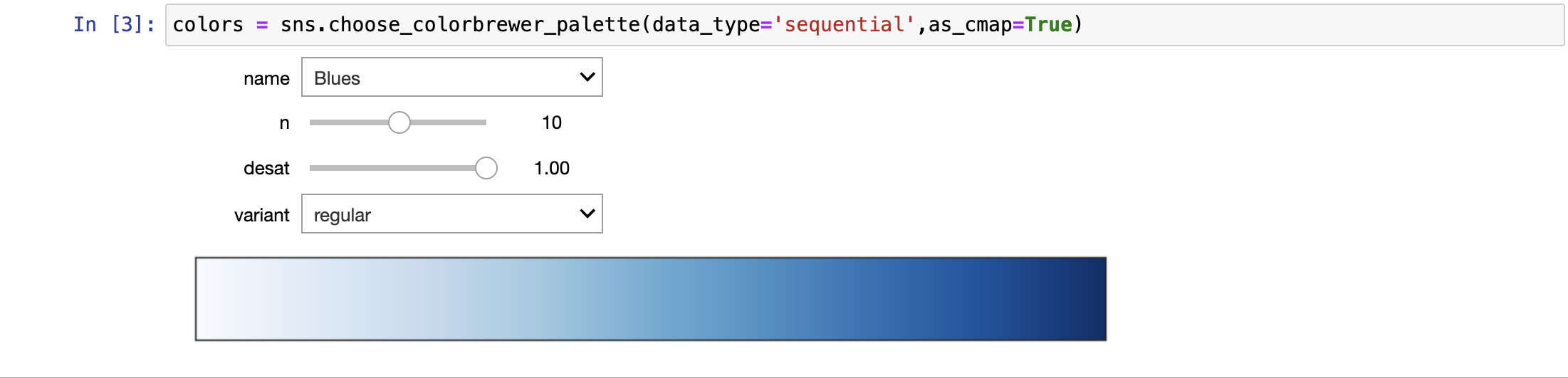
连续调色板
- 这种颜色映射对应的是从相对低价值(无意义)数据到高价值(有意义)的数据范围。
- 比如温度变化、海拔变化等。
- 对于连续的数据,最好是使用那些在色调上相对细微变化的调色板,同时在亮度和饱和度上有很大的变化。这种方法将自然地吸引数据中相对重要的部分
- 强调对比
Color Brewer()函数的连续调色板
如“Blues”,“BuGn_r”,“GnBu_d”,“PuBuGn_d”
颜色中带_r后缀的,表示颜色翻转渐变_
_颜色中带_d后缀的,表示对原颜色进行变暗处理

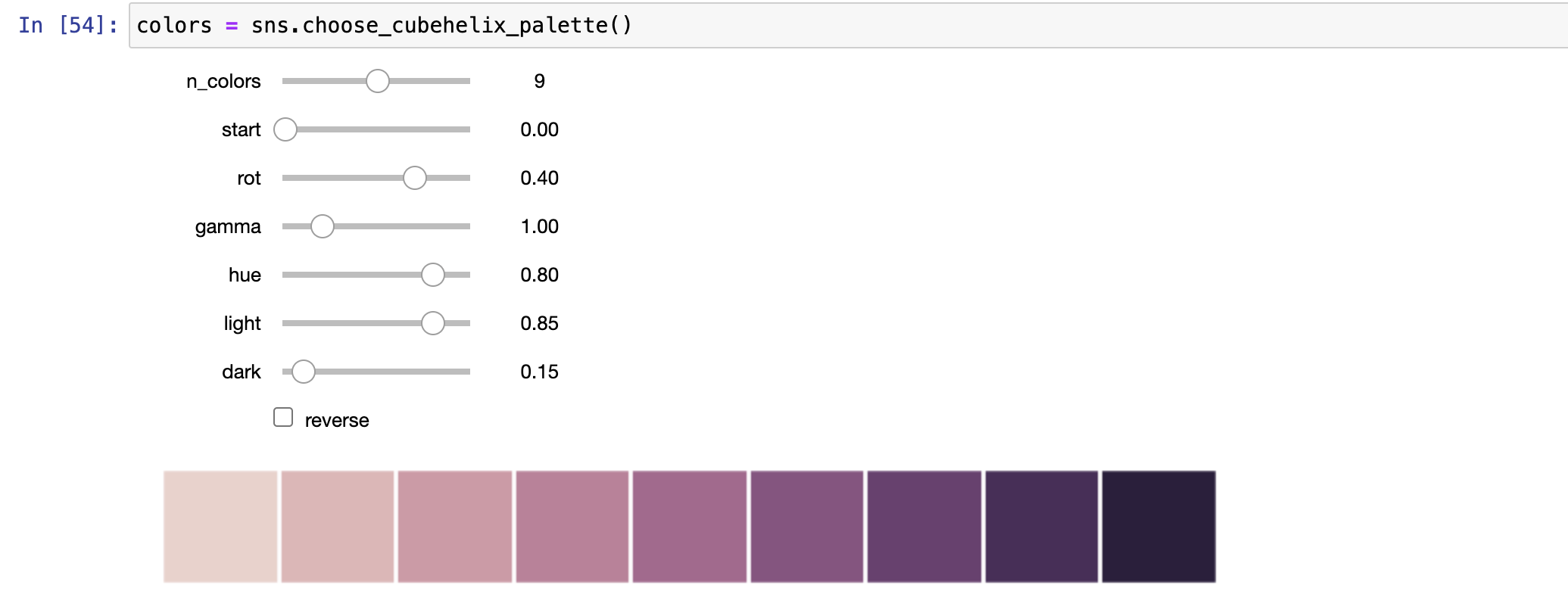
cubehelix_palette()函数的连续调色板
cubehelix调色板系统具有线性增加或降低亮度和色调变化顺序的调色板。
这意味着在你的映射信息会在保存为黑色和白色(为印刷)时或被一个色盲的人浏览时可以得以保留。
Matplotlib拥有一个默认的内置cubehelix版本可供创建:
- sns.color_palette("cubehelix",8)

- seaborn为cubehelix系统添加一个接口使得其可以在各种变化中都保持良好的亮度线性梯度。
- 通过seaborn的cubehelix_palette()函数返回的调色板与matplotlib默认值稍有所不同,它不会在色轮周围旋转或覆盖更广的强度范围。seaborn还改变了排序使得更重要的值显得更暗:
- 可以使用choose_cubehelix_palette调色板插件选择颜色
使用light_palette() 和dark_palette()调用定制连续调色板
- 这里还有一个更简单的连续调色板的使用方式,就是调用light_palette() 和dark_palette(),这与一个单一颜色和种子产生的从亮到暗的饱和度的调色板。
- 使用html颜色设置调色板
- sns.dark_palette(color="green")

- 把使用插件调整过颜色值保留下来
- dark = sns.choose_dark_palette(as_cmap=False)

- 使用连续值来映射颜色
- cmap = sns.light_palette("blue", as_cmap=True)

离散调色板(发散)(热力图颜色设置)
