什么是Pandas
- Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
- Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
- Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。
- Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
- Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
- Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例
Series
Series是一种类似于字典(dict-like)的一维数组(array-like)的对象,由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
- Series和ndarray一样,会强制类型统一
构造Series
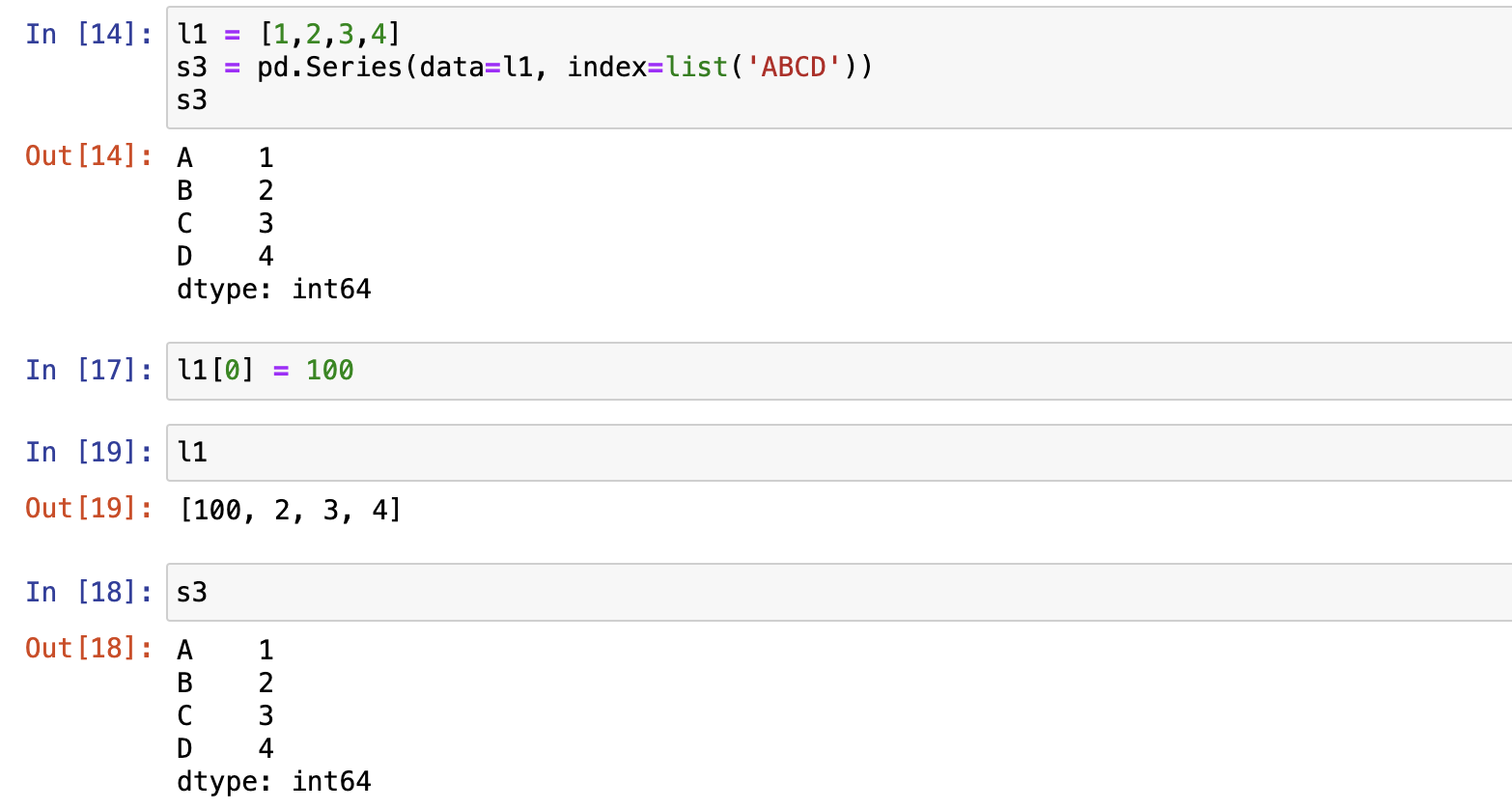
- From ndarray 使用ndarray构造 ,series是ndarray的一个引用对象。ndarray和series共用一块内存,series改变,ndarray也跟着改变。
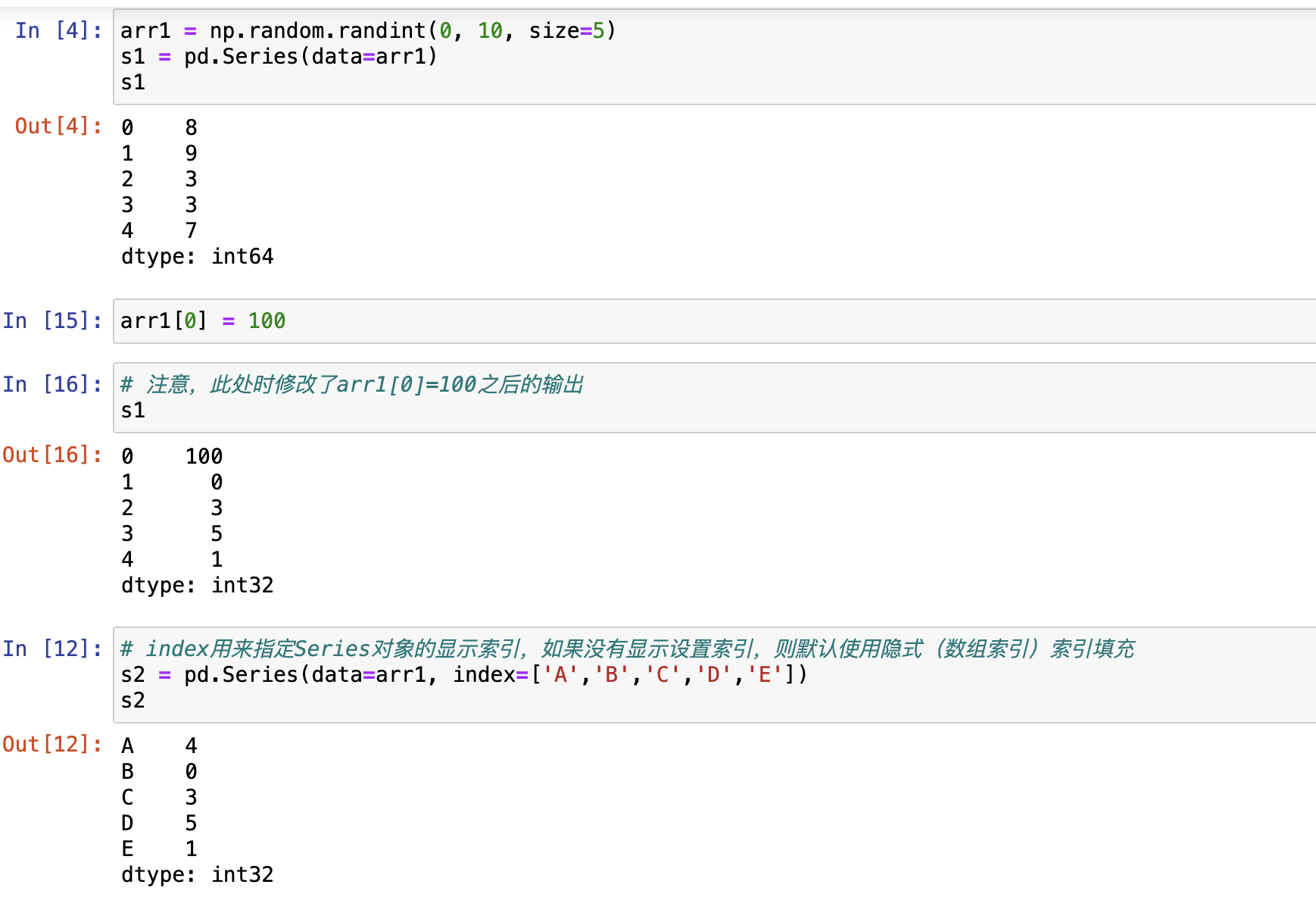
- From List 使用列表构造 ,series是list一个副本对象。ndarray和series不共用内存。series改变,list不会改变。
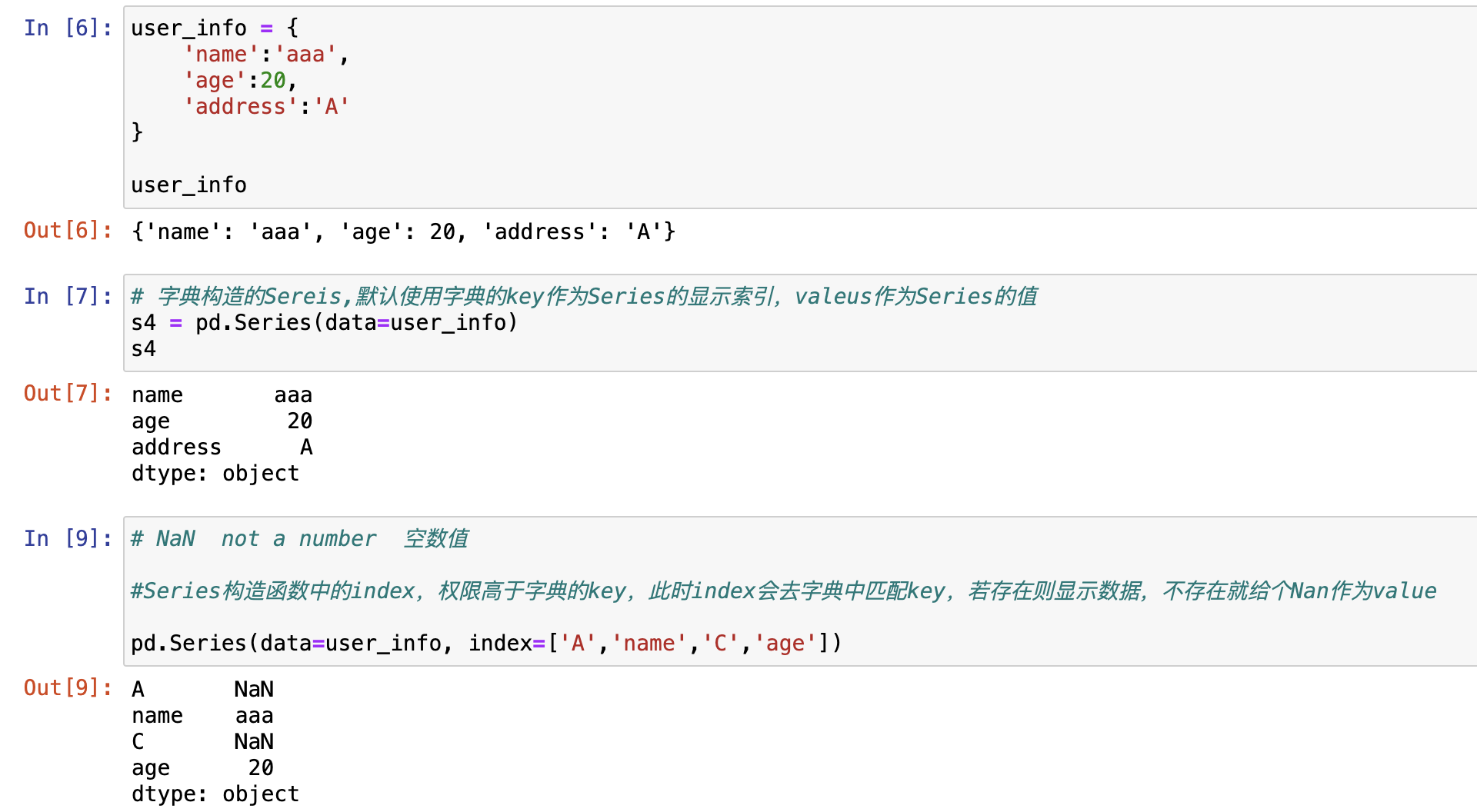
- From dict 使用字典构造。
- From scalar value,使用一个标量(常量或变量)构造时,必须指定index,标量会被重复匹配到每一个index
###使用ndarray构造
series是ndarray的一个引用对象。ndarray和series共用一块内存,series改变,ndarray也跟着改变。
使用列表构造