- 用于可能无论大的低的值和大的高的值都非常重要的数据。数据中通常有一个定义良好的中点。例如,如果你正在绘制温度变化从基线值,最好使用不同色图显示相对降低和相对增加面积的地区。
- 选择离散色板的规则类似于顺序色板,除了你想满足一个强调的颜色中点以及用不同起始颜色的两个相对微妙的变化。同样重要的是,起始值的亮度和饱和度是相同的。
- 同样重要的是要强调,应该避免使用红色和绿色,因为大量的潜在观众将无法分辨它们。
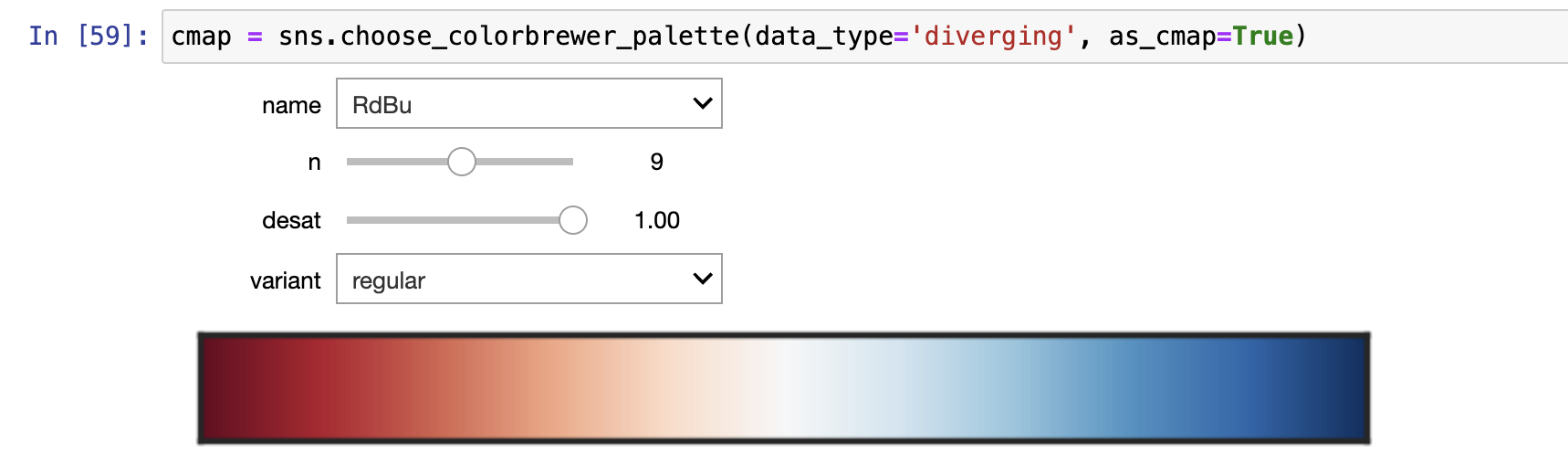
sns.color_palette(palette=)
- Color Brewer颜色字典里的颜色映射值,例如BrBG、RdBu_r等

- matplotlib中建立的明智的选择是coolwarm面板。
sns.color_palette("coolwarm")- 注意 :这个颜色映射在中间值和极端之间并没有太大的对比。

- 用diverging_palette()使用定制离散色板
- 也可以使用海运功能diverging_palette()为离散的数据创建一个定制的颜色映射。(也有一个类似配套的互动工具:choose_diverging_palette())。该函数使用husl颜色系统的离散色板。你需随意传递两种颜色,并设定明度和饱和度的端点。函数将使用husl的端点值及由此产生的中间值进行均衡
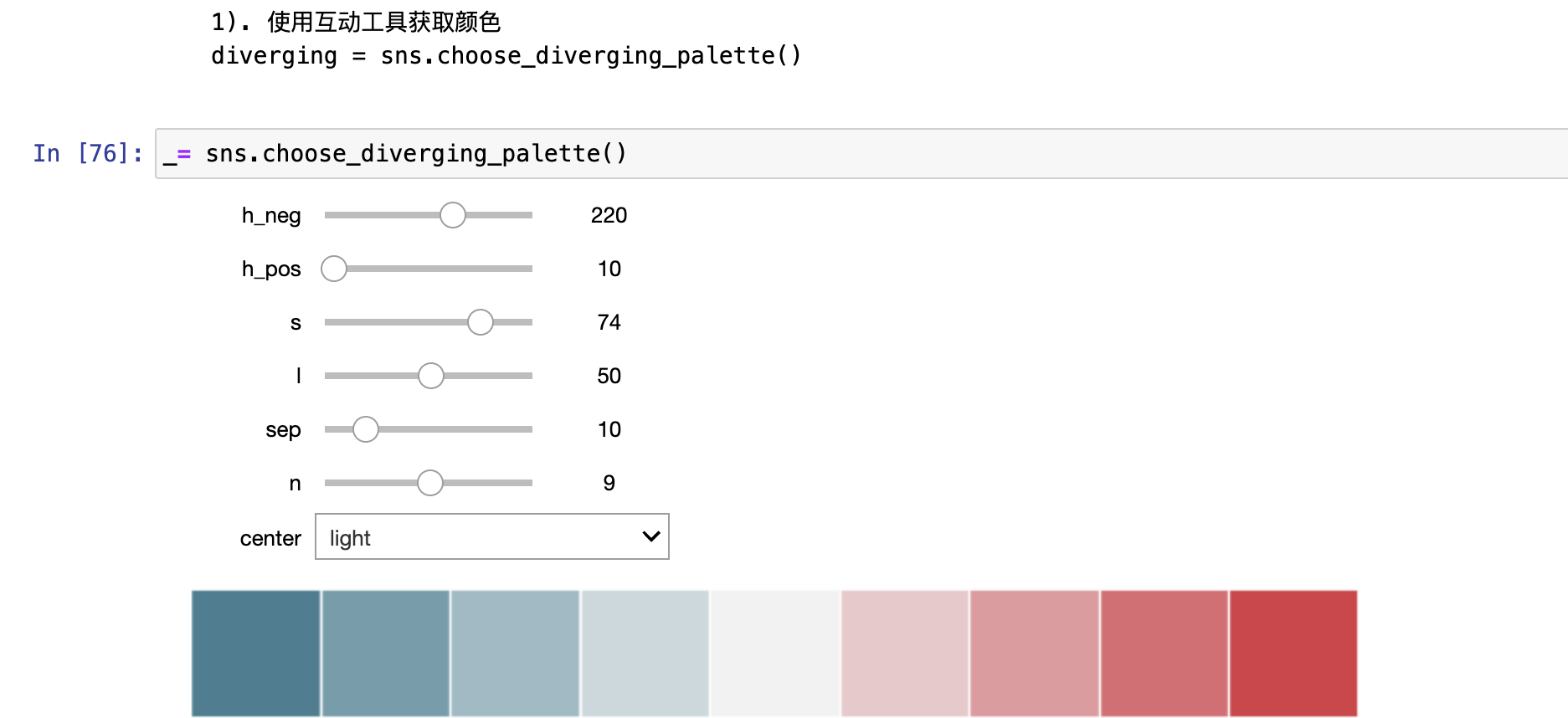
- 4.用set_palette()更改色变的默认值
- color_palette() 函数有一个名为set_palette()的配套。
- set_palette()接受与color_palette()相同的参数,但是它会更改默认的matplotlib参数,以便成为所有的调色板配置。
- sns.set_palette("husl")
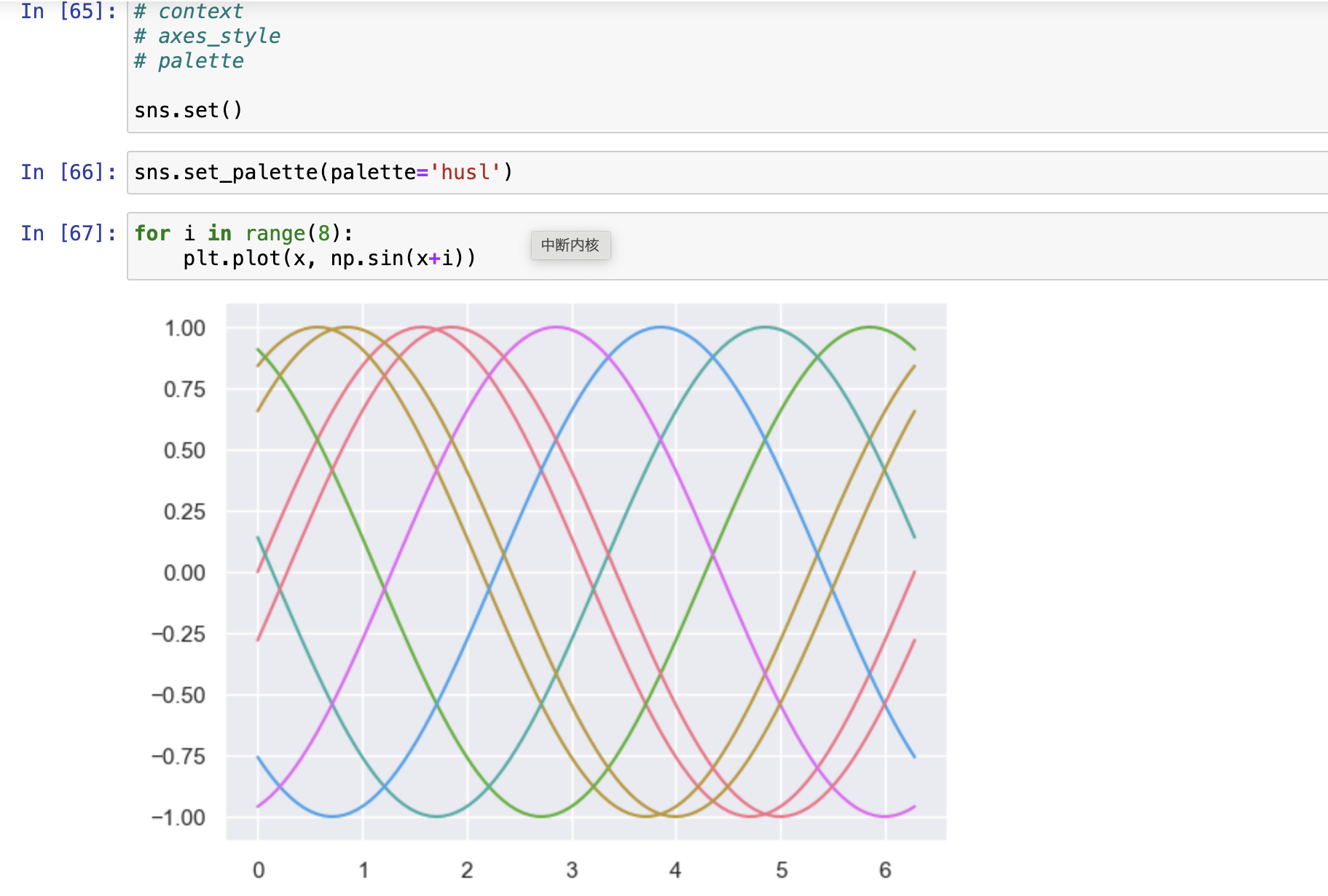
Summary
简单常用色彩总结:
- 分类:hls husl Paired Set1~Set3(色调不同)
- 连续:Blues[蓝s,颜色+s] BuGn[蓝绿] cubehelix(同色系渐变)
- 离散:BrBG[棕绿] RdBu[红蓝] coolwarm[冷暖](双色对称)
seaborn常用图像绘制
使用sns.load_dataset() 加载数据集
searborn提供了很多实验数据集,查看数据集有哪些可以参考如下网址:
https://github.com/mwaskom/seaborn-data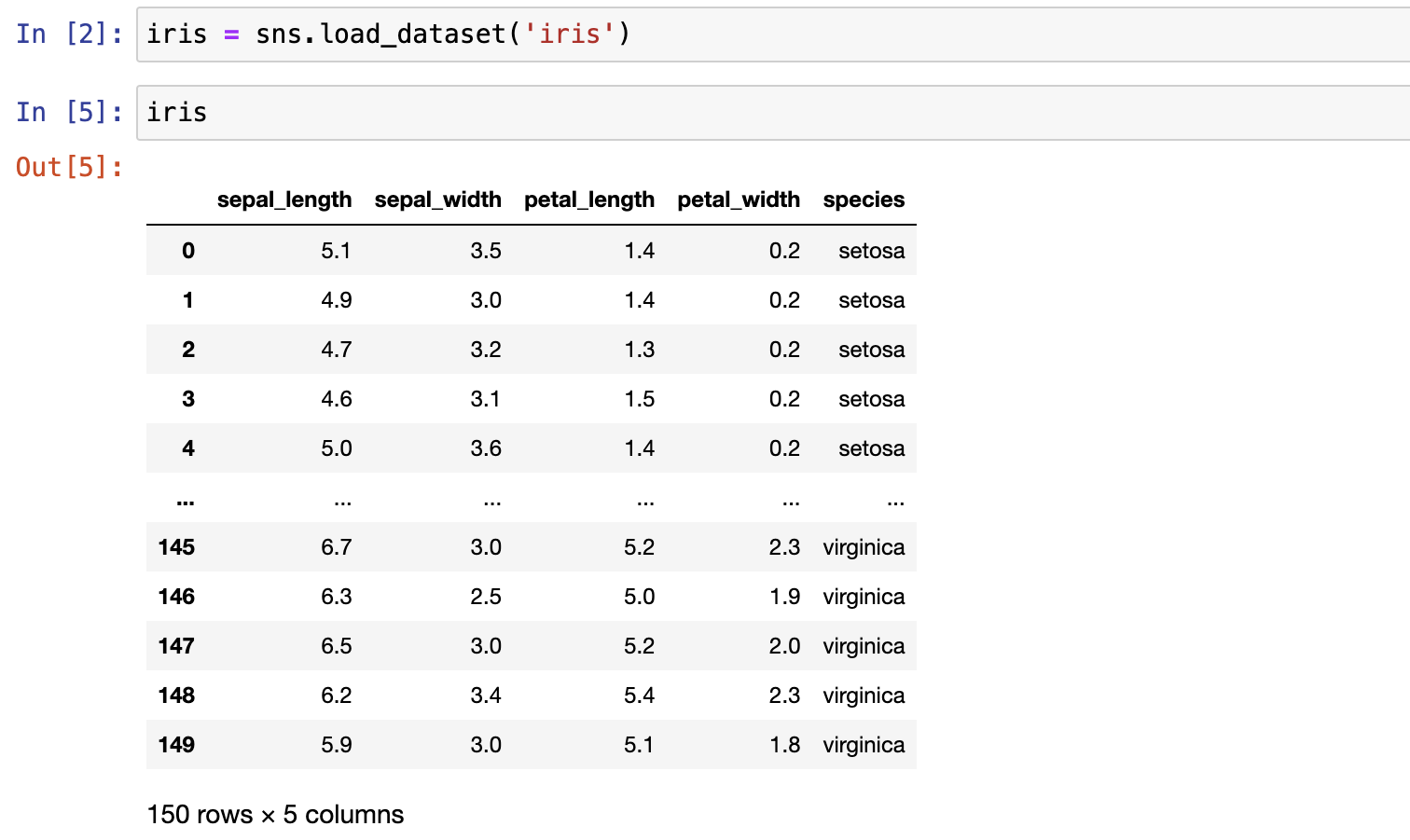
普通2D图像
通用参数:
- x,y: 要展示的数据,如果是DataFrame,可以设置列标签
- data: 数据的来源,通常是一个DataFrame
- hue: 分组因子, 用于颜色映射的列
- palette: 用于颜色映射的调色板
- order: 排序的序列.例如 order = ['Dinner', 'Lunch']
- hue_order: 颜色映射的序列, 例如hue_order = ["setosa","virginica"]
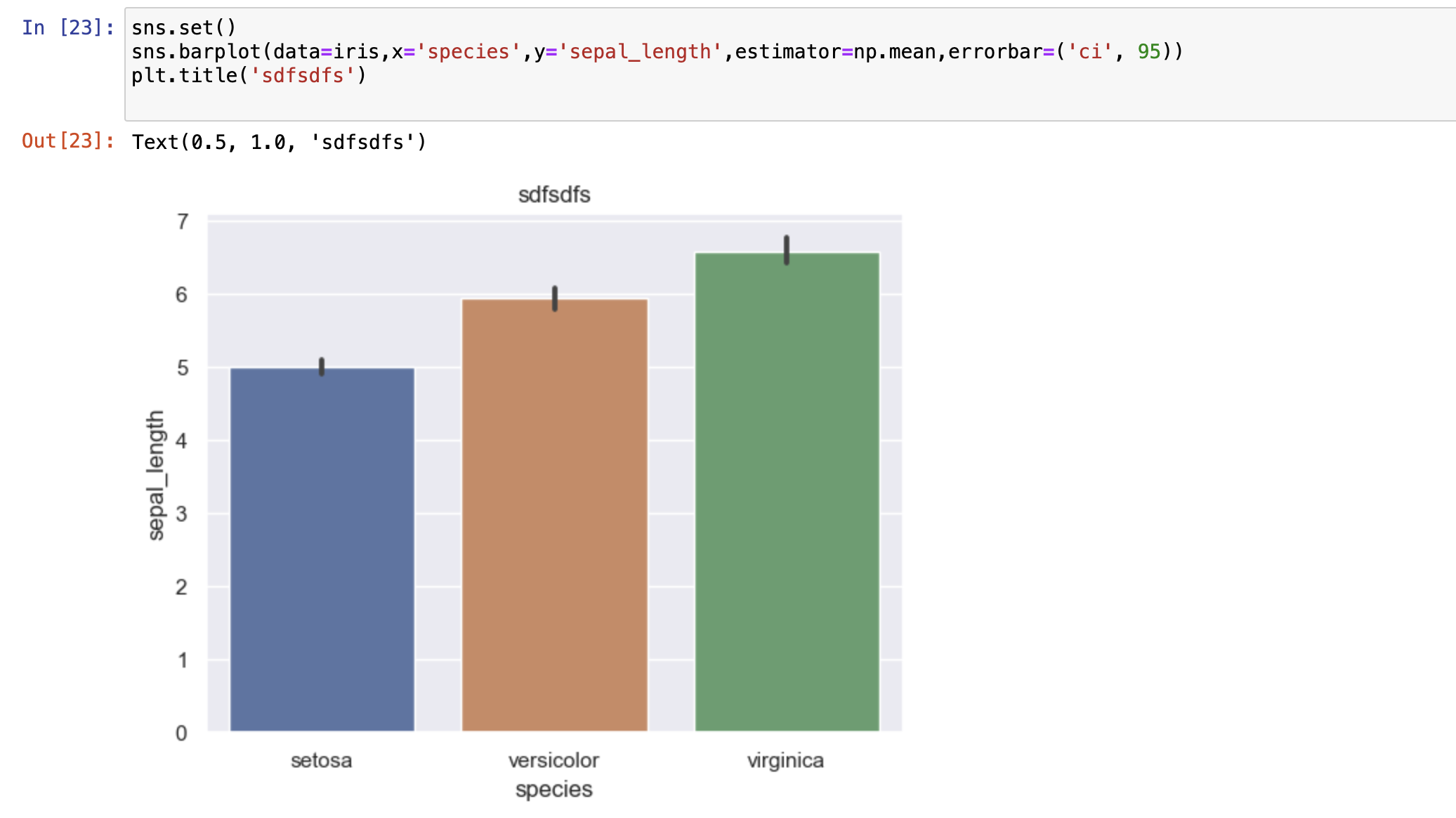
条形图
用于比较多组数据之间的大小
sns.barplot()
x,y有一个是离散字段,有限的数量
参数说明:
- estimator: 统计参数默认为 np.mean,可自定义: np.sum, np.count_nonzero, np.median...
- palette: 主题的颜色 palette = 'Blues_d'
- ci: 置信水平 http://www.360doc.com/content/18/0317/16/15033922_737796626.shtml
举个栗子:
- 图一是用matplotlib分组之后求平均画的图,麻烦
- 图二是seaborn 画的,简单
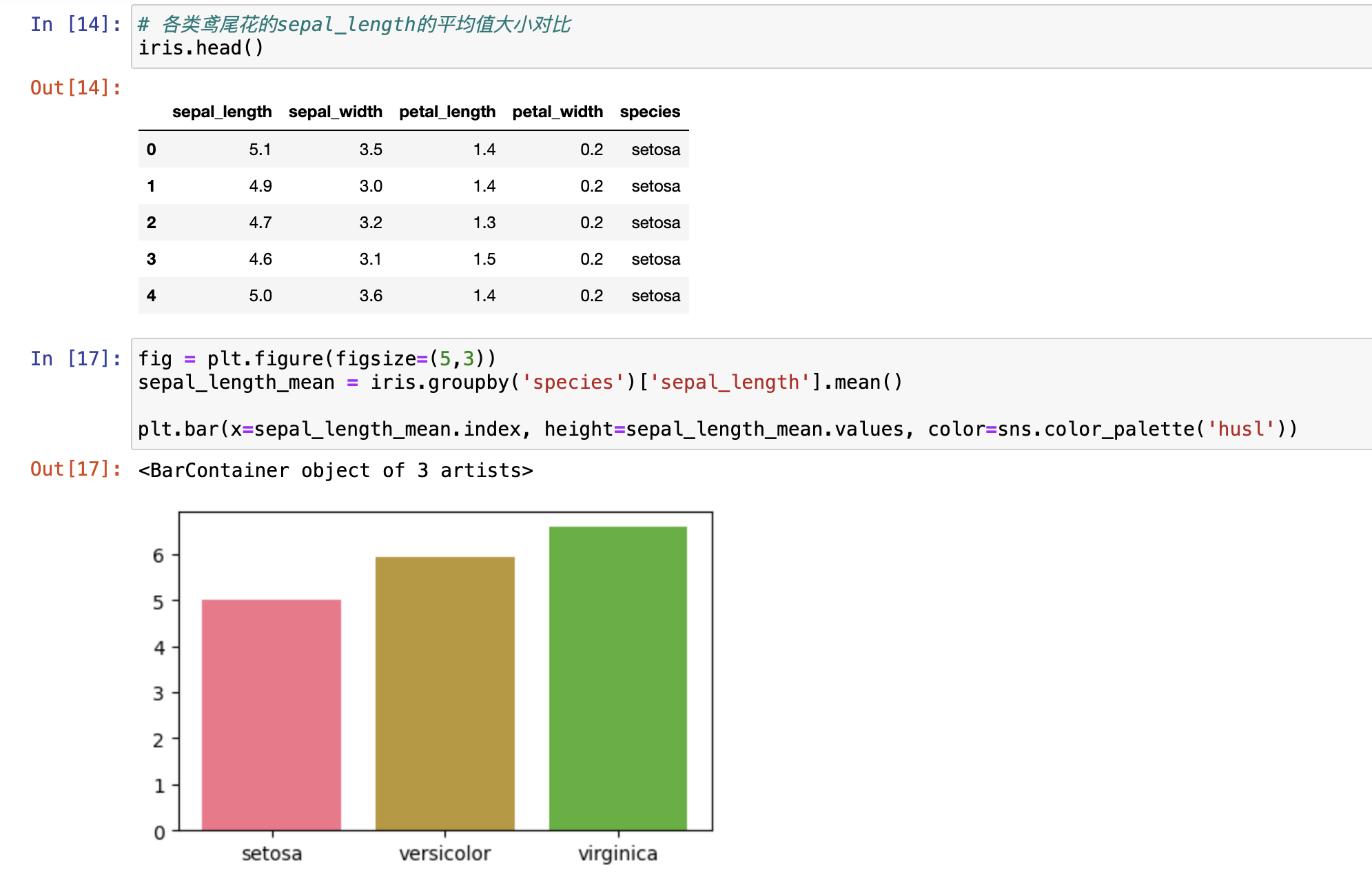
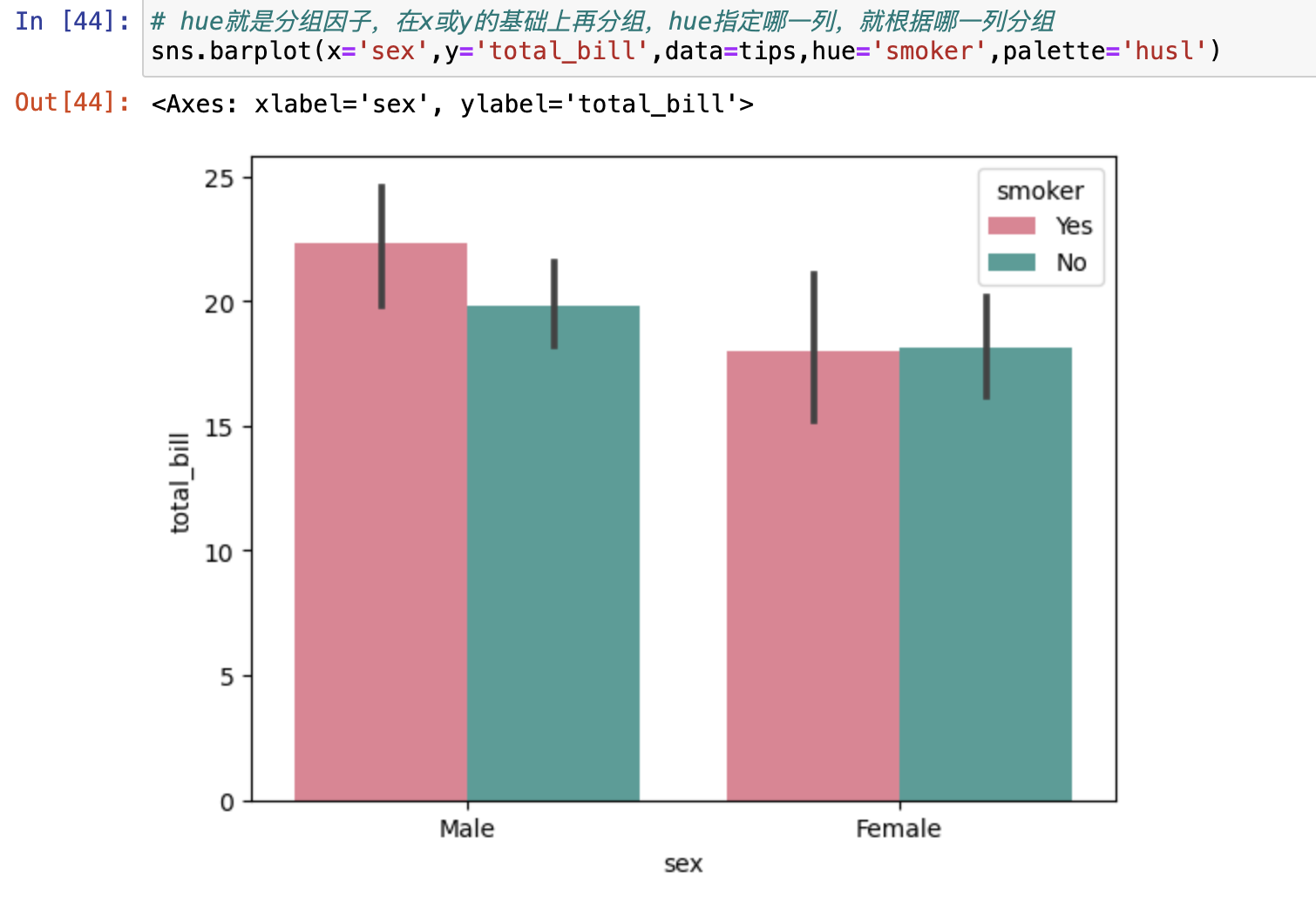
- hue就是分组因子,在x或y的基础上再分组,hue指定哪一列,就根据哪一列分组
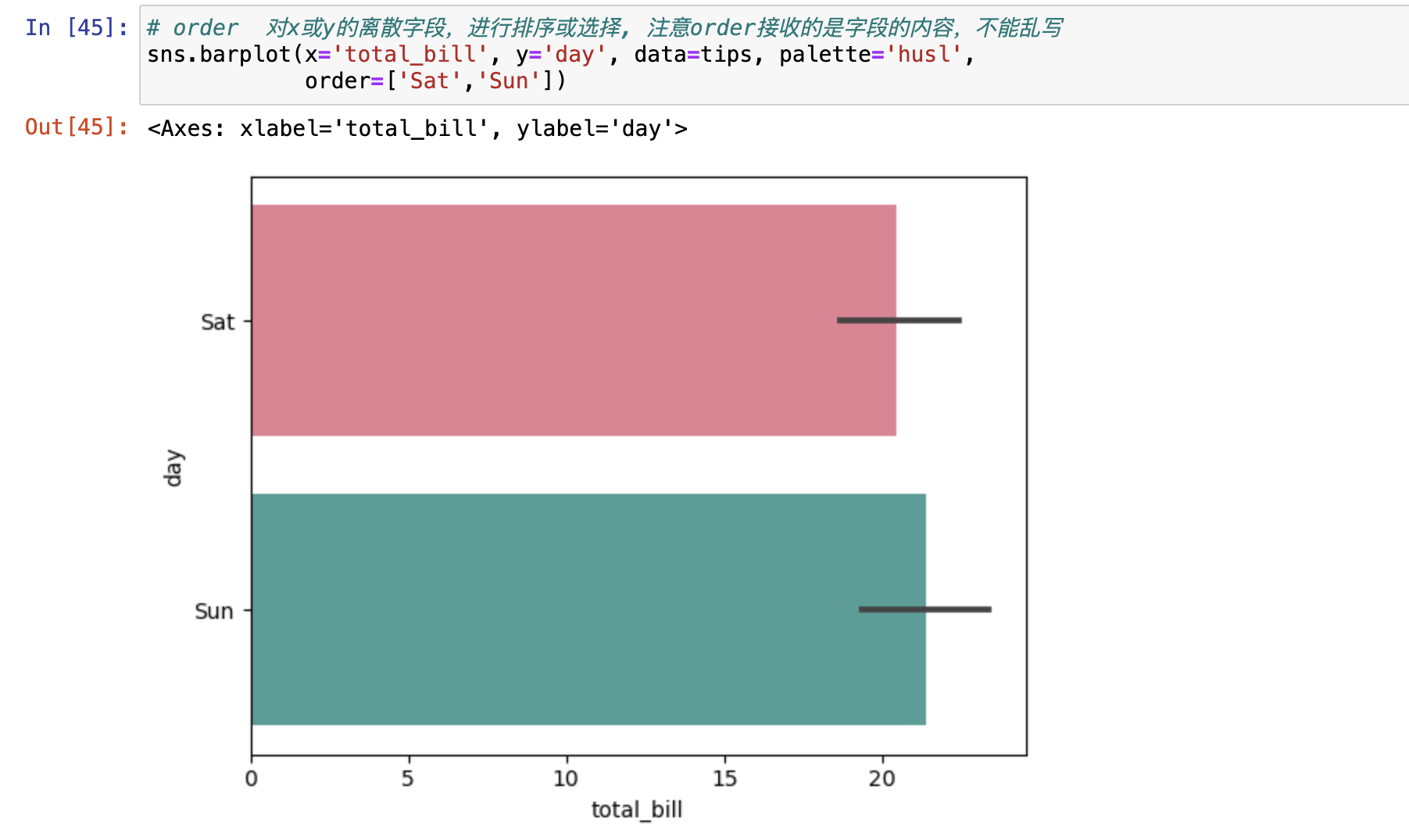
- order : 对x或y的离散字段,进行排序或选择, 注意order接收的是字段的内容,不能乱写
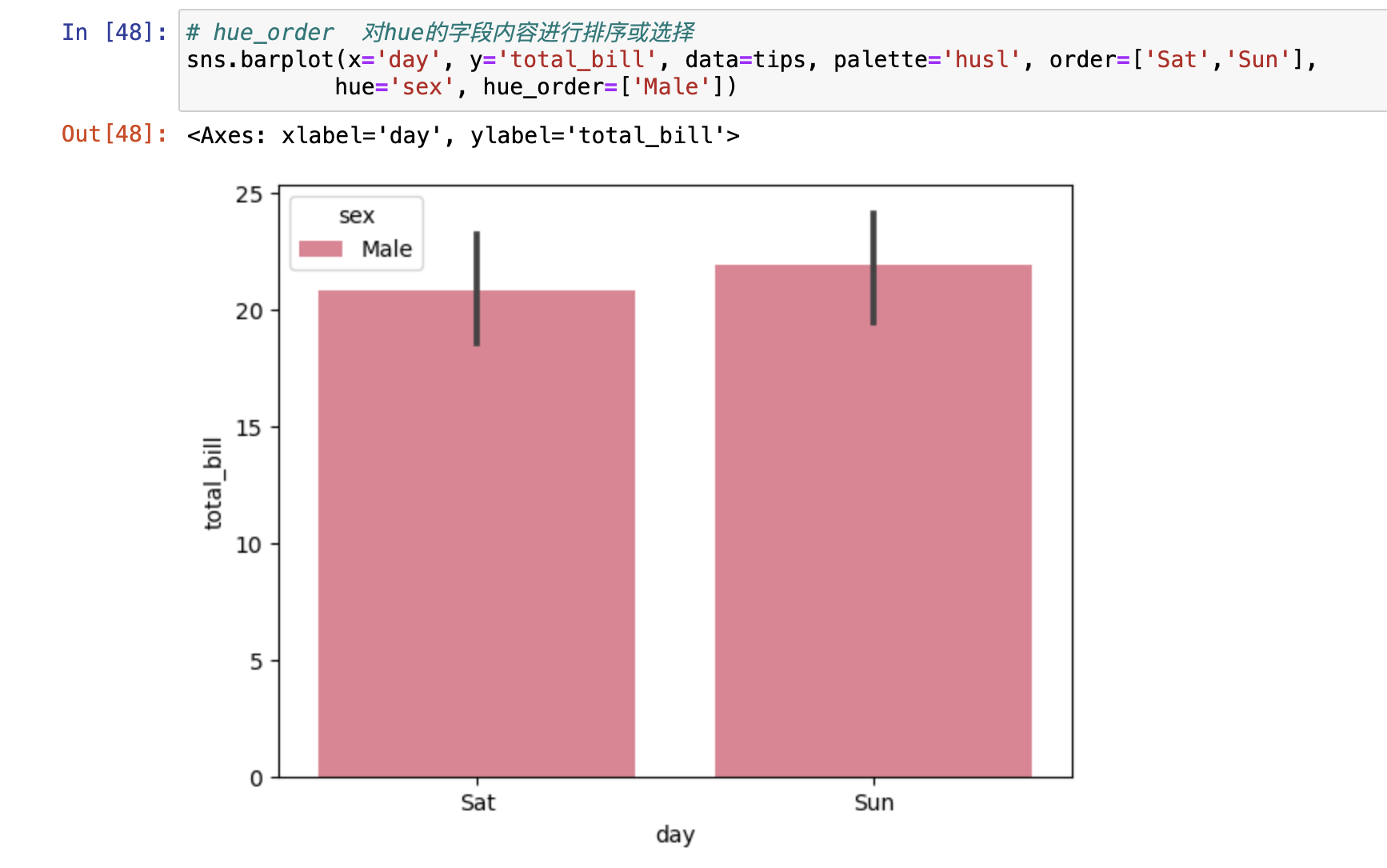
- hue_order 对hue的字段内容进行排序或选择
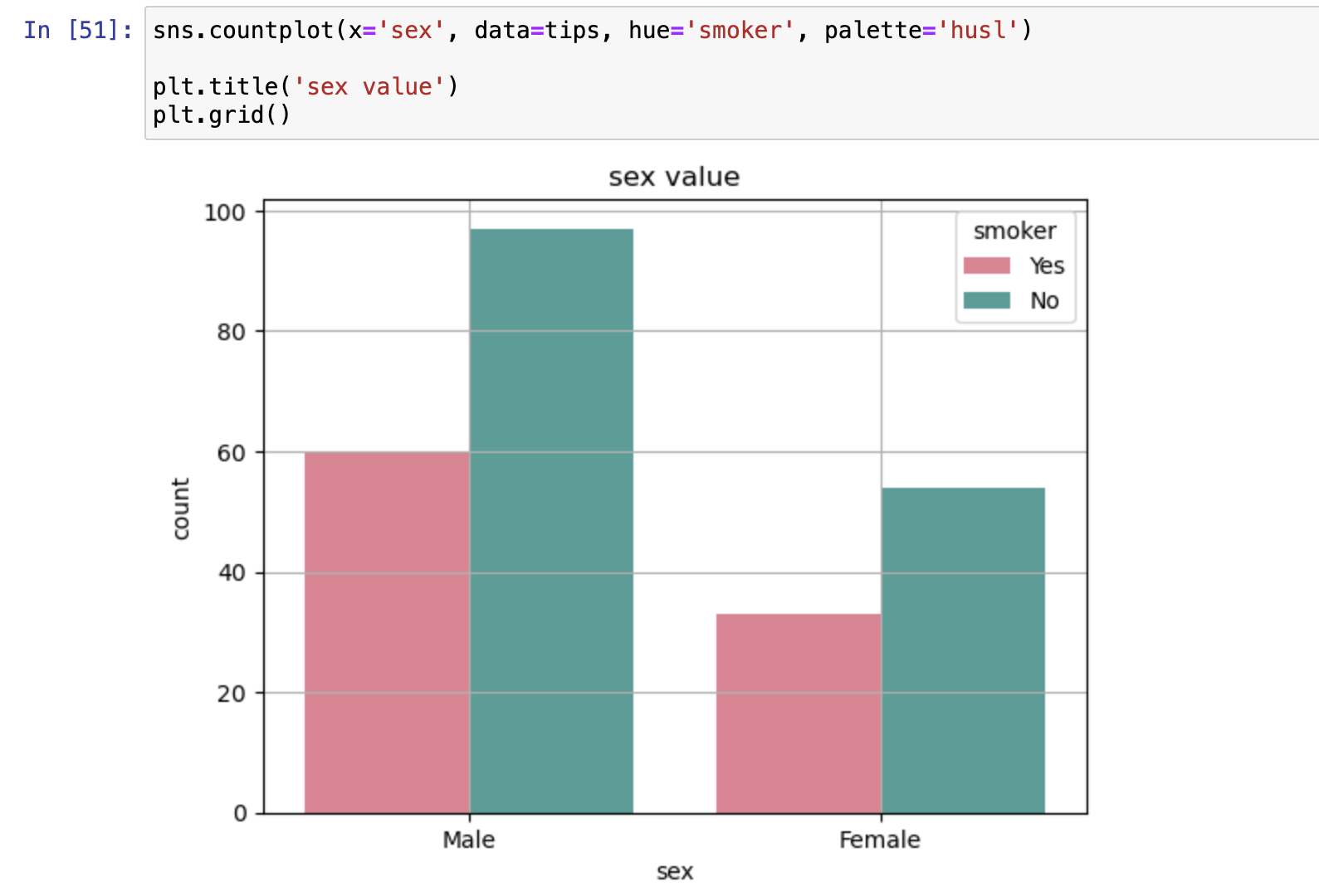
计数条形图