series是list一个副本对象。ndarray和series不共用内存。series改变,list不会改变。series是list一个副本对象。ndarray和series不共用内存。series改变,list不会改变。
使用字典构造
Series是一个dict-like对象,当然可以用字典直接构造
使用一个标量(常量或变量)构造
From scalar value,使用一个标量(常量或变量)构造时,必须指定index,标量会被重复匹配到每一个index
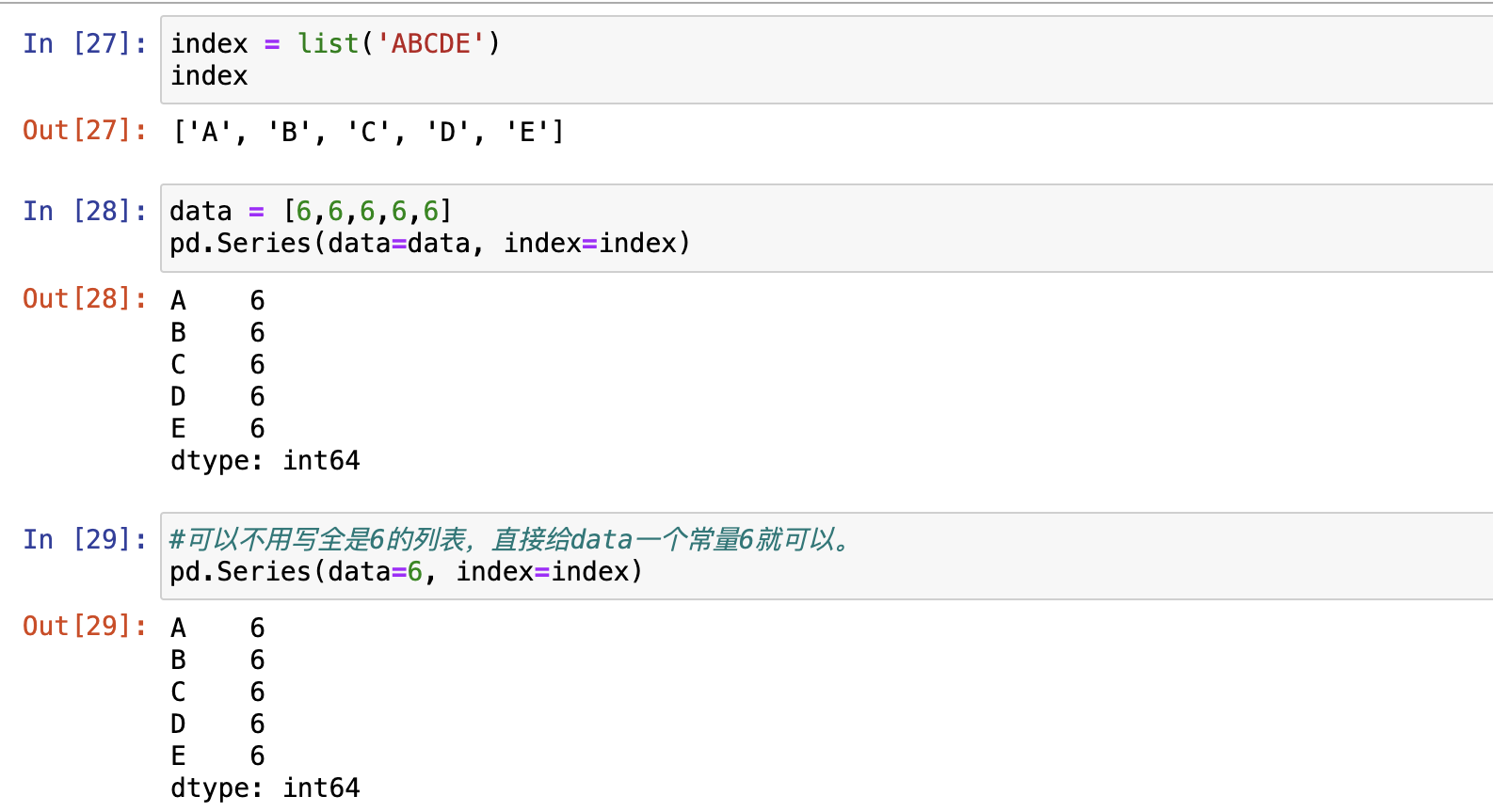
Series属性
- name 返回Series对象的名字
- shape 返回Series对象的形状
- size 返回Series对象的元素个数
- index 返回Series对象的显示索引
- values 返回Sereis对象的所有元素值
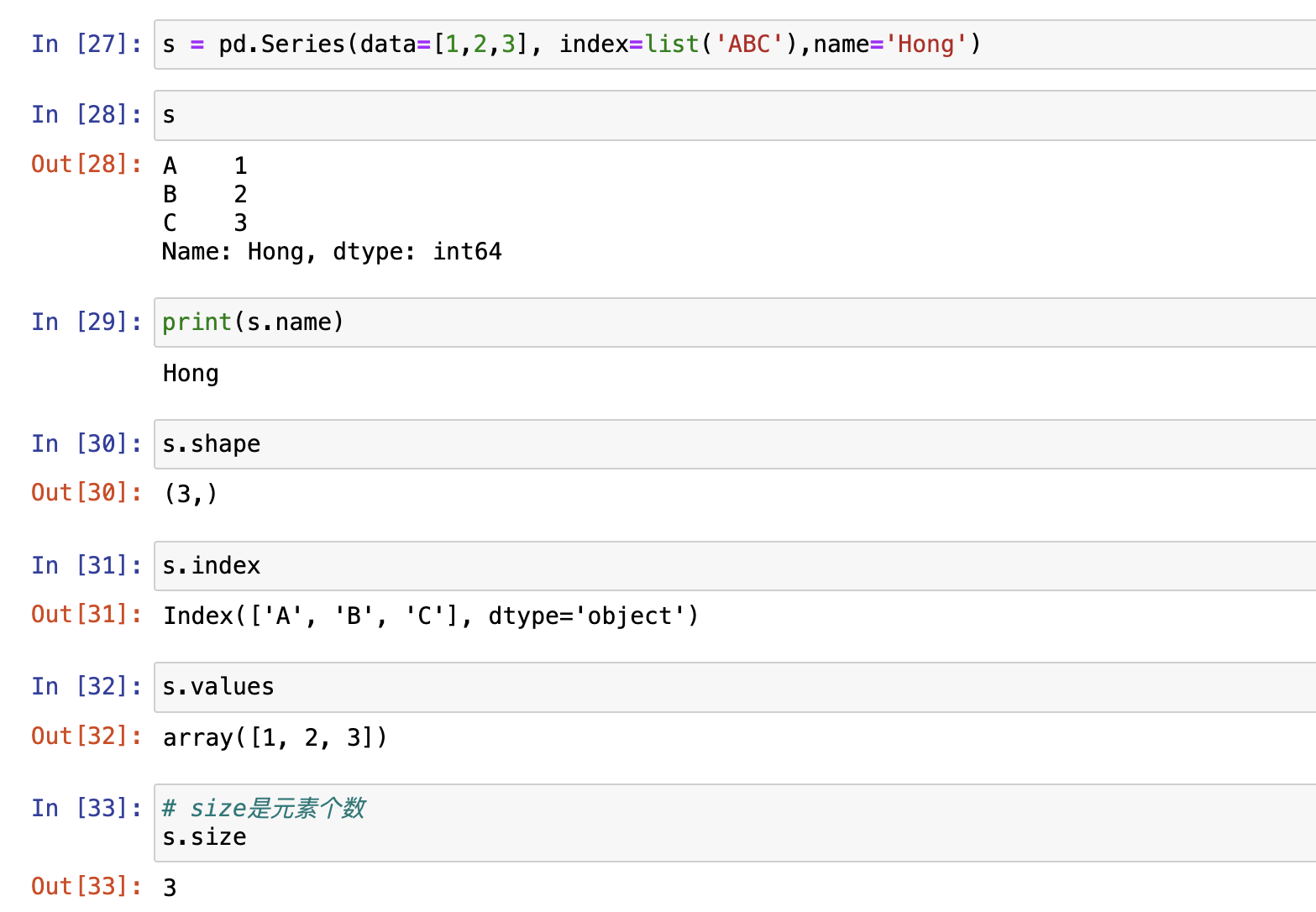
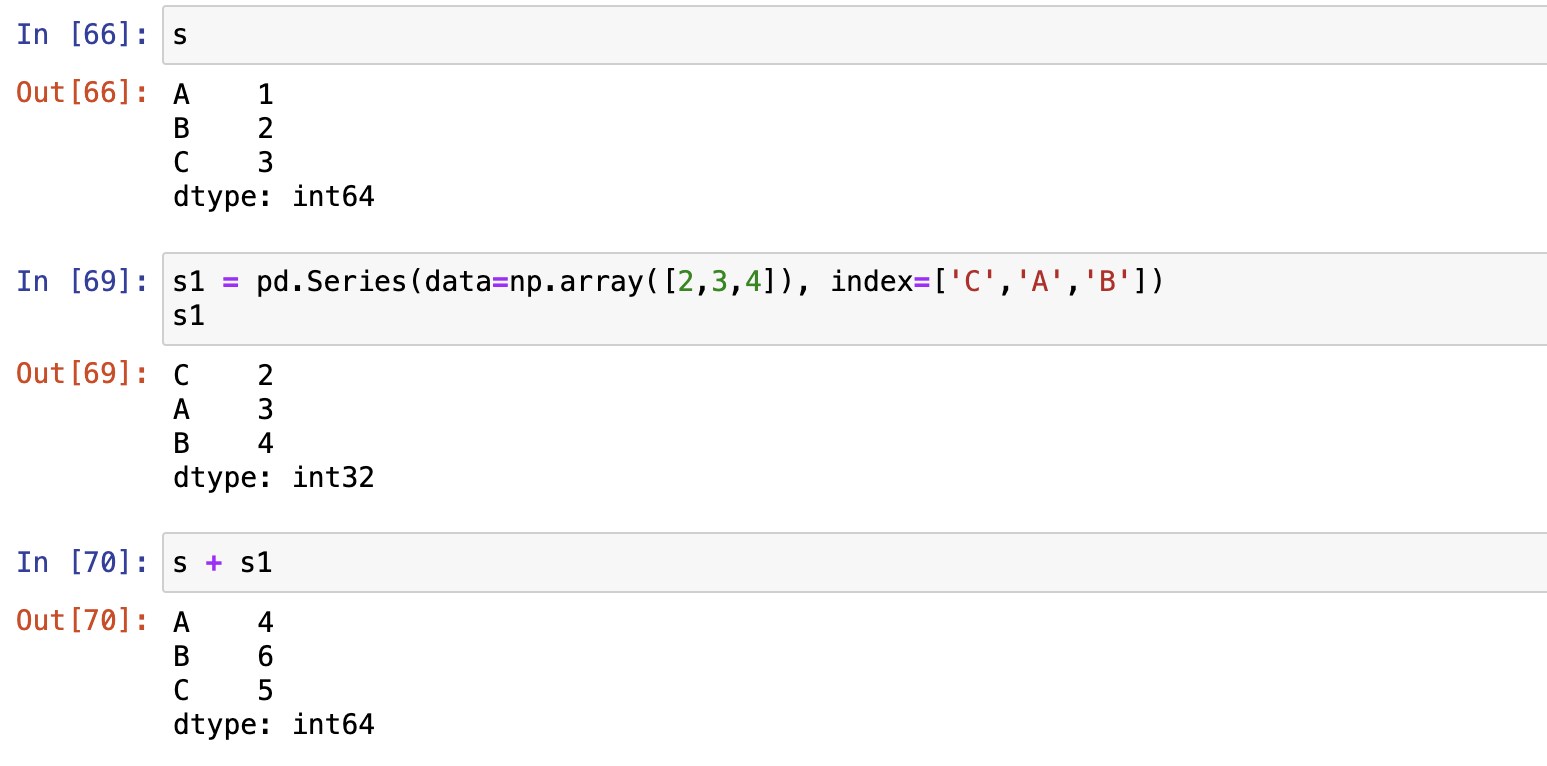
Sereis的数学运算
Series对大多数NumPy的函数都是兼容的
- 与非pandas对象运算,服从广播机制原则
- NumPy functions
- Series之间运算
- 索引对齐原则
- 对不齐补空值, 使用add\sub\mul\div函数处理空值
与非pandas对象运算,服从广播机制原则
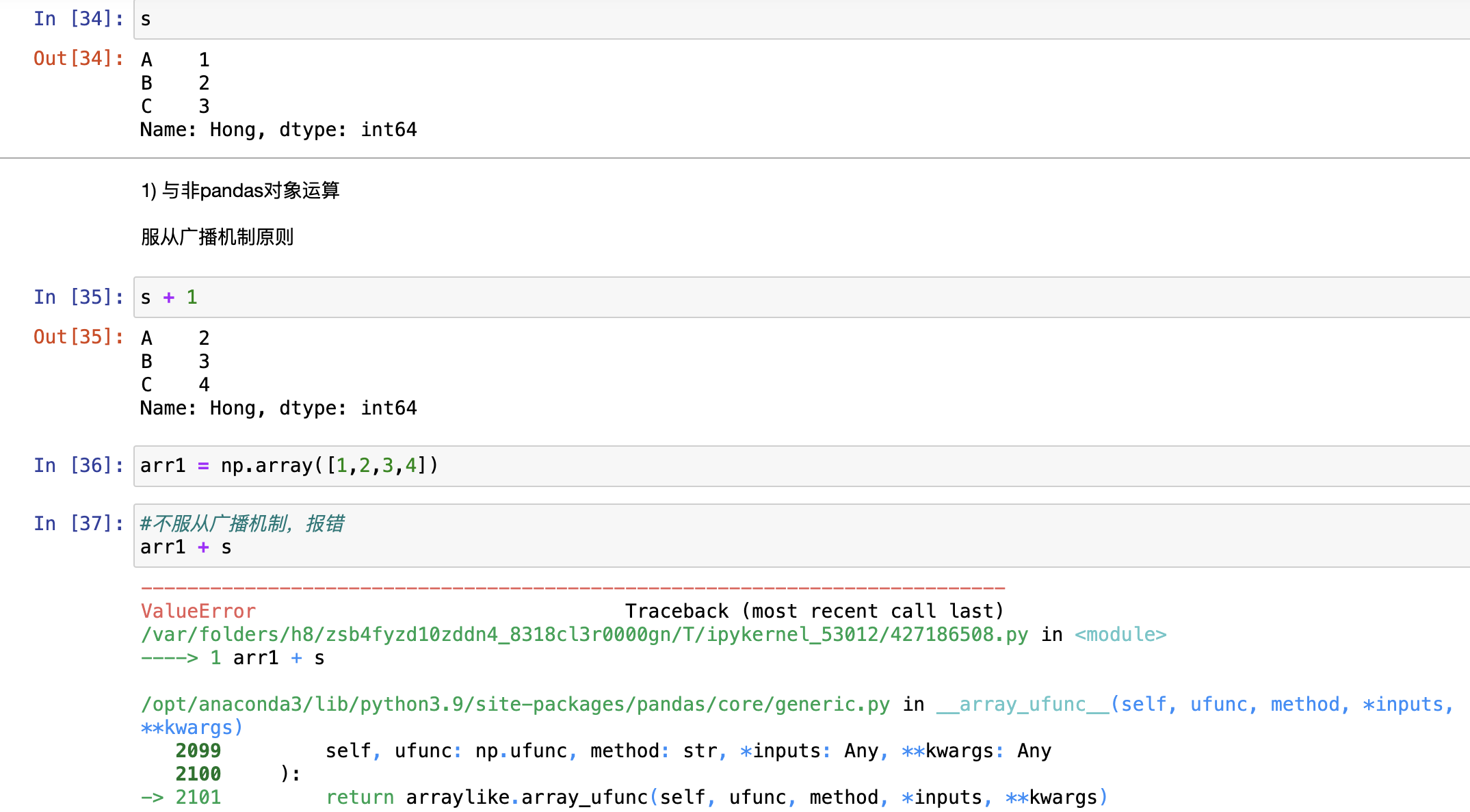
###NumPy functions
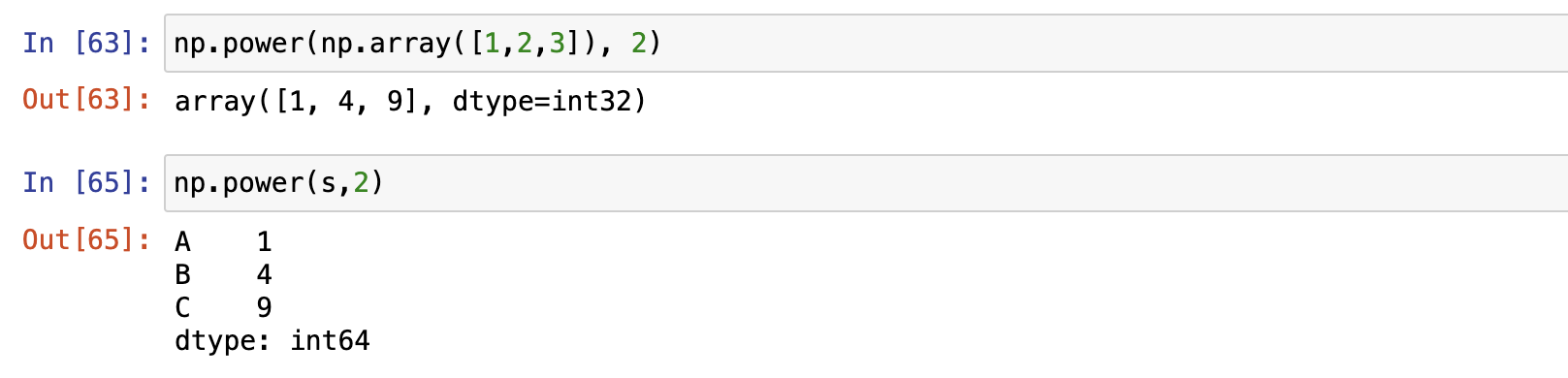
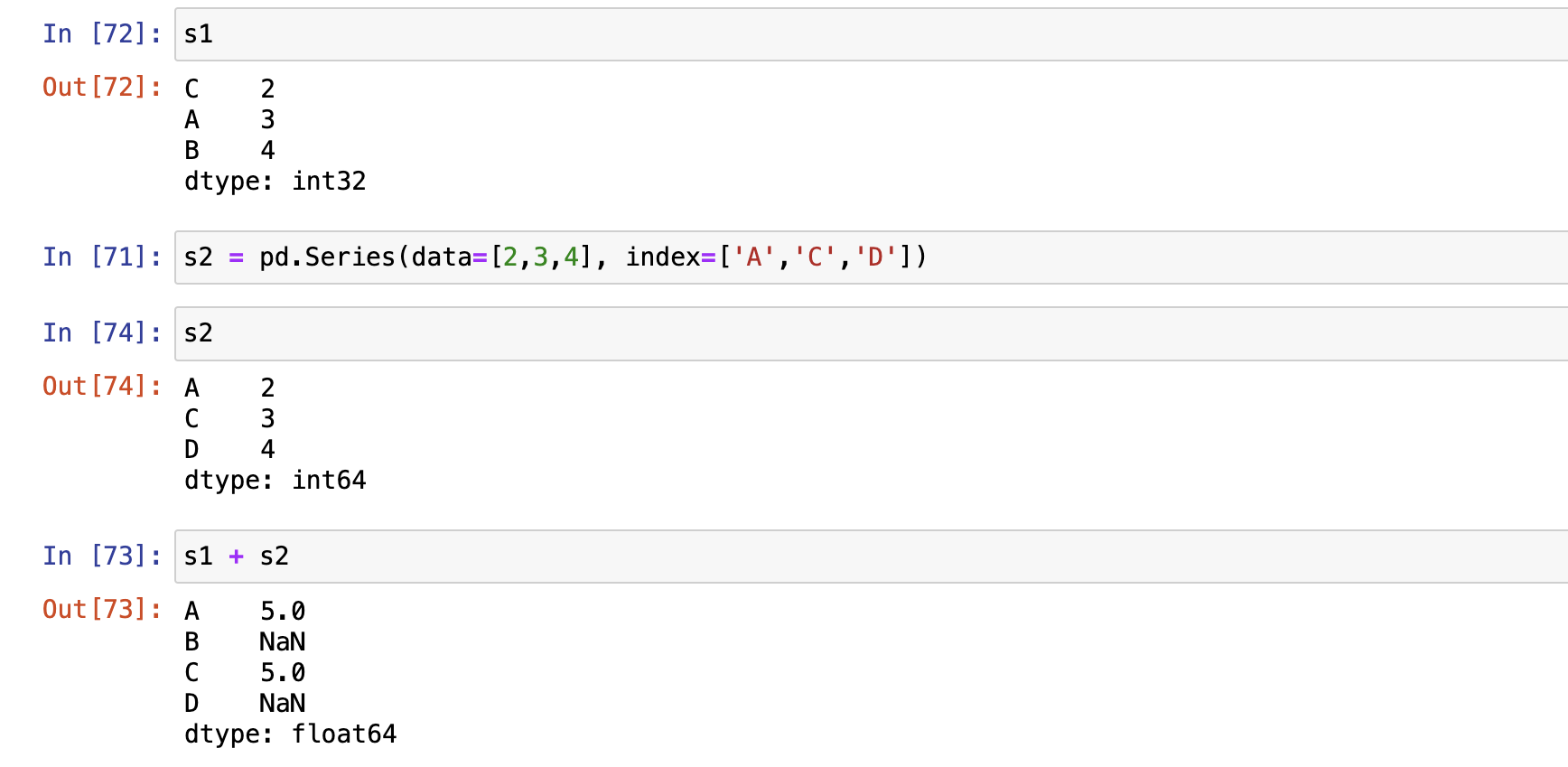
Series之间运算
- 索引对齐原则
- 对不齐补空值, 使用add\sub\mul\div函数处理空值
DataFrame
DataFrame是一个二维的表格型数据结构,可以看做是由Series组成的字典(共用同一个索引)。 DataFrame由按一定顺序排列的【多列】数据组成,每一列的数据类型可能不同。 设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(numpy的二维数组)