- 统计数据出现次数
- 统计一个字段出现的频数
- sns.countplot()
- eg.按性别统计titanic号中幸存者数量
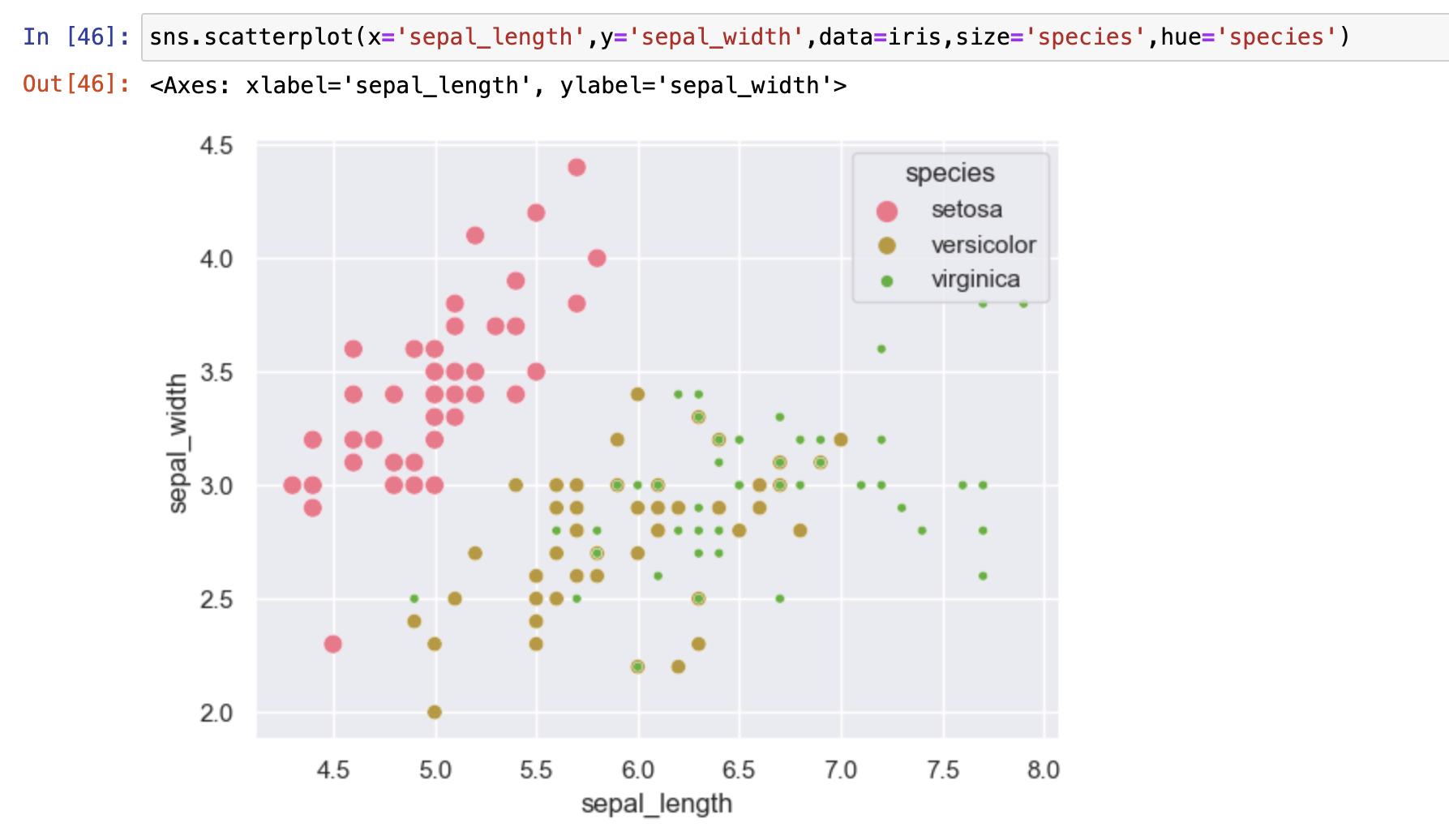
### 标准散点图
查看两组数据对应关系
sns.scatterplot()
sns.stripplot()
散点图只处理连续字段和连续字段的关系
不能展示离散字段和连续字段之间关系,不是不能而是没意义
想查看一种变量的分布形态,要使用箱线图或者是直方图或琴图等

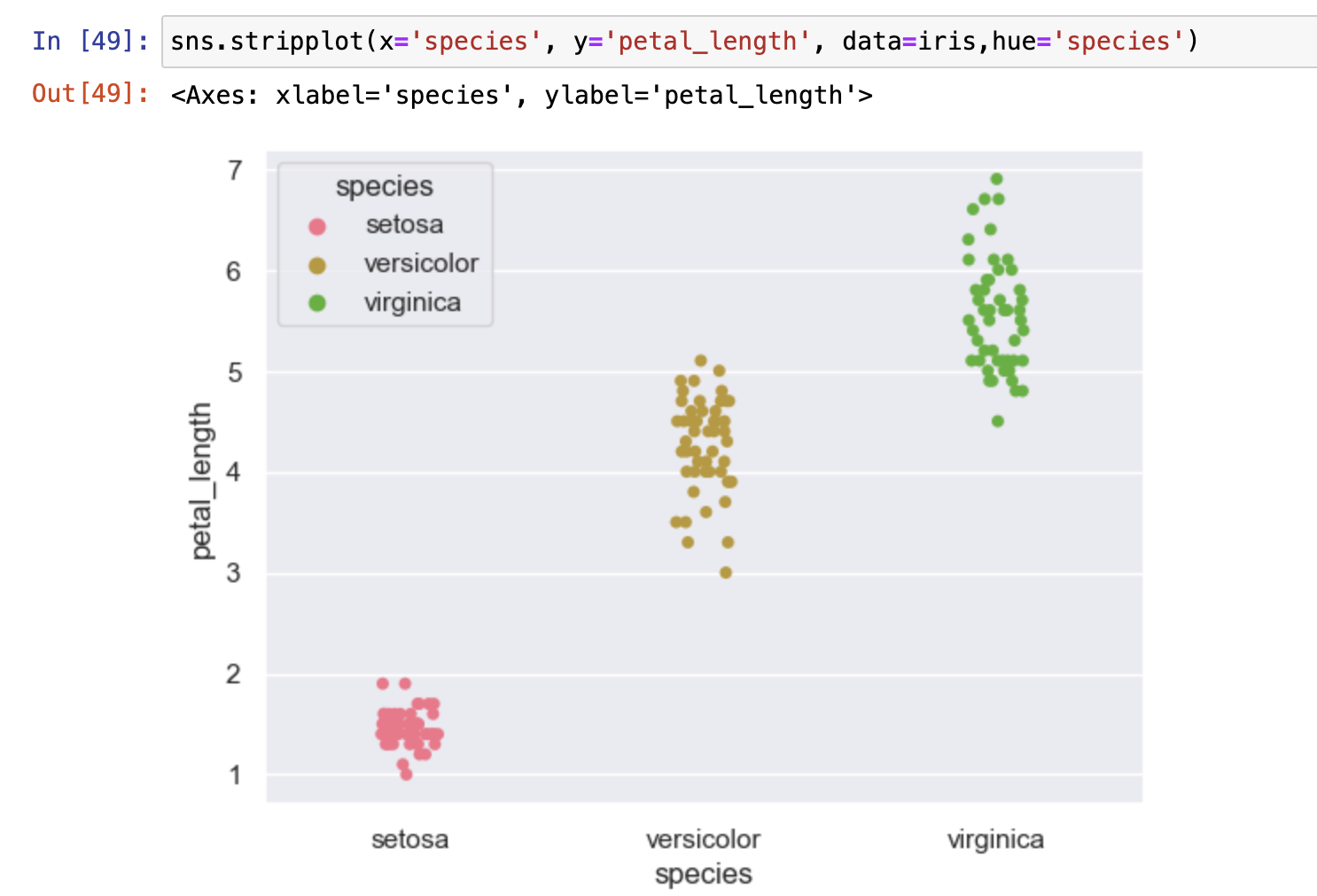
分布散点图
- 用于展示离散字段和连续字段的数据分布形态
- sns.stripplot()
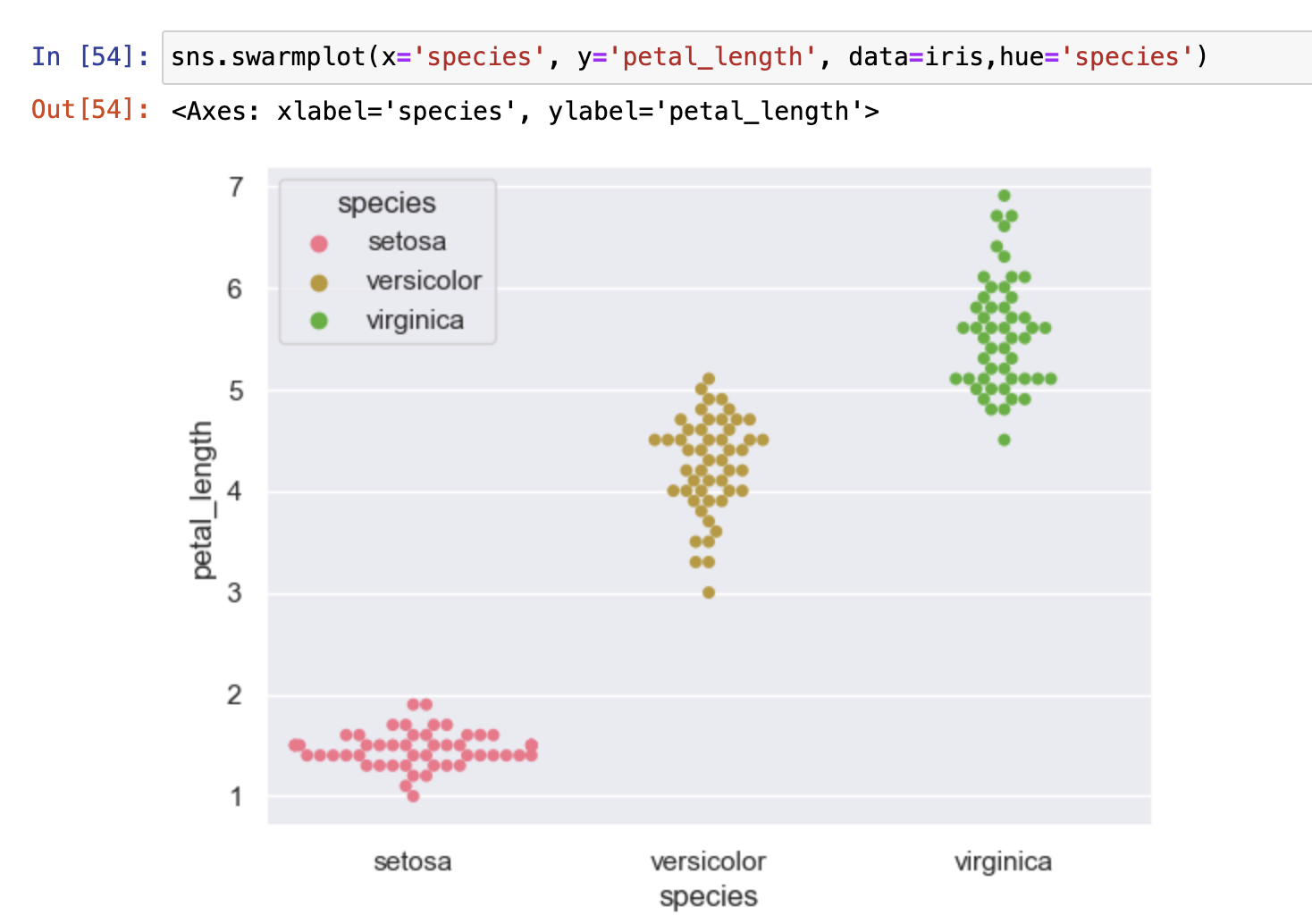
分布蜂群图
- Sis.swarmplot()
- 用于展示离散字段和连续字段的数据分布形态
- 与stripplot()的区别就是点不重叠
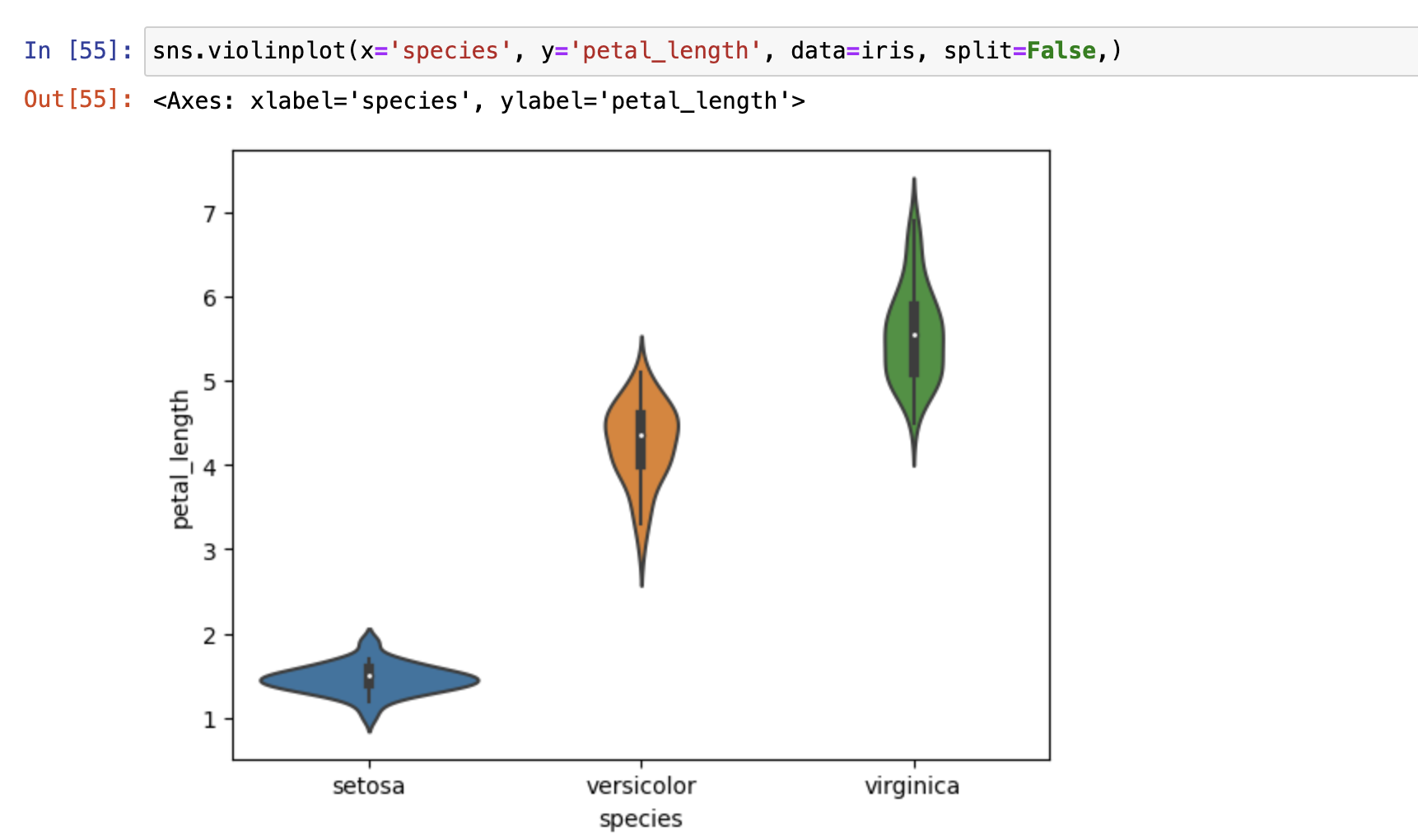
小提琴图
- 用于查看数据分布情况
- sns.violinplot()
- 有分裂特性
- 使用分裂特性时,一般会和swarmplot一起使用
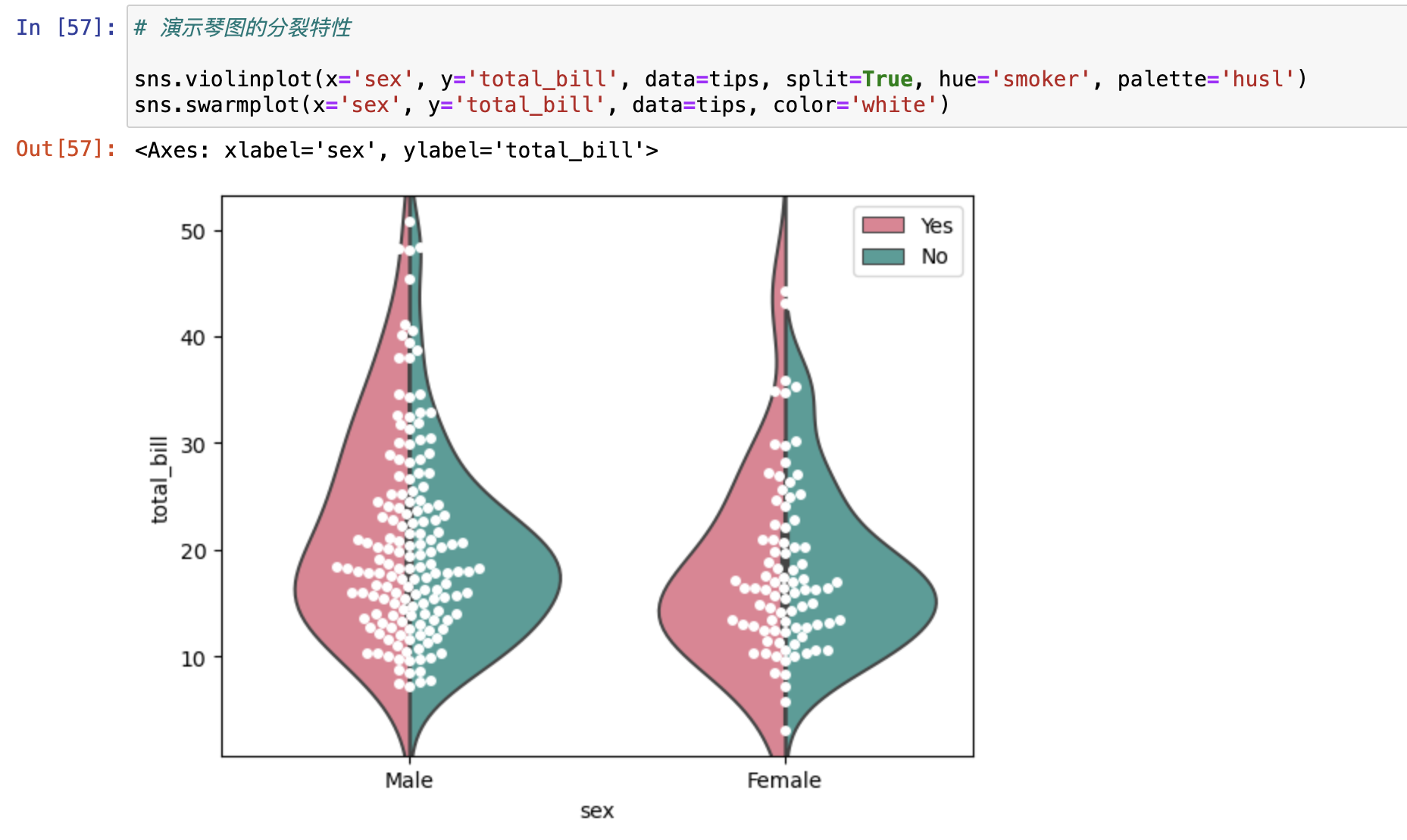
箱线图
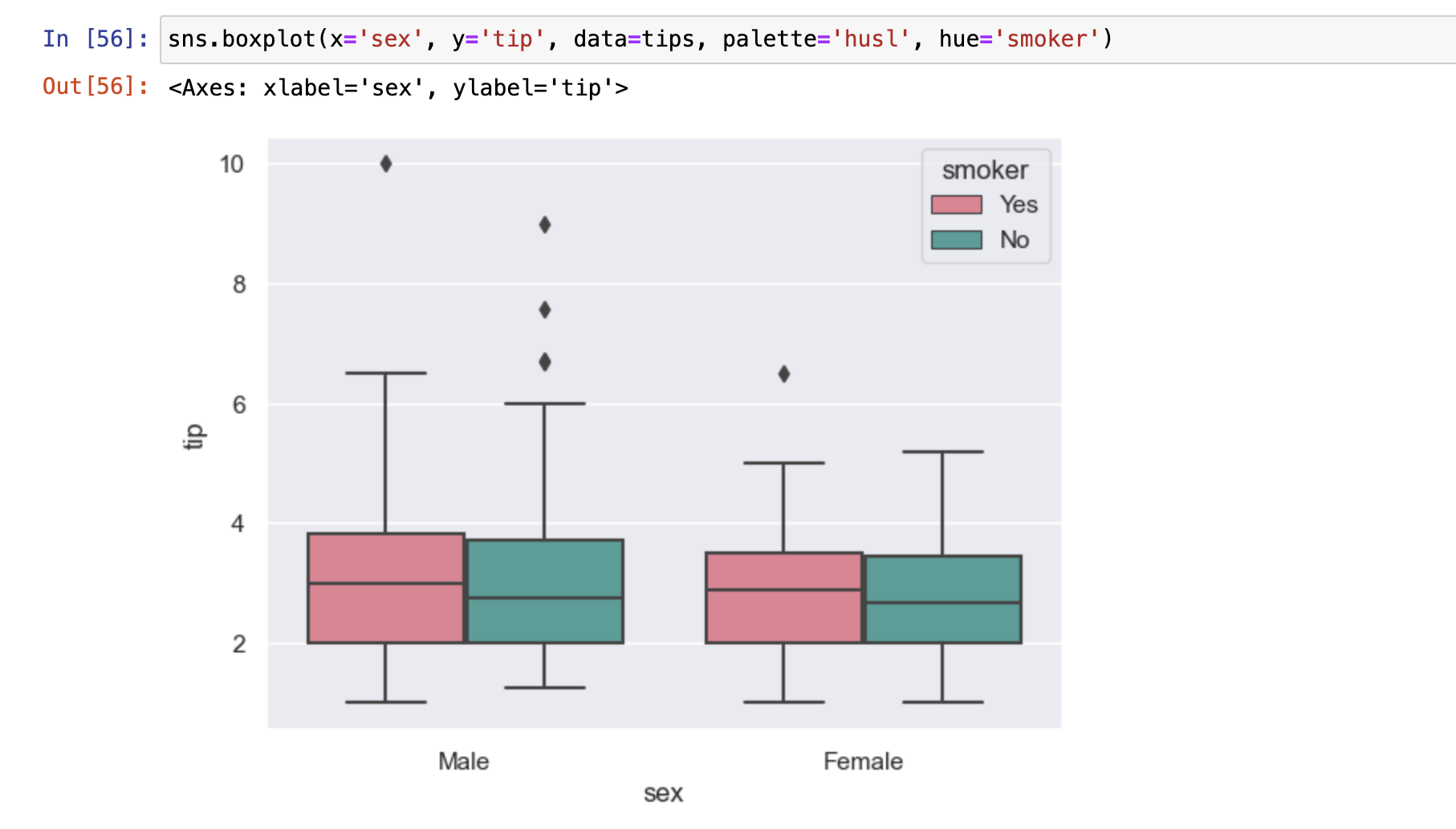
- 检验连续数据是否存在离群点,以及数据分布的范围(4分位数)
- sns.boxplot()
- 可以配合结合sns.swarmplot()函数使用
参数说明
- y: 需要判断的数据序列(连续型数据)
- x: 分类的标签的数据(离散型数据)
- palette: 调色板...Set1, Set2, Set3
- linwidth: 线宽(2.5相当于加粗的线)
- orient = 'h' 方向
- whis 参数设定是否显示箱线图的离群点, whis = np.inf 表示不显示
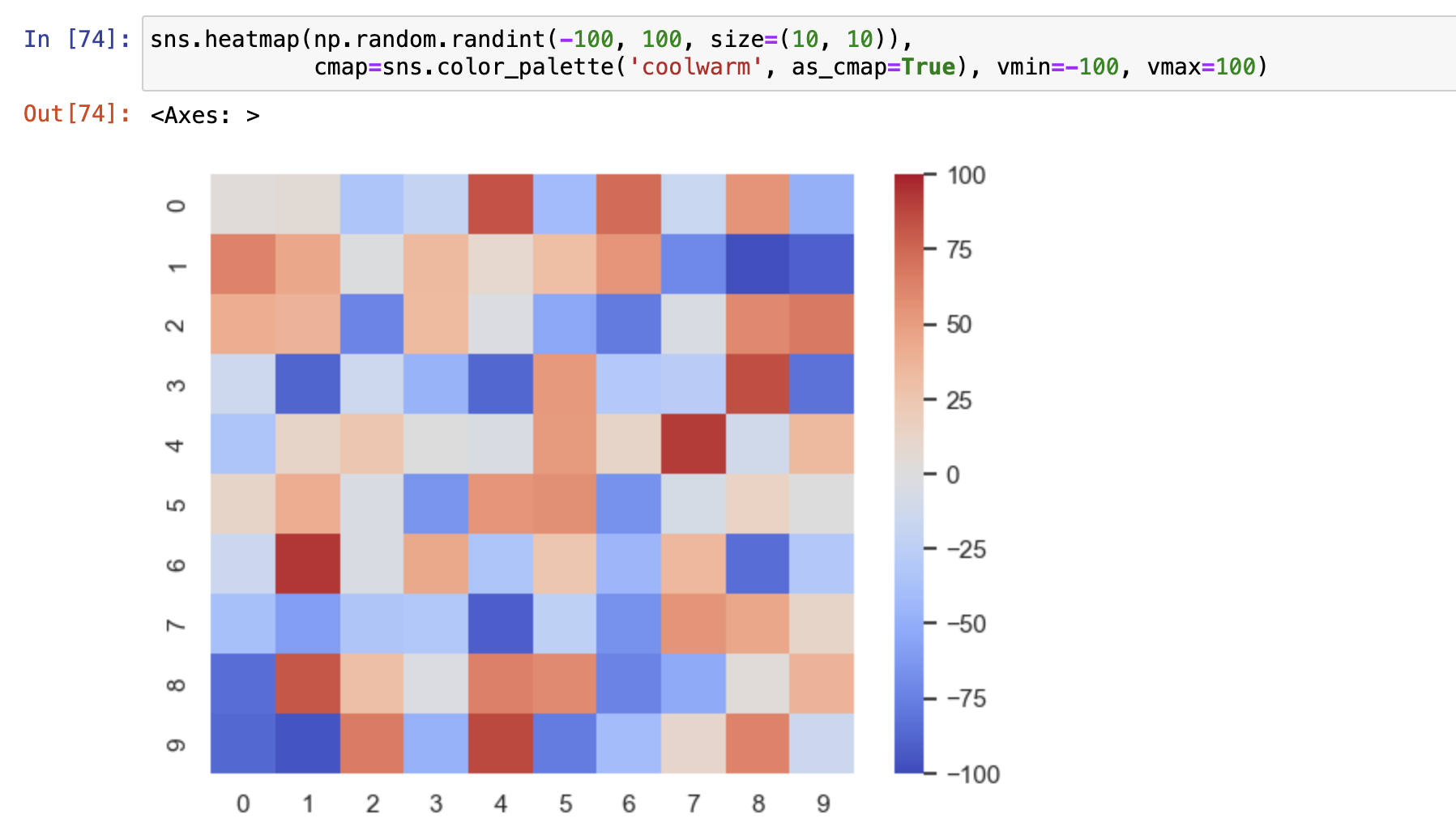
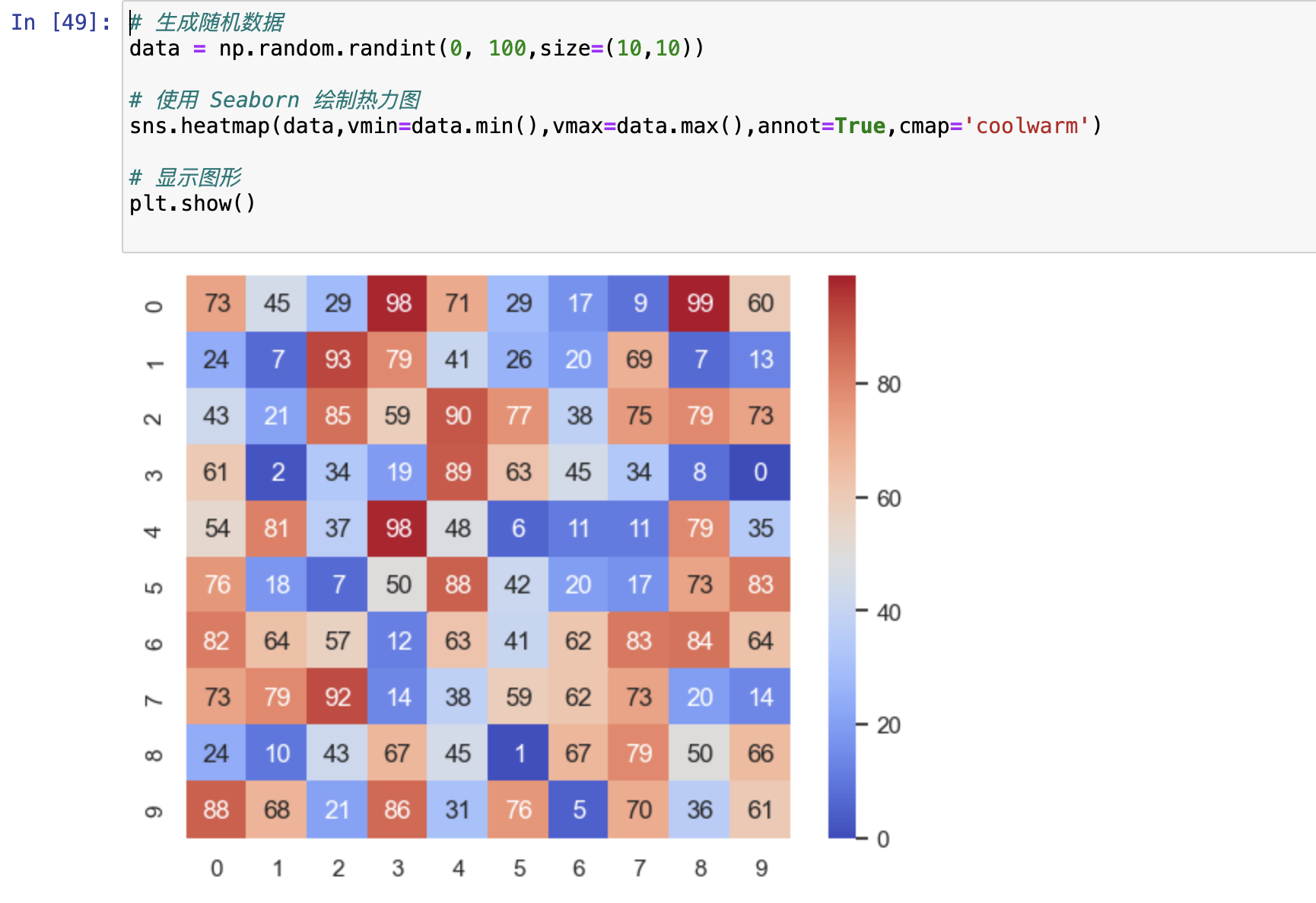
热力图
sns.heatmap(data=data, annot=True)
基本就俩情况:
- 重点关注一端极值
- 重点关注两端极值