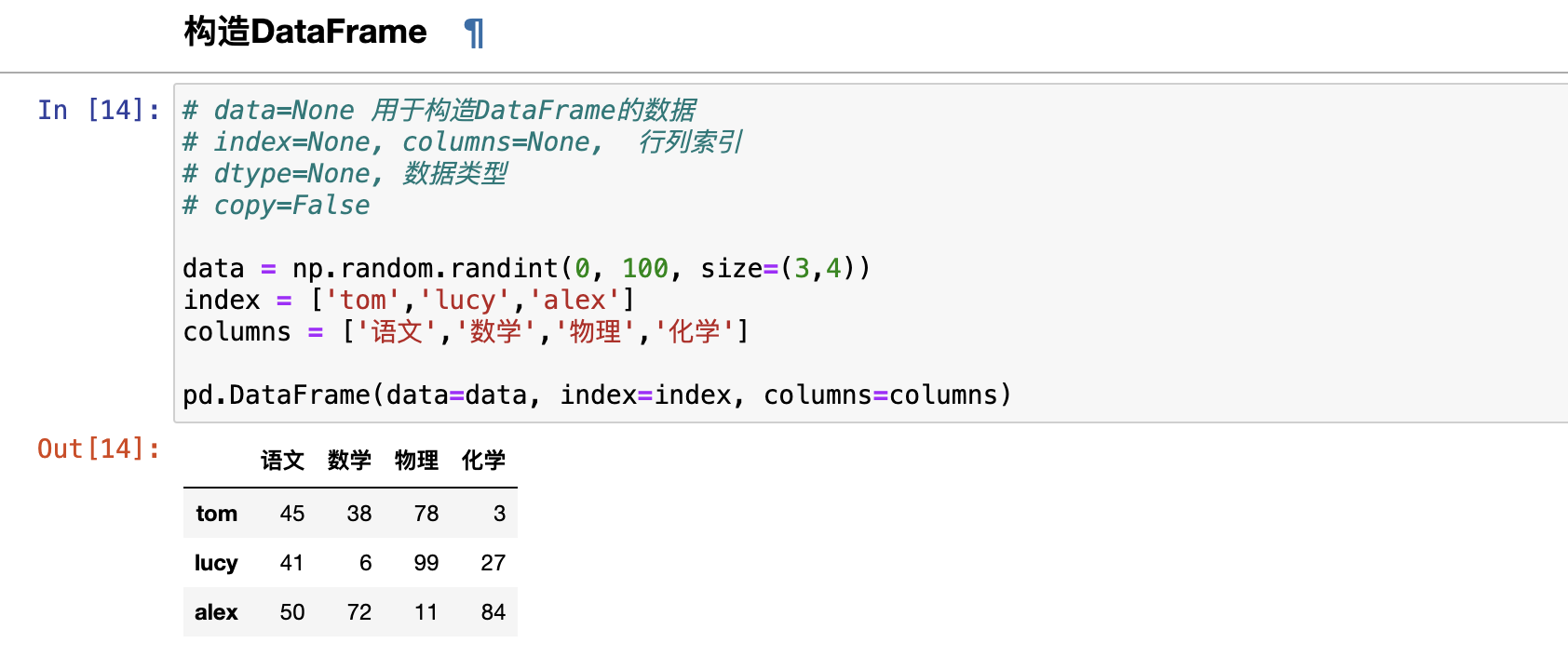
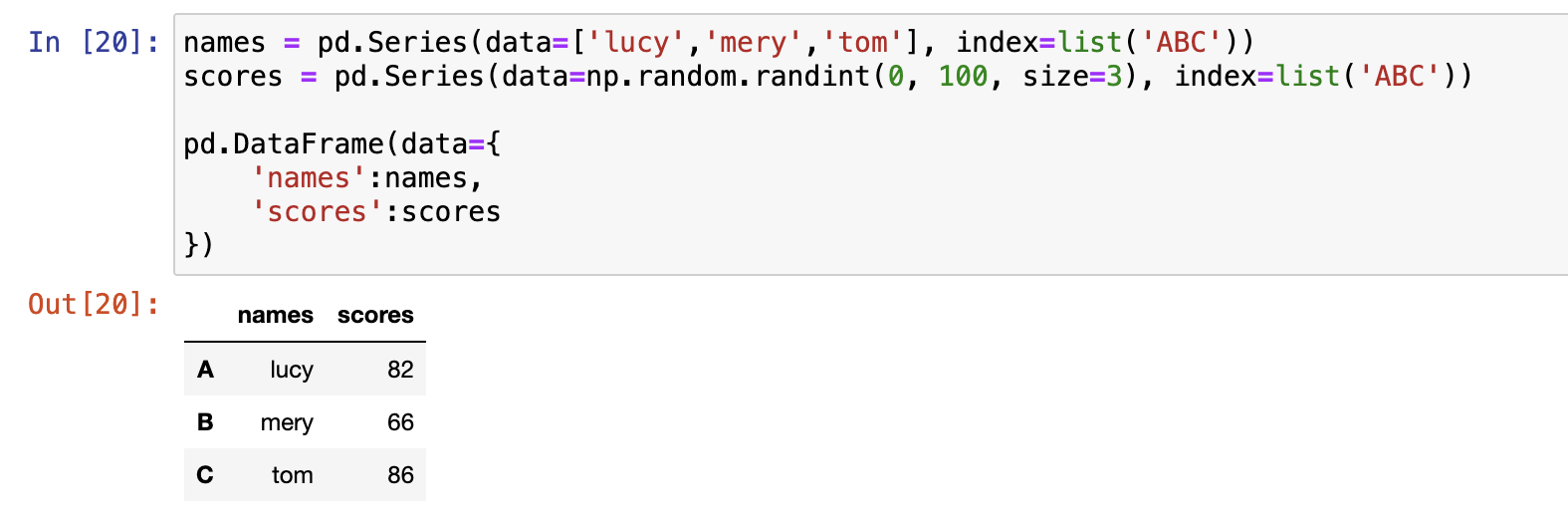
构造DataFrame
- From dict of Series or dicts 使用一个由Series构造的字典或一个字典构造
- From dict of ndarrays / lists 使用一个由列表或ndarray构造的字典构造,ndarrays必须长度保持一致
- From a list of dicts 使用一个由字典构成的列表构造
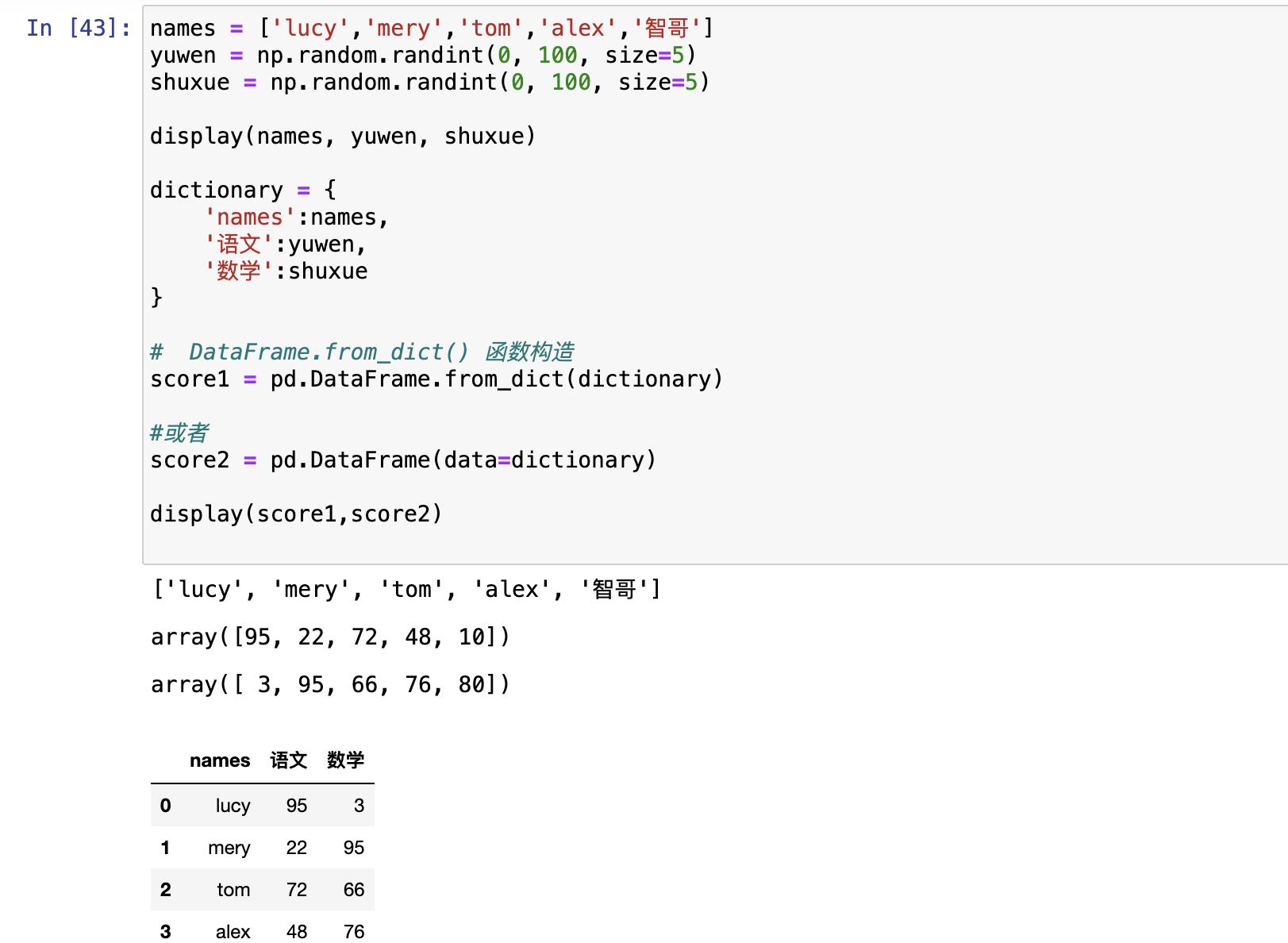
- DataFrame.from_dict() 函数构造
###使用一个由Series构造的字典或一个字典构造
###使用一个由列表或ndarray构造的字典构造

###使用一个由字典构成的列表构造

DataFrame.from_dict() 函数构造
DataFrame属性
- dtypes
- values
- index
- columns
DataFrame运算
- 与非pandas对象运算
- 与Series对象运算
- 与DataFrame对象运算
- 索引对齐原则(row\columns)
- 对不齐补空值, 使用add\sub\mul\div函数处理空值
- NumPy functions
- 转置运算
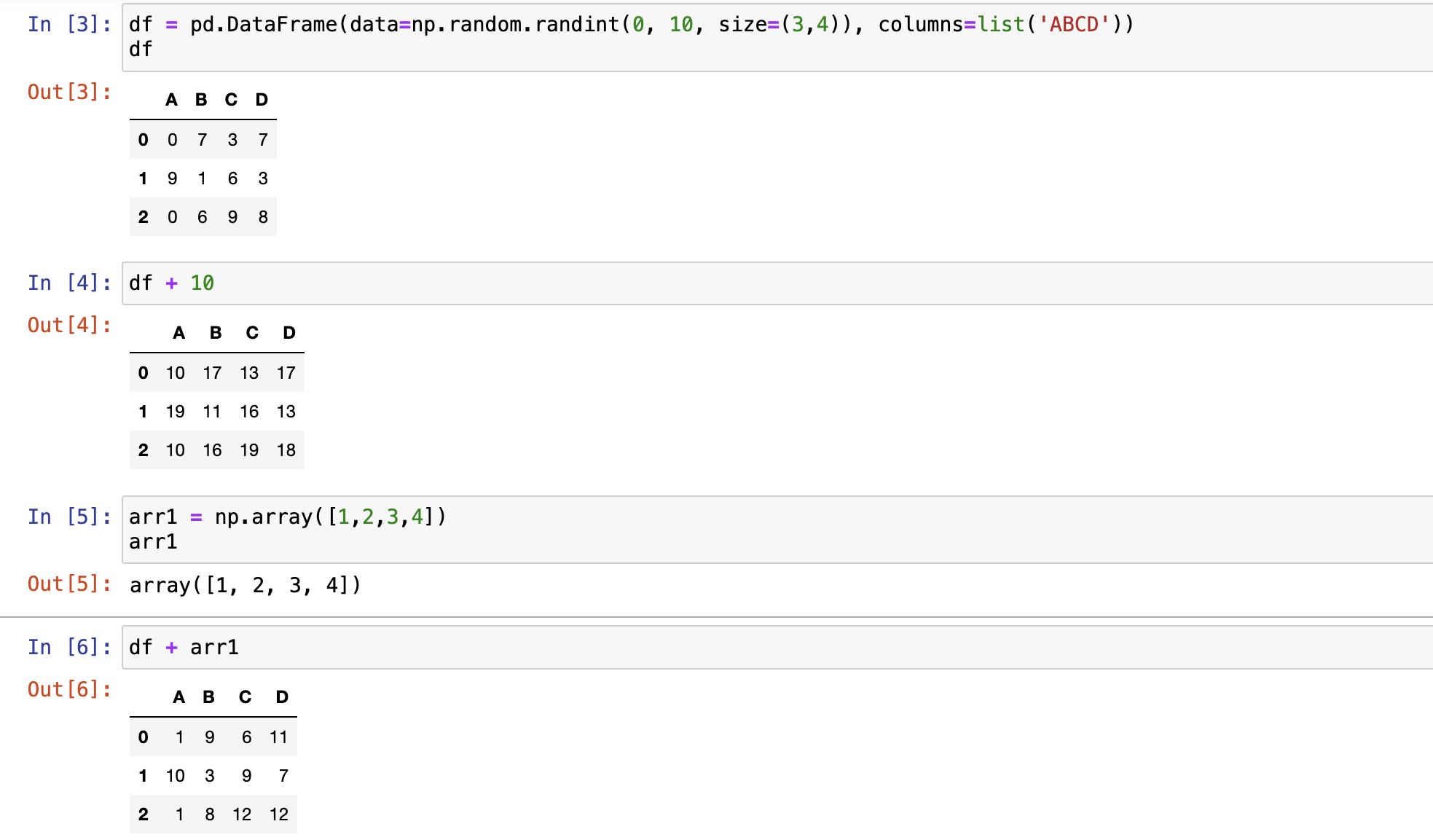
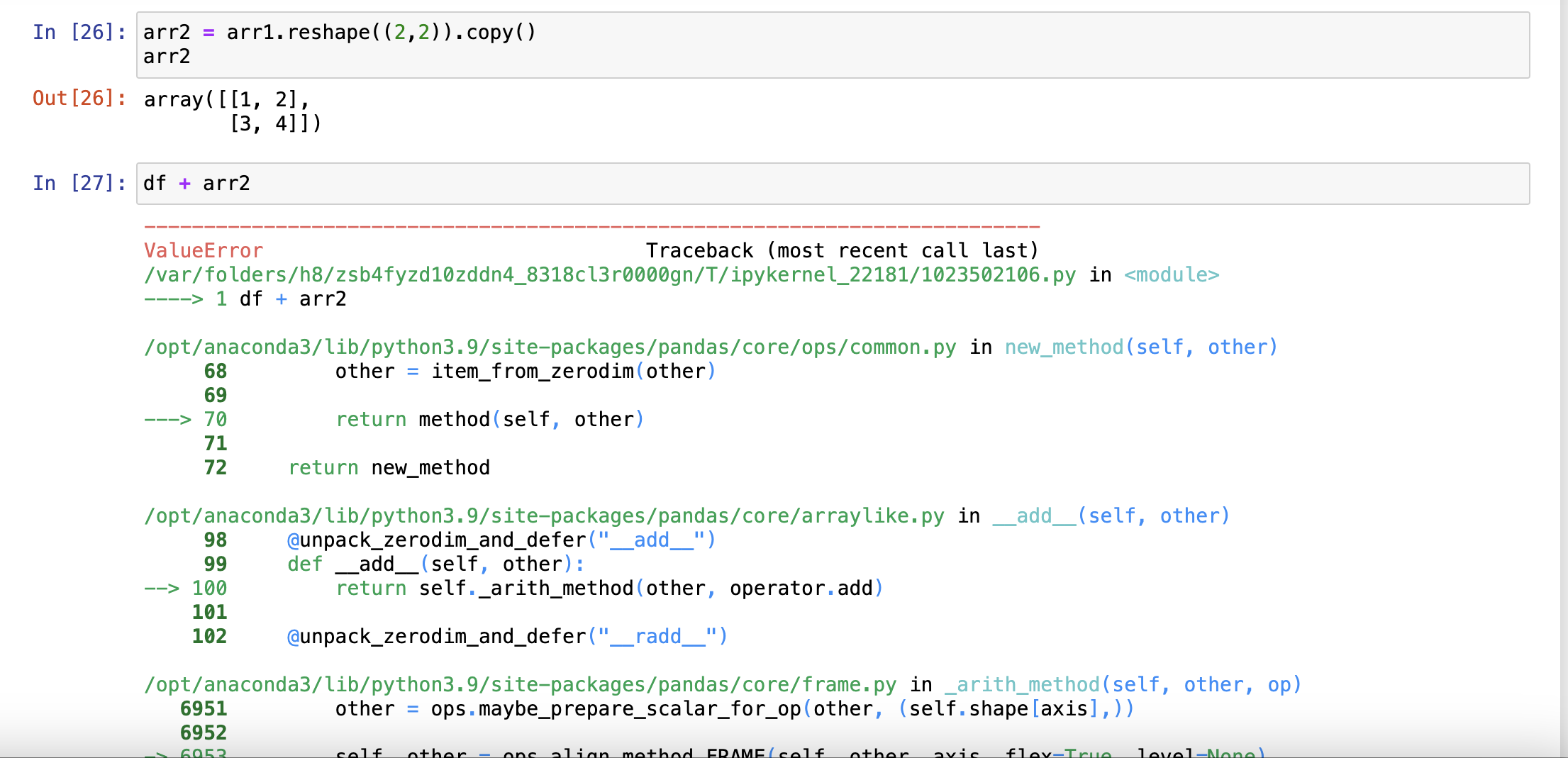
与非pandas对象运算
- 要求符合广播机制,不符合就报错
与Series对象运算
- 索引对齐原则,
- 默认按列索引对齐,对不齐就补nan

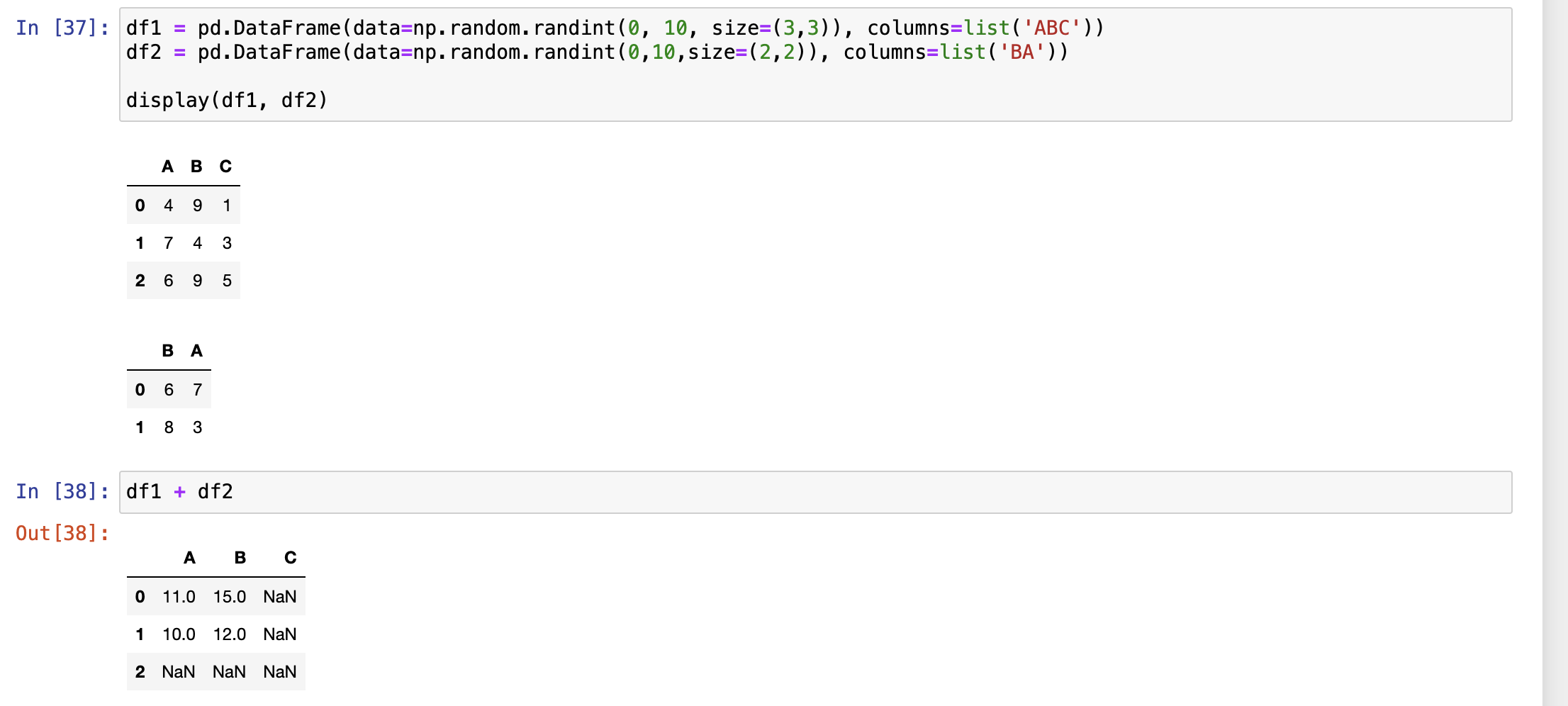
与DataFarme对象运算
- 索引对齐原则
- 行列索引同时对齐,对不齐就补nan
- 要想按行索引对齐
- 转置
- 使用add/sub/mul/div函数,并可通过
fill_value处理空值 - fill_value不自持Series和DataFrame的运算
Python操作符与pandas操作函数对应表