应用场景:相关性分析
参数说明:
- vmin颜色值映射的最小值
- vmax颜色值映射的最大值
- cbar:每个变量的颜色棒是否显示
- annot = True 将数值显示到图上
重点关注一端极值
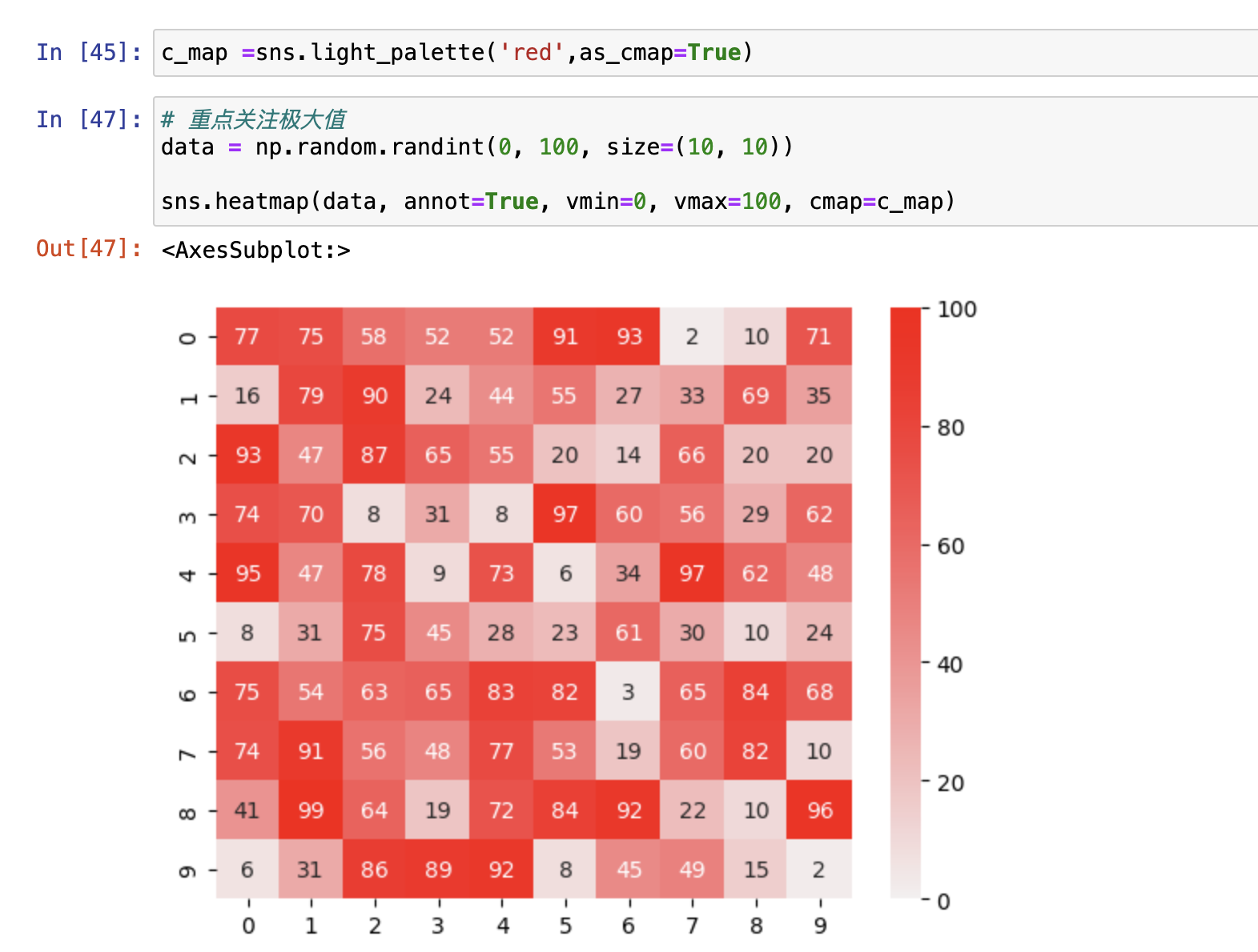
重点关注两端极值
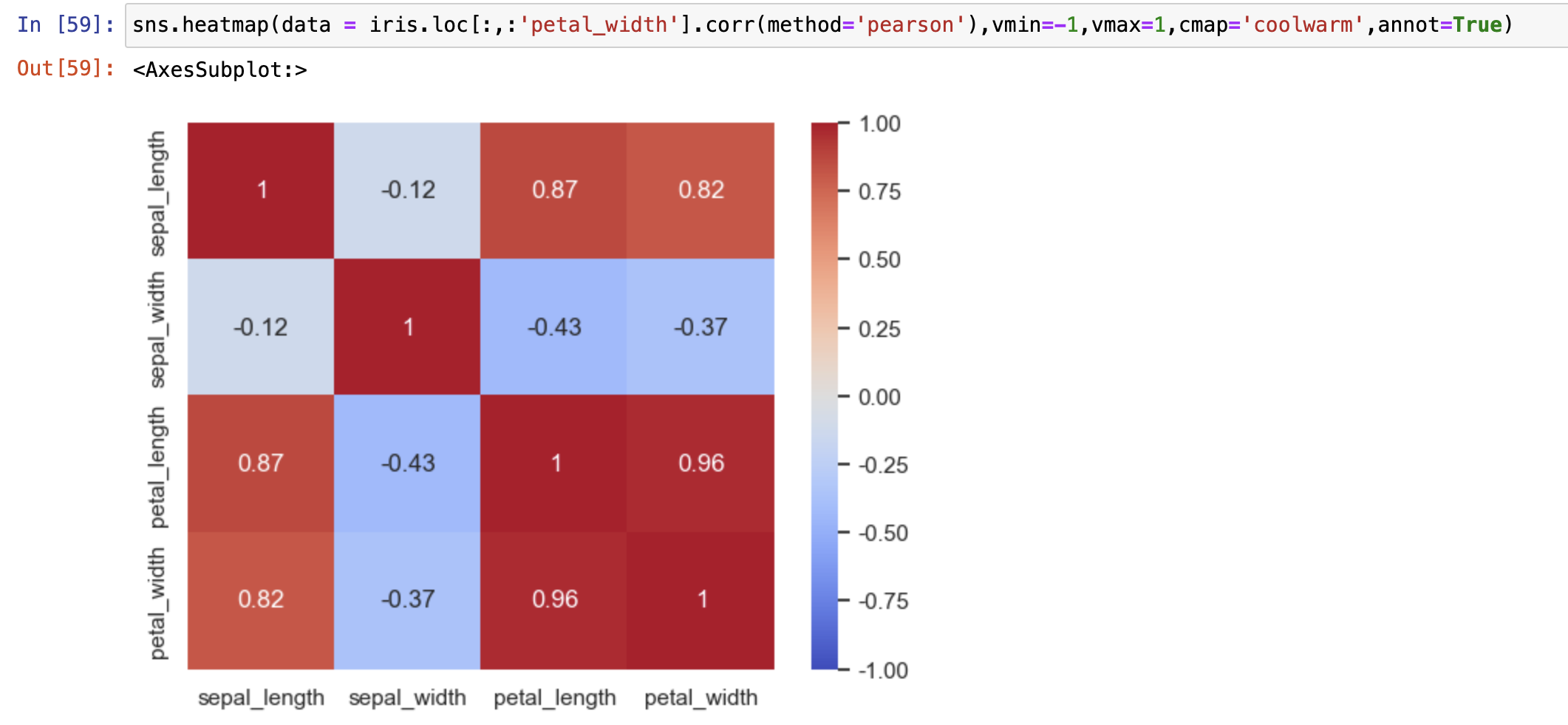
热力图应用场景:相关性分析
df.corr() 计算两组数据的相关性
三个相关性系数
(pearson, spearman, kendall)反应的都是两个变量之间变化趋势的方向以及程度,其值范围为-1到+1,0表示两个变量不相关,正值表示正相关,负值表示负相关,值越大表示相关性越强。method : {'pearson', 'kendall', 'spearman'}
Pearson : 当数据满足正态性时可用Pearson相关系数查看变量间关系情况
spearman : 当数据为定量数据,且不服从正态性则使用Spearman相关系数
kendall : Kendall相关系数通常用于评分数据一致性水平研究,比如评委打分,数据排名等。
高级函数
针对数据可视化的不同目的,seaborn提供了四大主要高级函数:
- relplot()
- lmplot()
- displot()
- catplot()
seaborn与pandas的DataFrame的结合非常好,因此传参是可以直接传入列名。返回的是FacetGrid(平面网格图)对象。
这些高级函数的主要参数如下:
- x,y:输入变量
- data:输入数据df
- hue:分组变量
- style:如传入,则hue分组后每组数据作图风格可不一致
- col,row:决定平面网格图布局的变量
- kind:底层作图类型名称,如"line",“bar”,"box"等
可视化变量关系(relationship)
- regplot() 方便观察变量间的关系, 默认是散点图
- lmplot() x和y必须以字符串的方式传入,比regplot更加严格
Regplot:
- x_jitter, y_jitter: 给离散型数据添加抖动(仅适用于离散型数据),且不会影响拟合的回归线本身
- x_estimator: 当x轴为离散数据时,指定y轴上的数据的运算函数,np.mean、np.median...
- order: 如果数据的分布规律是非线性的,设置order>1的任意值,则使用多项式回归来绘制回归曲线,2就是2次函数
- 阴影就是信赖区间
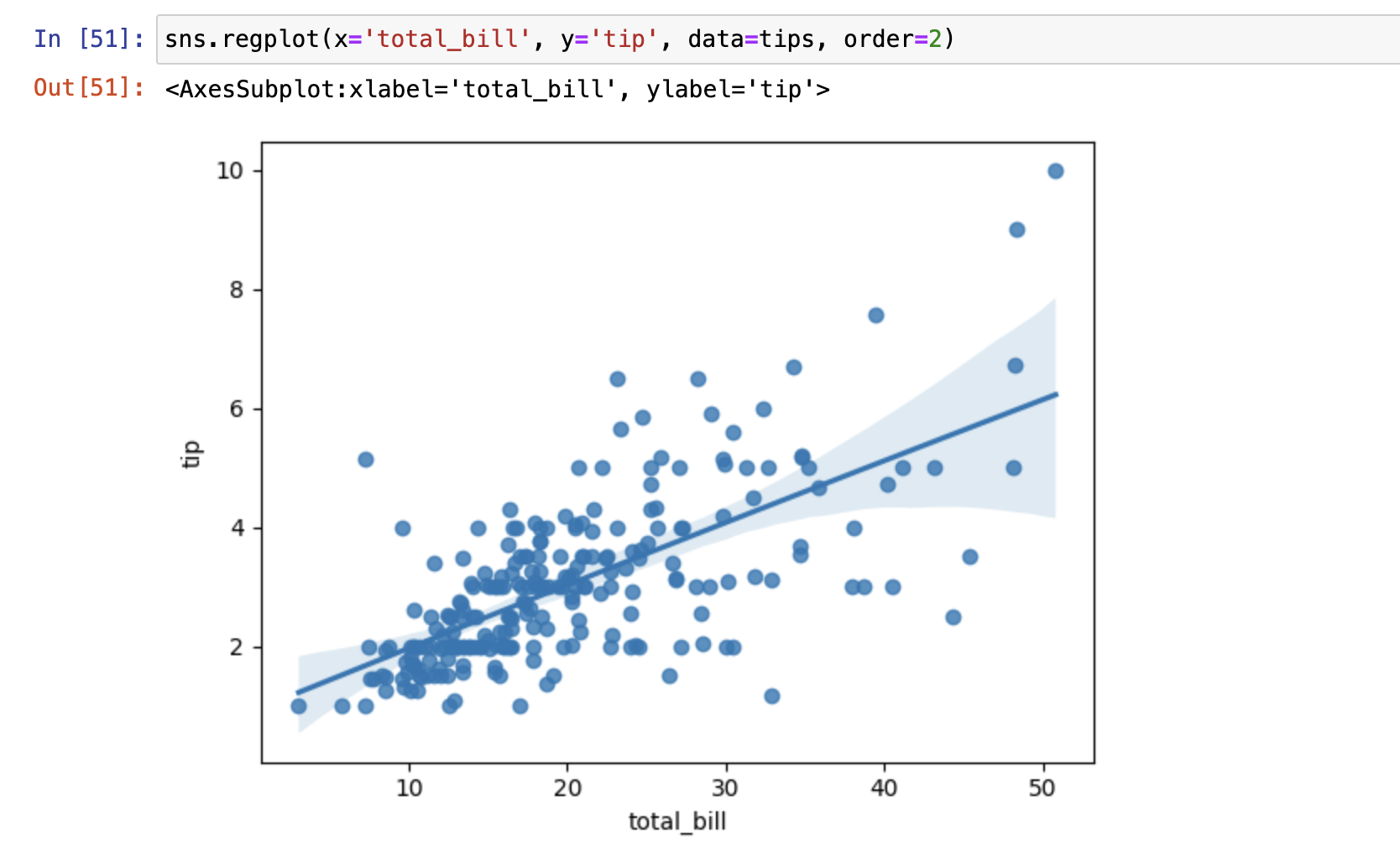
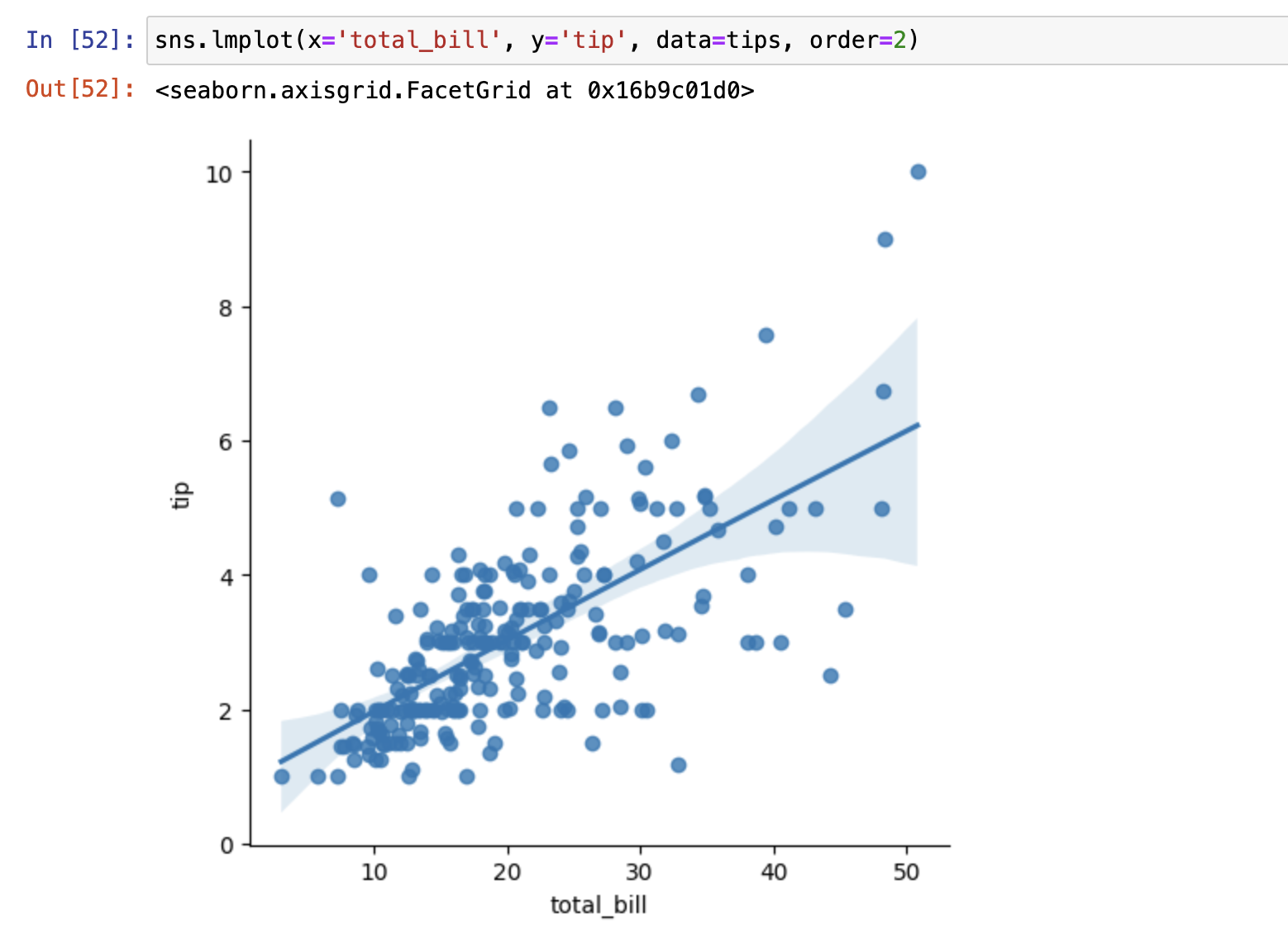
Lmplot()
主要用于创建散点图,并拟合数据的回归线
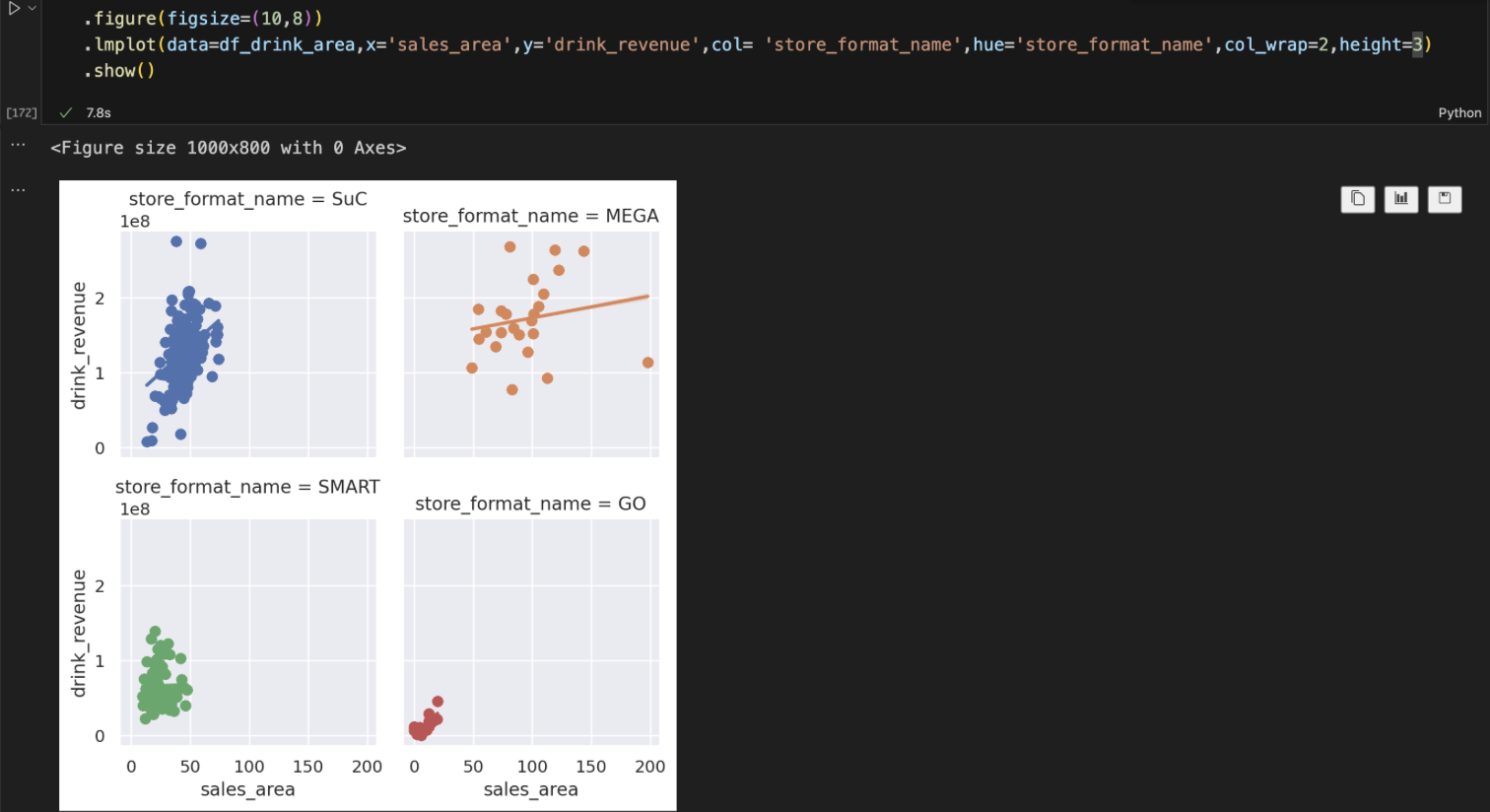
和regplot的区别,lmplot可以通过col参数分组,画出不同组的图,如下图
参数说明:
data:DataFrame,用于绘图的数据集。
x, y:字符串,数据集中用于绘制散点图的变量名称。
hue:字符串,数据集中的一个变量,用于根据其不同值对数据点进行着色。
col, row:字符串,数据集中的一个变量,用于根据其不同值创建多个列或行,并在每个子图中绘制数据的子集。
col_wrap:整数,指定每行的列数,用于控制
col或row参数创建的子图的排列方式。palette:字符串或字典,用于设置色彩主题。
fit_reg:布尔值,控制是否绘制回归线。
scatter_kws, line_kws:字典,用于传递给底层绘图函数(如 Matplotlib)的关键字参数。
height:浮点数,指定图形的高度(以英寸为单位)。
aspect:浮点数,指定图形的纵横比(aspect ratio)。
markers:字符串或布尔值,指定散点图的标记类型或是否显示标记。
ci:浮点数或 None,控制回归线的置信区间的宽度。
robust:布尔值,控制是否使用鲁棒回归拟合。
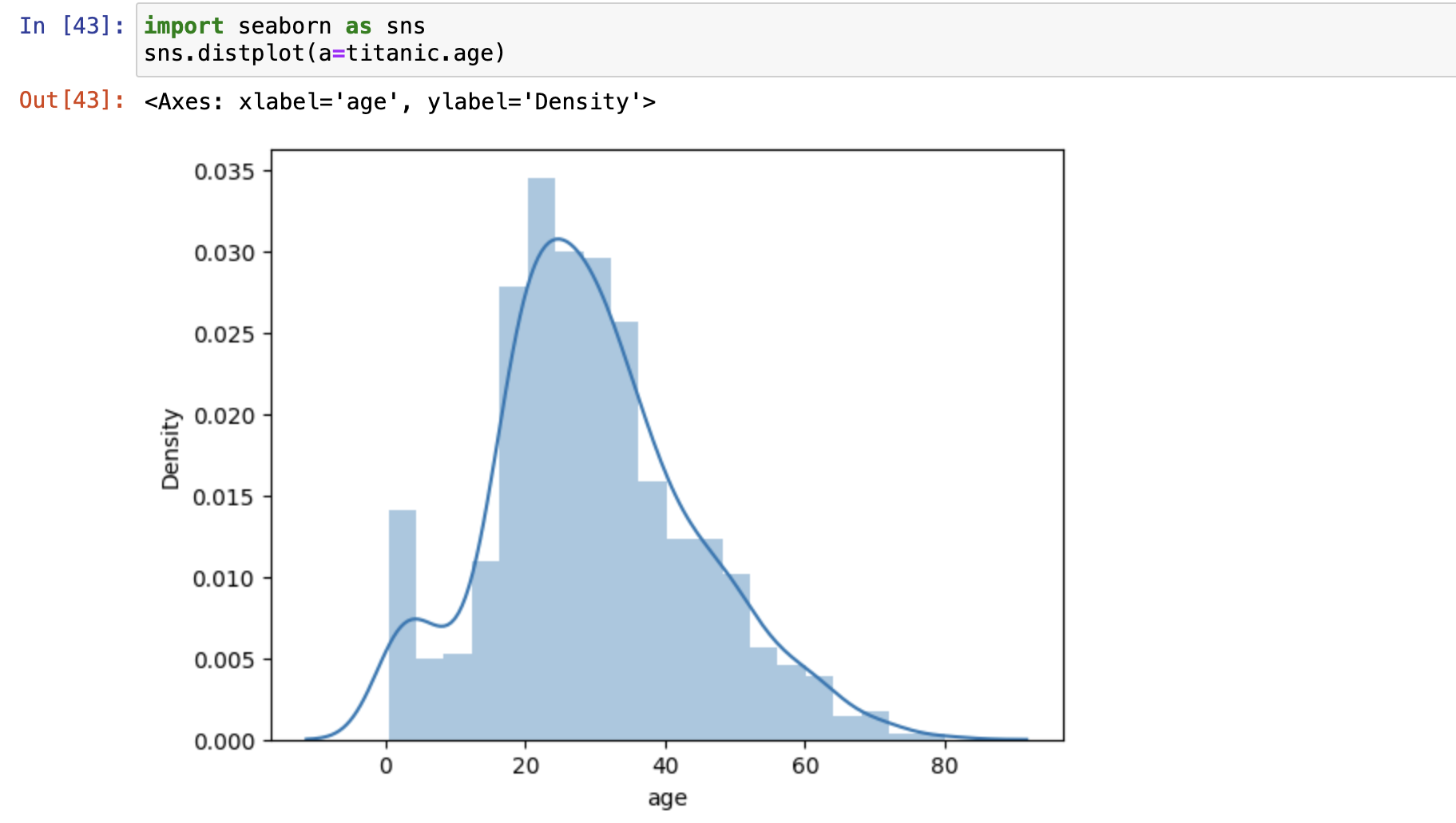
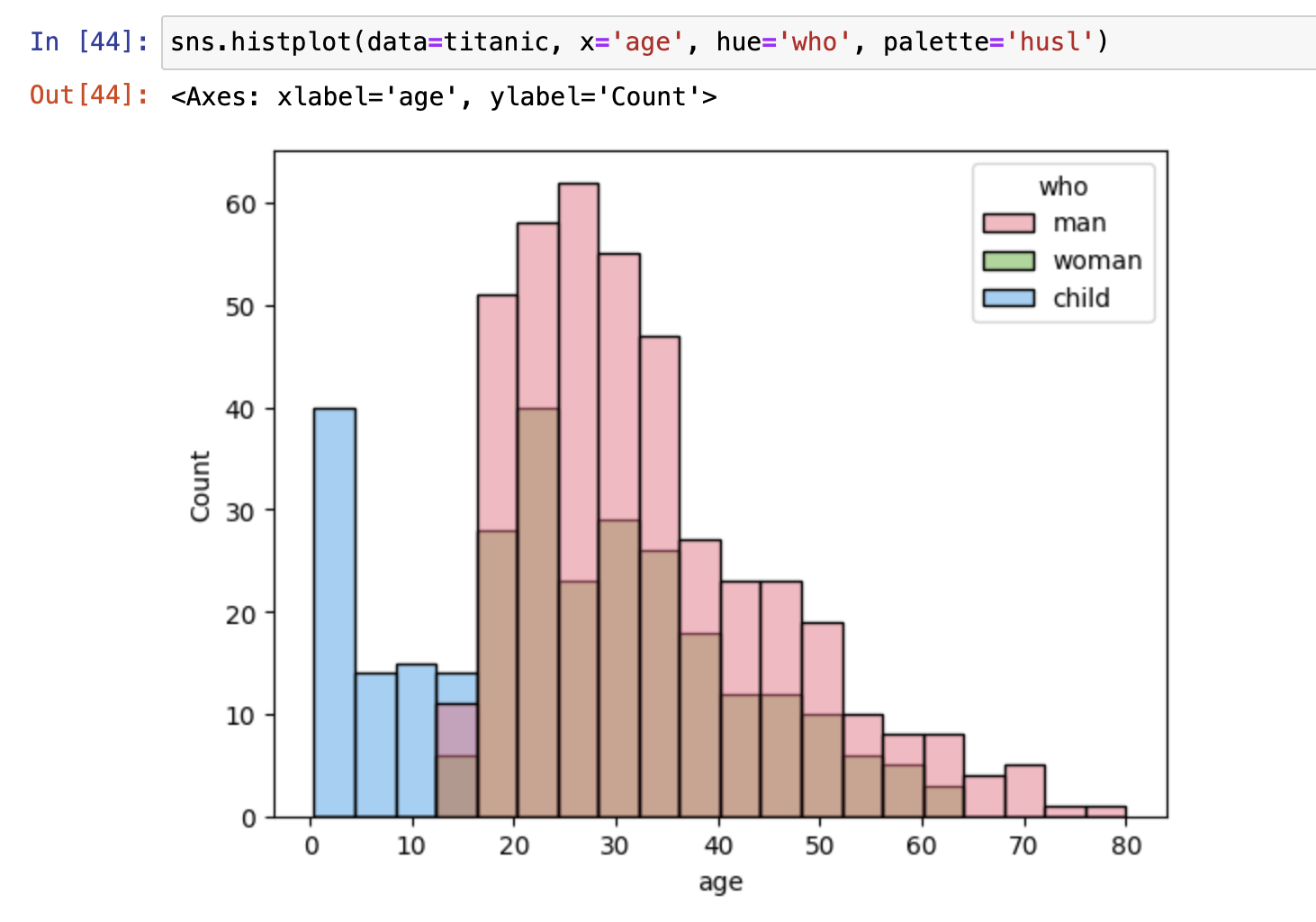
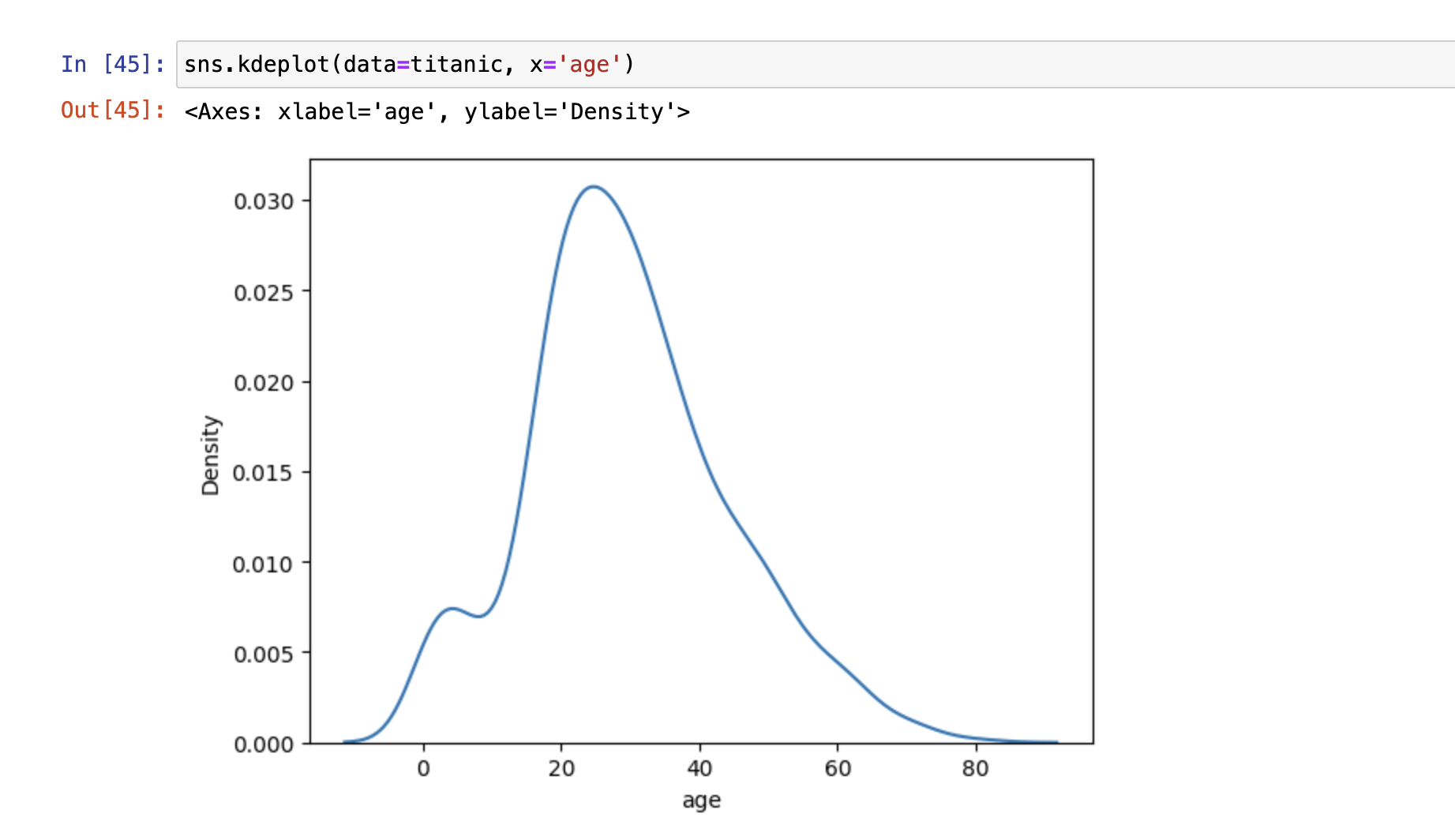
数据集分布图(distribution)
- 特征工程前,需要对数据集的有一个整体的了解,seabon提供的高级函数displot()可以作各种分布图。
单变量分布
就只有一个变量画图,比如直方图。
- distplot()
- histplot()
- kdeplot()
- rugplot()
参数说明:
- bins: 数据分布区间个数
- axlabel: 横轴标签
- label: 图例标签
- kde: 是否显示核密度估计,如果开启,则数据以归一化方式显示
- rug: 是否显示地毯图
- (kde、hist、sug)kws: 外观属性设置
- norm_hist: 是否归一化处理,需要关闭kde显示
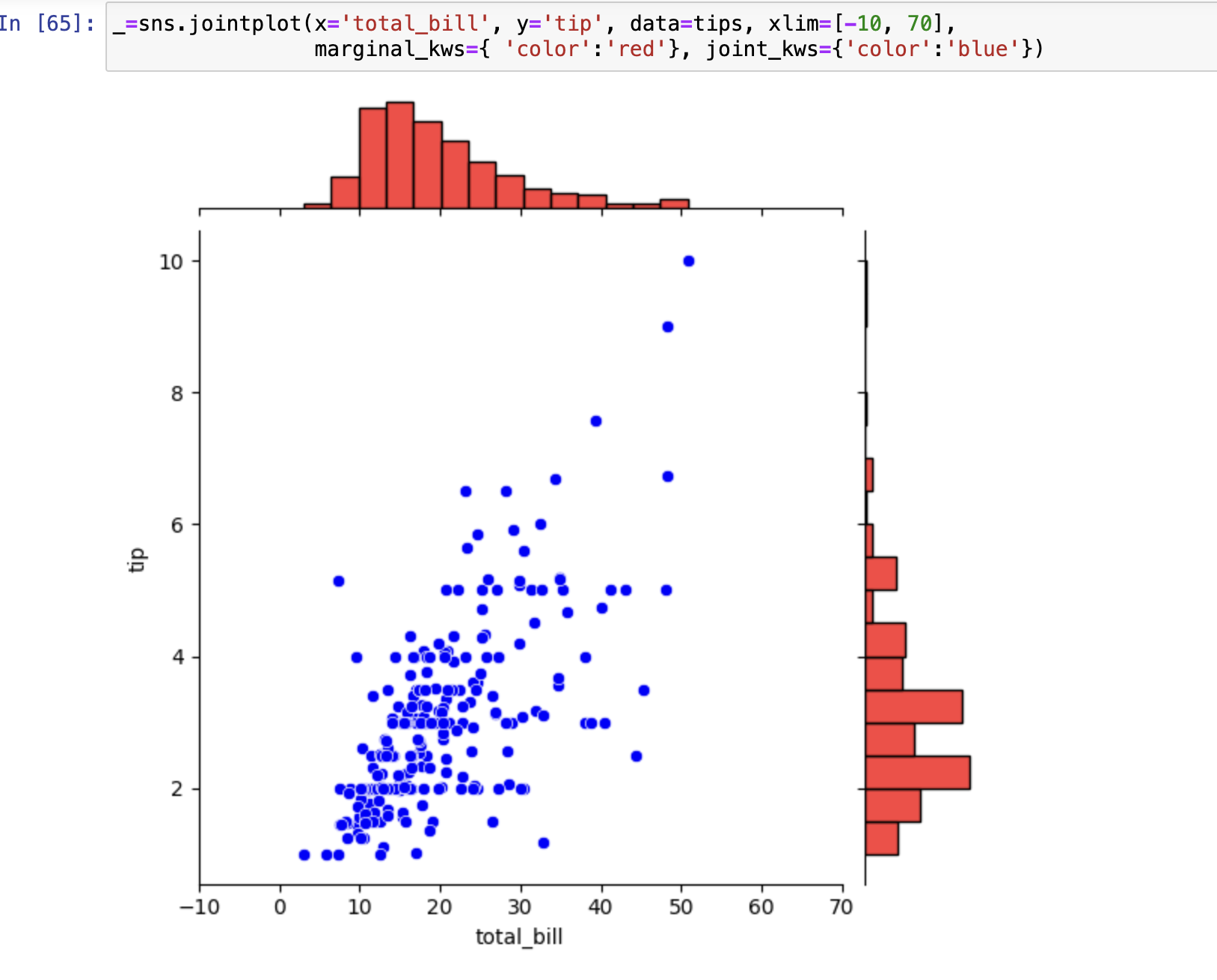
双变量分布
- jointplot()
参数说明:
- xlim、ylim: 横、纵轴界限
- space: 主画布和分支画布之间的距离(0~1浮点)
- marginal_kws:分支画布外观属性
- joint_kws:主画布外观属性 , 散点图具备的属性都可以通过字典的方式进行设置
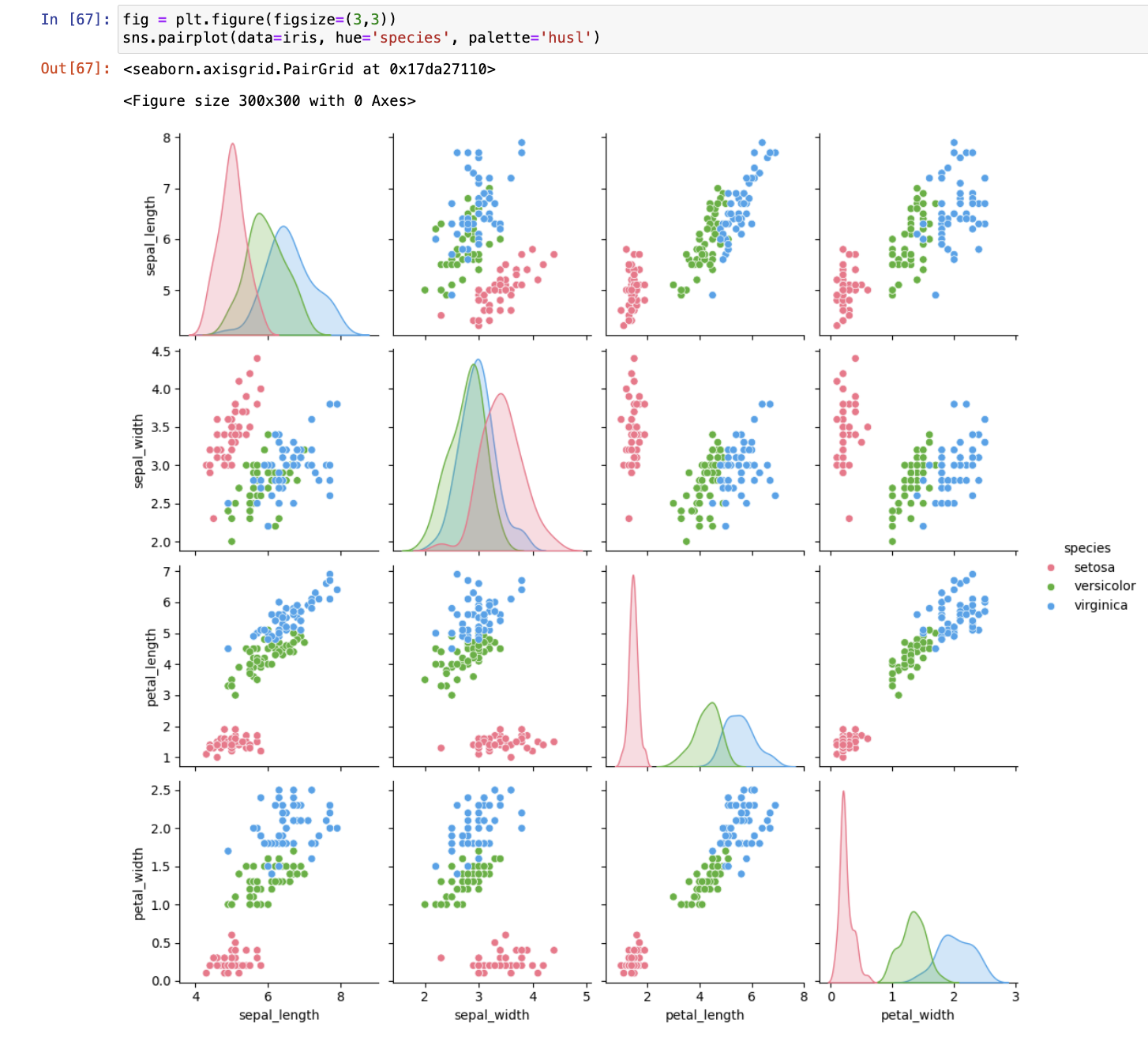
成对变量分布
- pairplot()
参数说明:
- vars、x_vars, y_vars: 要进行显示的列
- markers: 分组数据的点型,列表