| Python Opration | Pandas Function |
|---|---|
| + | add() |
| - | sub() , subtract() |
| * | mul() , multiply() |
| / | truediv(), div() divide() |
| // | floordiv() |
| % | mod() |
| ** | pow() |
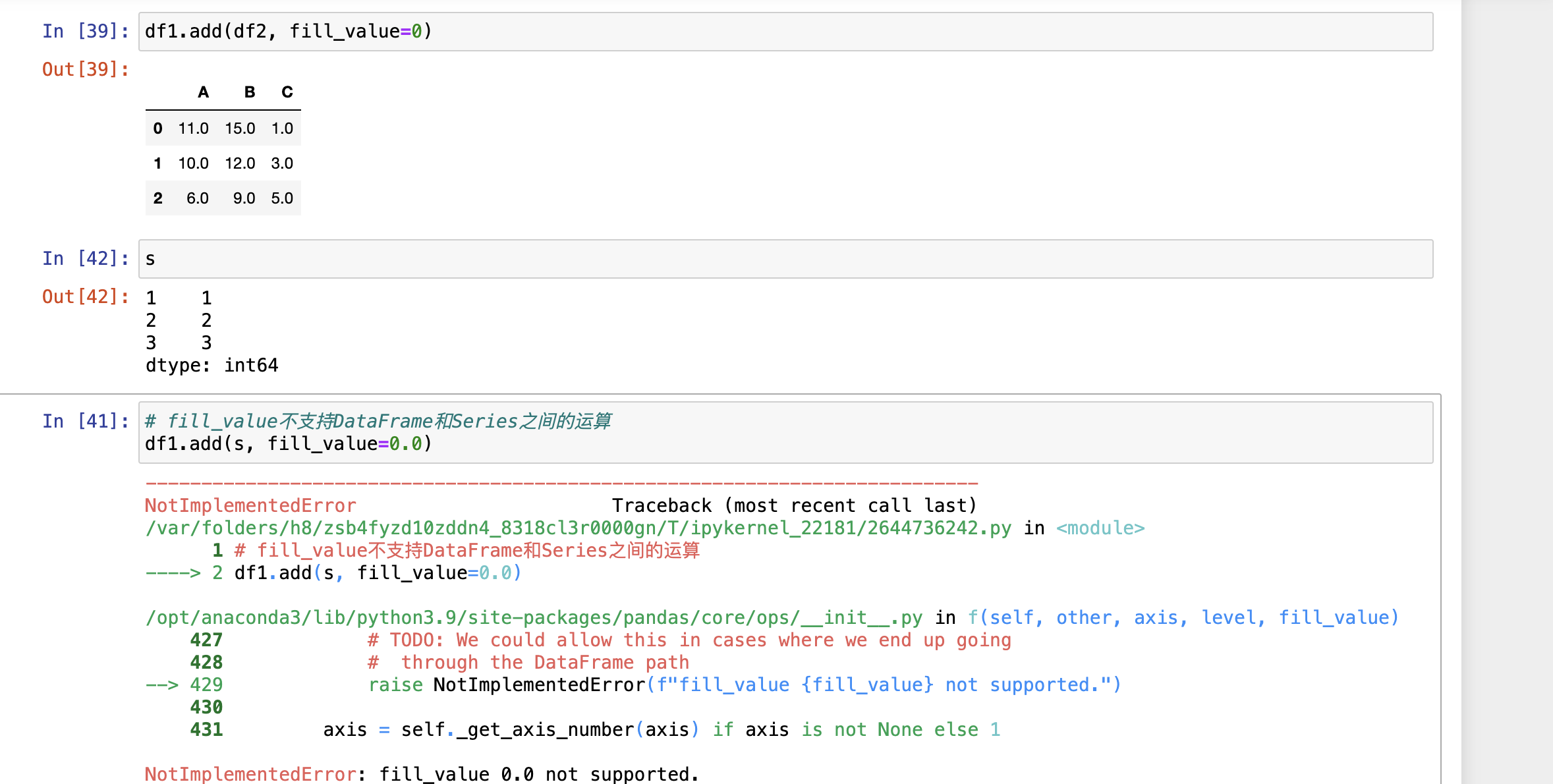
NumPy Functions
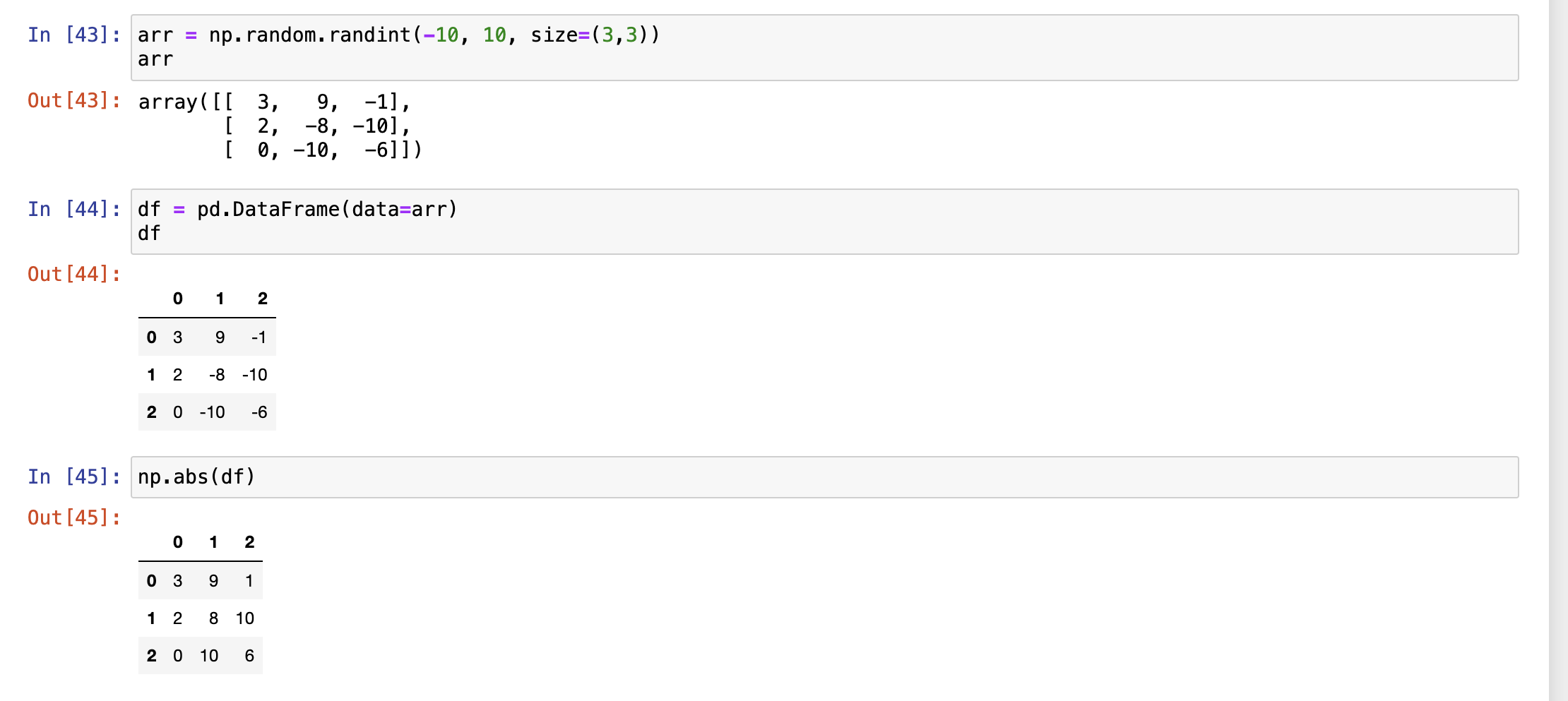
转置运算
Pandas访问
Basics标准访问形式
| Object Type | Index |
|---|---|
| Series | s.loc[index] |
| DataFrame | df.loc[row_index,column_index] |
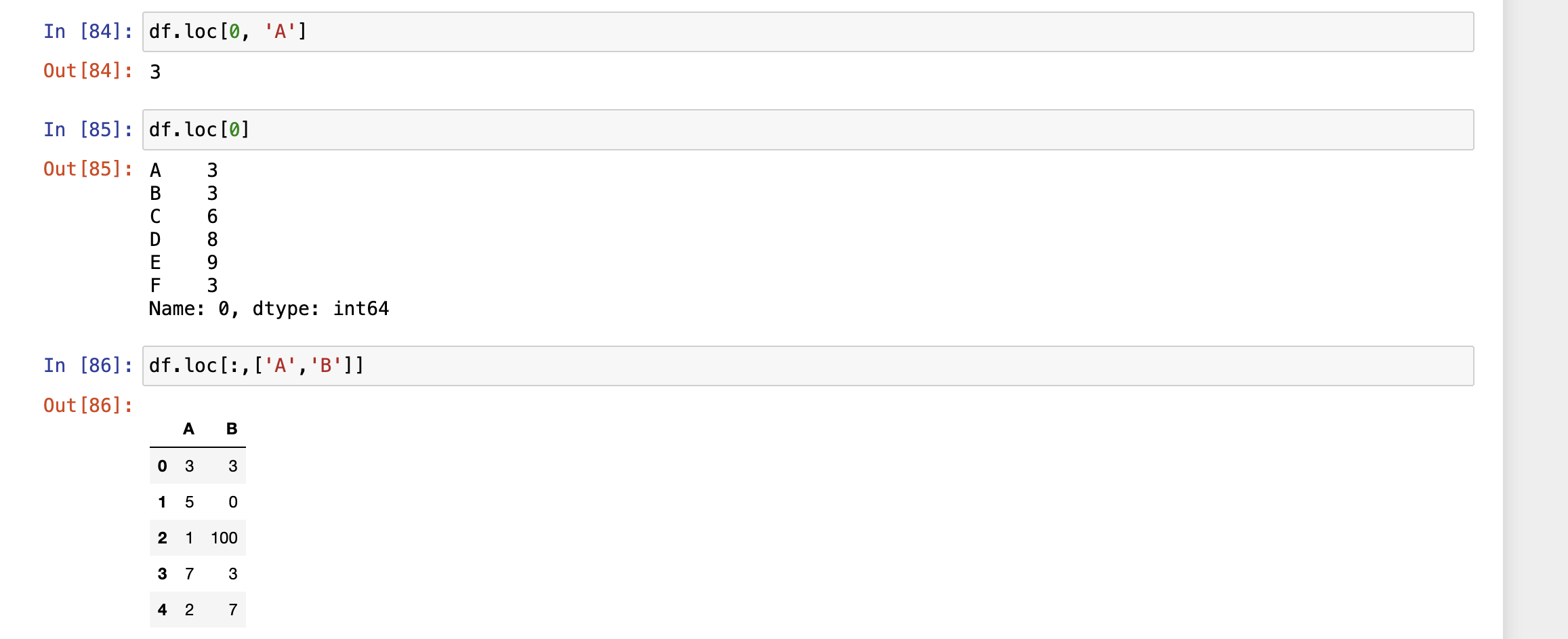
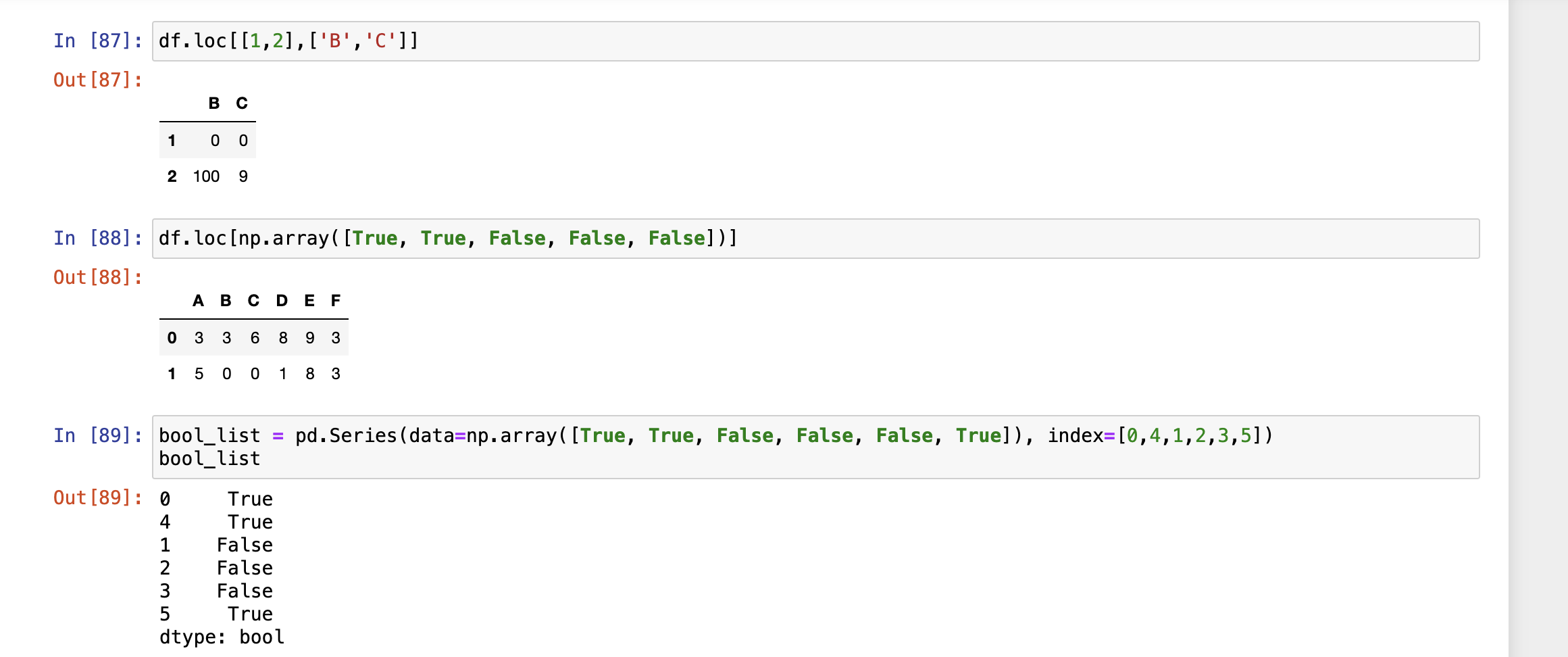