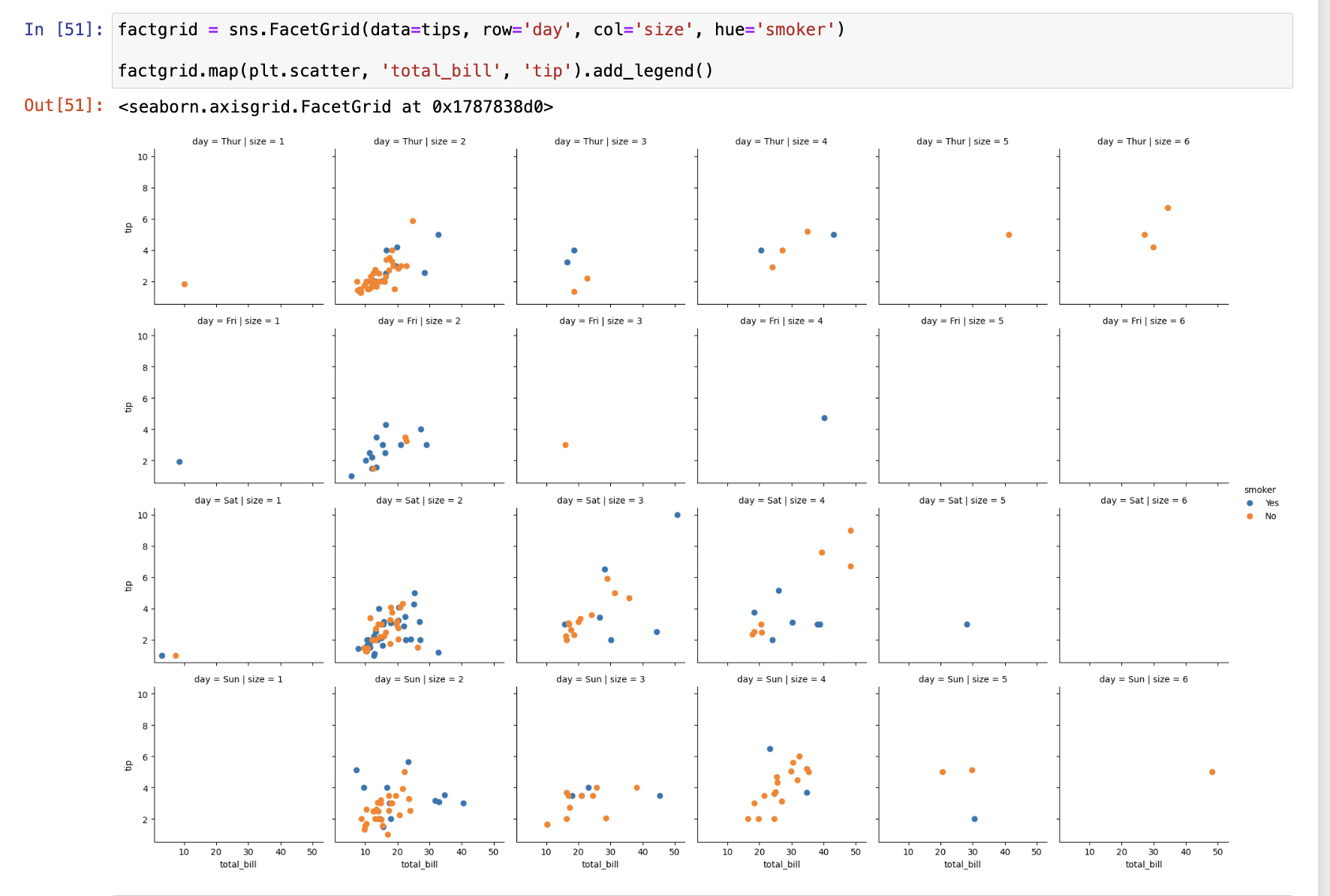
绘制多层面板分类图
factorplot(),可以以更多的子视图展示更多的数据关系
也可以使用FacetGrid()对象
参数说明:
- x,y,hue 数据集变量 变量名
- date 数据集 数据集名
- row,col 更多分类变量进行平铺显示 变量名
- col_wrap 每行的最高平铺数 整数
- estimator 在每个分类中进行矢量到标量的映射 矢量
- ci 置信区间 浮点数或None
- n_boot 计算置信区间时使用的引导迭代次数 整数
- units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
- order, hue_order 对应排序列表 字符串列表
- row_order, col_order 对应排序列表 字符串列表
- kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点(具体图形参考文章前部的分类介绍)
- size 每个面的高度(英寸) 标量
- aspect 纵横比 标量
- orient 方向 "v"/"h"
- color 颜色 matplotlib颜色
- palette 调色板 seaborn颜色色板或字典
- legend hue的信息面板 True/False
- legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False
- share{x,y} 共享轴线 True/False
- facet_kws FacetGrid的其他参数 字典
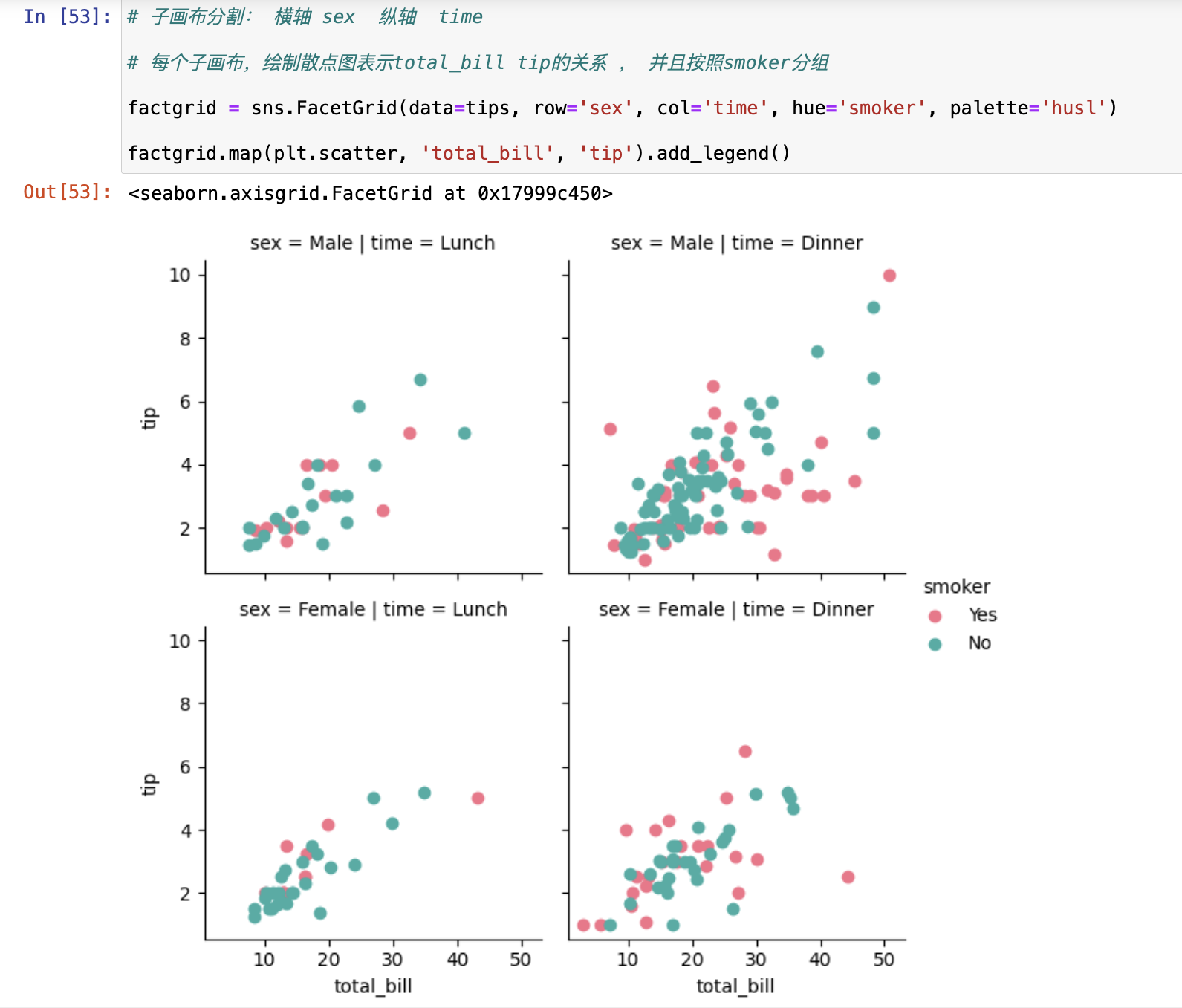
FacetGrid对象,多子图情况的处理
今天遇到个这么个事儿:使用lmplot画图,返回一个有多个子图的FacetGrid对象,需要对每个子图分别处理,如设置title,xlabel,以及将各个子图的变量间相关系数写在每一个子图上,没整明白
使用自带参数对每个子图操作
- pic.axes.flatten()
- pic.axes中存储着FacetGrid(平面网格图)对象中的每一个子图对象,循环每一个子图对象就可以分别操作了。如下图所示,
- 但 pic.axes作为一个子图对象,本质是二维数组,存在索引问题
- 因此使用
flatten()方法,它会将这个二维数组展平为一个一维数组,方便对每个坐标系进行迭代或者操作。这样就可以对每个坐标系进行单独的操作,而不需要考虑多维数组的索引问题。 - 所以最终使用
pic.axes.flatten()可以循环每一个子图对象
使用自定义函数对每个子图操作
但是如果要对每个子图做的操作比较复杂,使用自带参数无法直接解决时,需要自定义函数
那问题又来了,如何对每个子图的数据使用函数?
seaborn.FacetGrid.map_dataframe()
map_dataframe()允许你使用一个自定义函数来对数据进行操作,并在每个子图上应用这个函数(每个子图本质上就是一个二维数组嘛)。这个方法的典型用法是,提供一个函数来绘制每个子图的内容。这个函数会接受DataFrame作为输入,并且必须返回一个 matplotlib Axes 对象,用于绘制子图的内容。
注意:
map_dataframe()中传入的是函数名,不要加括号使用方法,举个例子:
- python
# 使用 map_dataframe() 方法在每个子图中绘制散点图 g.map_dataframe(sns.scatterplot, x="total_bill", y="tip")
seaborn.FacetGrid.map()
seaborn.FacetGrid.map()允许在每个子图上应用一个函数。这个函数可以是内置的 seaborn 绘图函数,也可以是你自己定义的函数。注意:
map()中传入的是函数名,不要加括号使用方法:
- python
# 使用 map() 方法在每个子图中绘制散点图 g.map(sns.scatterplot, "total_bill", "tip")
现在可以回头看看最初的问题了,今天遇到个这么个事儿:使用lmplot画图,返回一个有多个子图的FacetGrid对象,需要对每个子图分别处理,如设置title,xlabel,以及将各个子图的变量间相关系数写在每一个子图上,没整明白
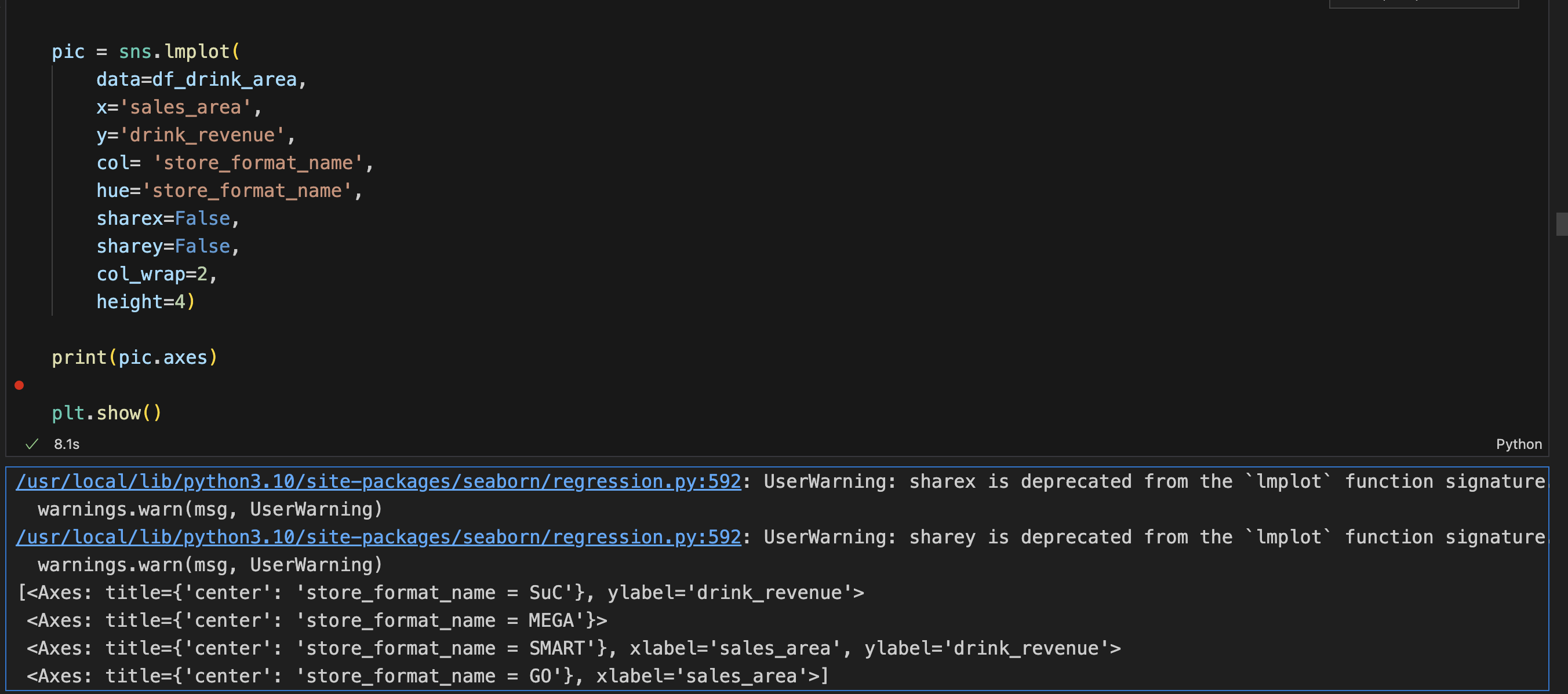
# 使用lmplot画图,使用hue通过store_format_name字段分组,画完有四个子图
pic = sns.lmplot(
data=df_drink_area,
x='sales_area',
y='drink_revenue',
col= 'store_format_name',
hue='store_format_name',
sharex=False, # 是否共用x轴
sharey=False, # 是否共用y轴
col_wrap=2, # 生成的图中,每行展示几个子图
height=4)
f_names = df_area_process_drink['store_format_name'].unique() # 根据store_format_name分了四组,获得四组名字
# 通过 pic.axes.flatten() 循环每个子图,给属性
for ax,f_name in zip(pic.axes.flatten(),f_names):
ax.set_xlabel('売場面積')
ax.set_ylabel('売上金額(百万円)')
ax.set_title(f_name)
# 要计算store_format_name的四个类别,各自的sales_area和drink_revenue 的相关系数,并写在图上
# 先自定义计算相关系数的函数
def annotate(data,*args,**kwargs):
r,p = sp.stats.pearson(data['sales_area'],data['drink_revenue'])
ax = plt.gca()
ax.text(x=0.1,y=0.9,s=f'相関:{r:2f},p値:{p:.2f}',transform = ax.transAxes) #注释文本的位置是相对于坐标系的。
# 对FacetGrid对象里的每个子图应用函数
pic.map_dataframe(annotate)
#图像总标题
pic.figure.suptitle('フォーマット別に売場面積と店舗の飲料の年間売上金額')
#tight_layout()用于自动调整图形的布局,以确保图形中的子图或元素之间没有重叠,并尽可能有效地利用空间。
pic.tight_layout()
plt.show()