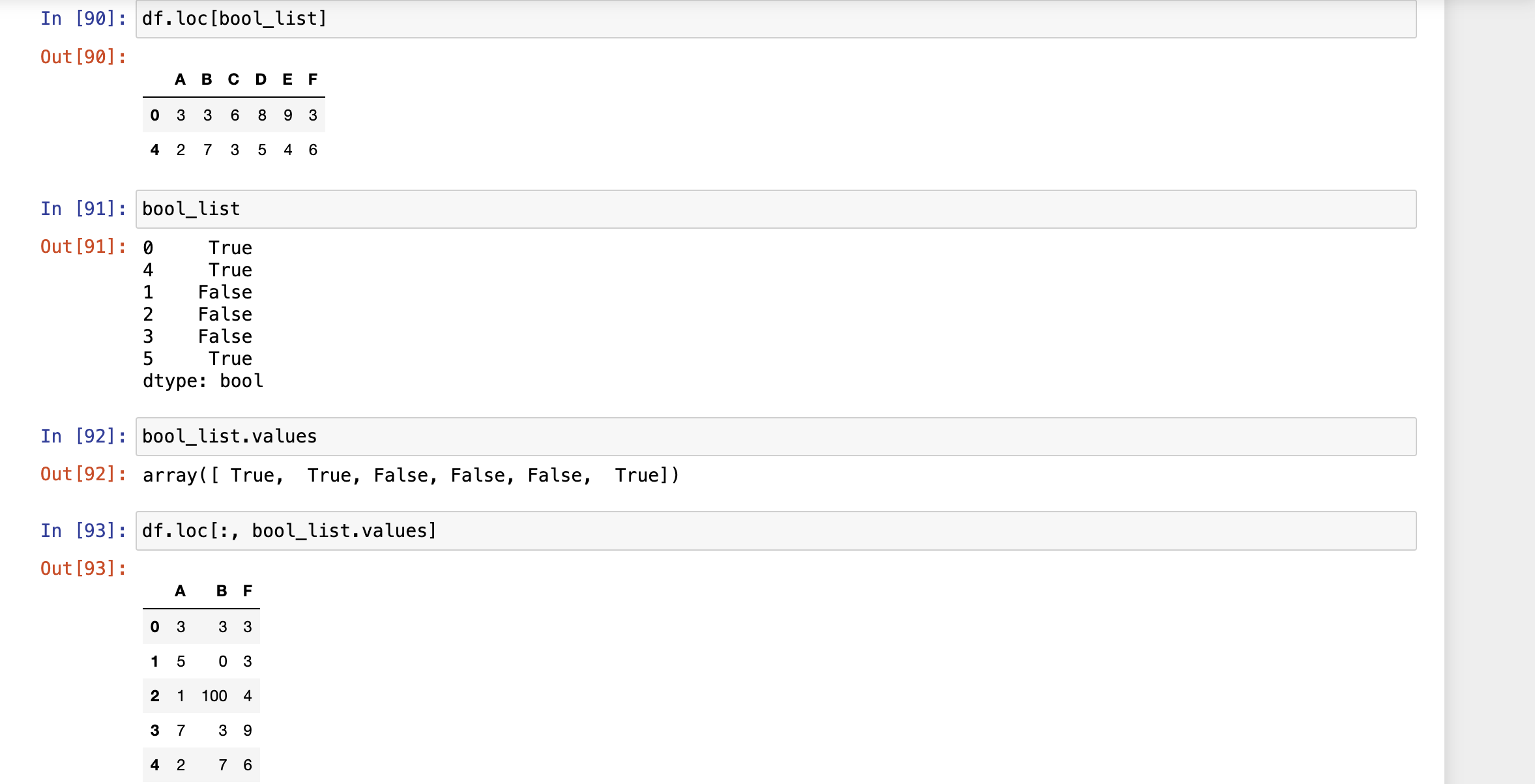
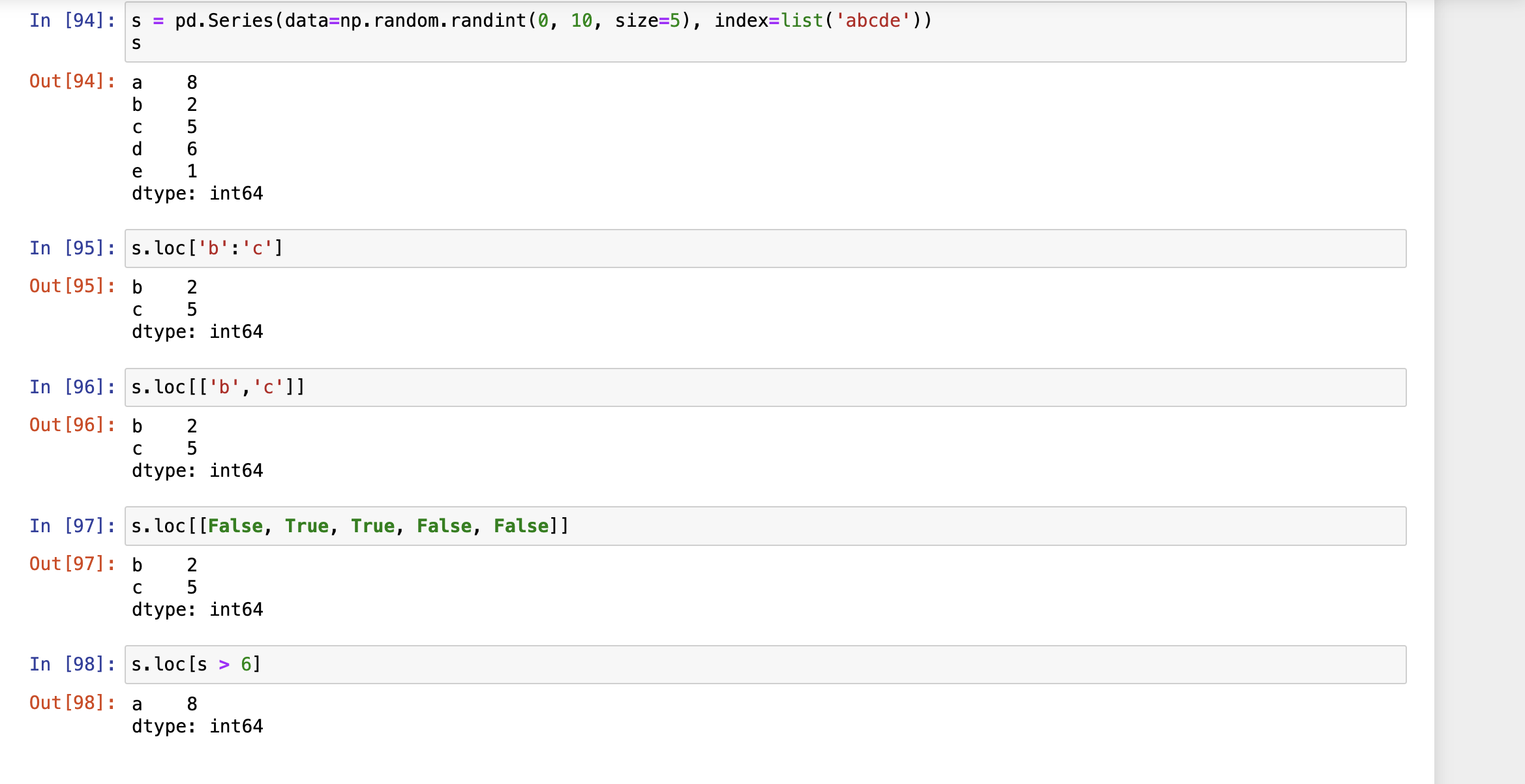
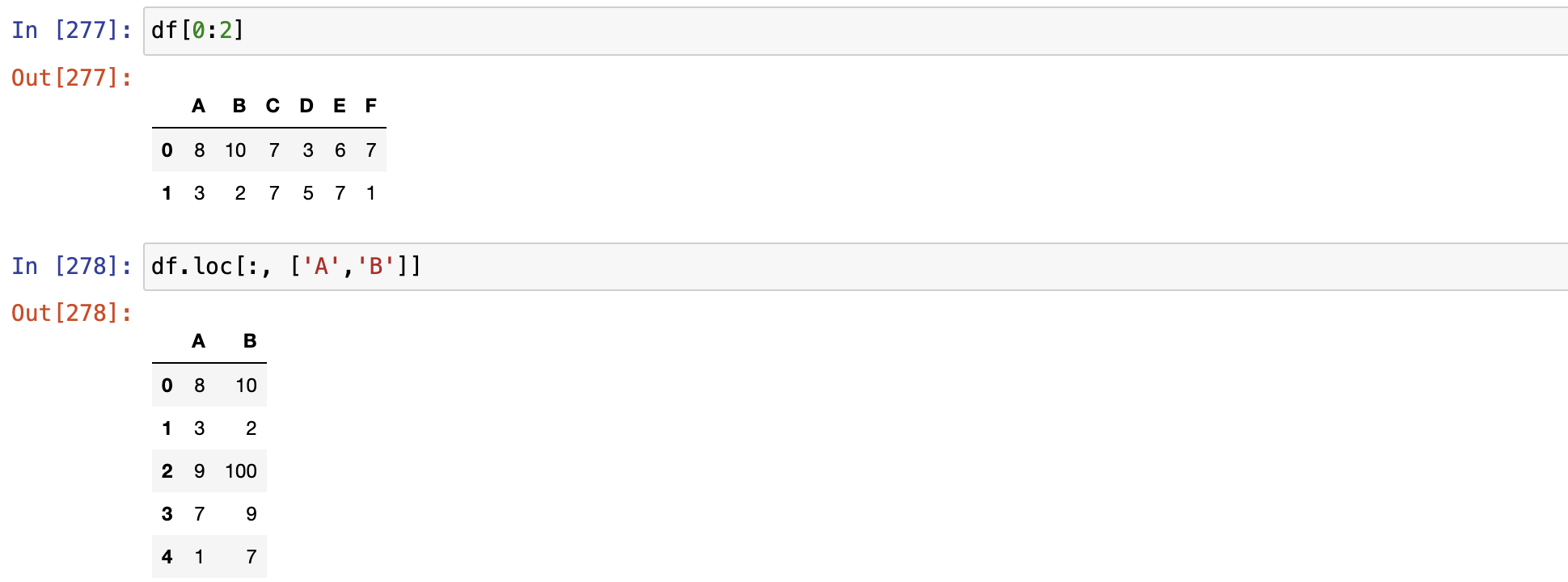
loc[] 显示访问:在pandas对象中,可以使用标签的形式访问数据
iloc[] 隐式访问:在pandas对象中,也可以使用index的形式访问数据
index可以是:
- 索引
- 索引列表
- BOOL列表
- 切片
- 条件表达式
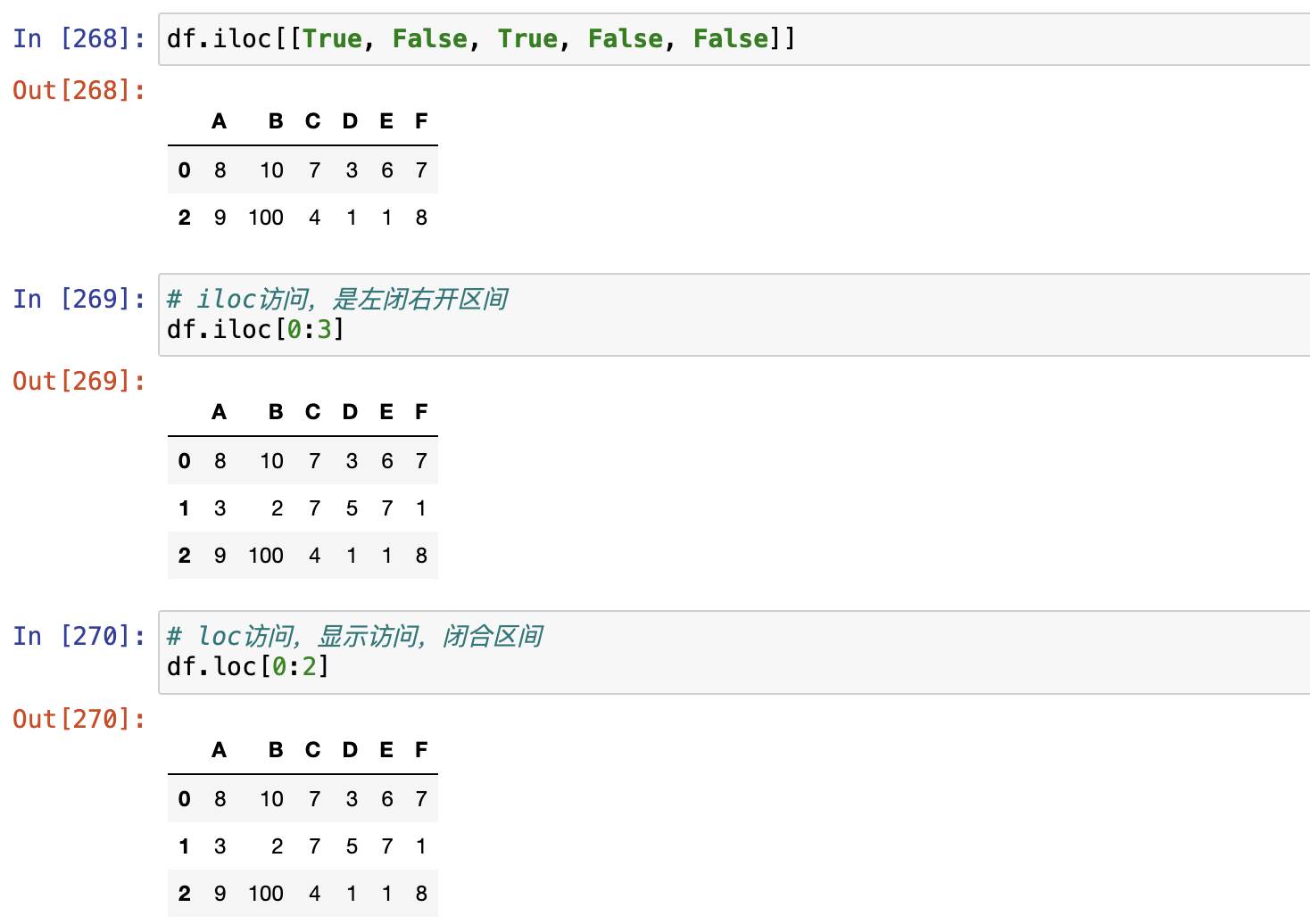
显示访问,使用Labels访问,loc[]
索引切片时,左闭右开区间
标签切片时,左右闭合区间
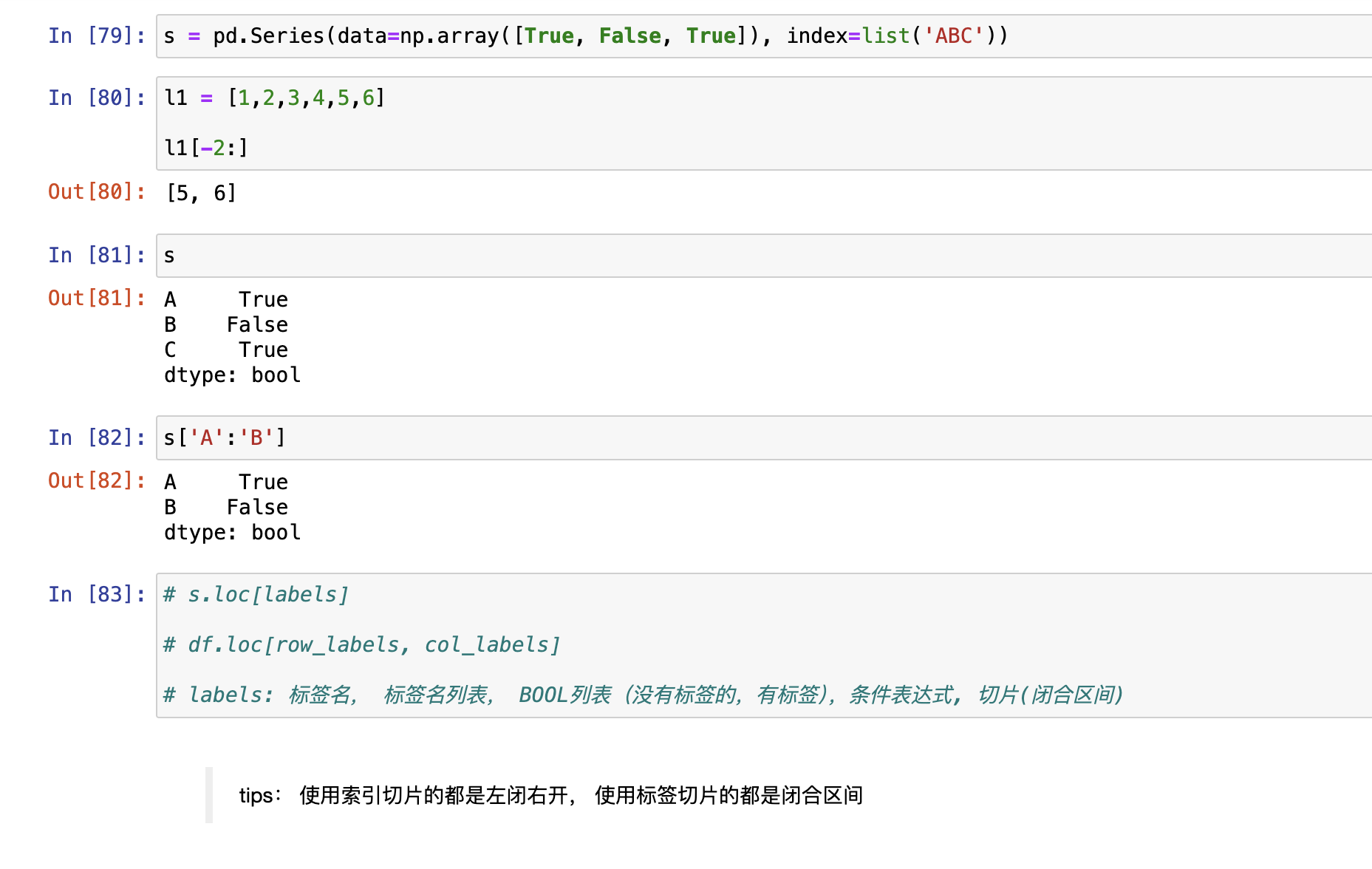
隐式访问,使用indexies访问,iloc[]
- index:每个元素距离首位地址的偏移量
series.iloc[index]
dataframe.iloc[row_index,column_index]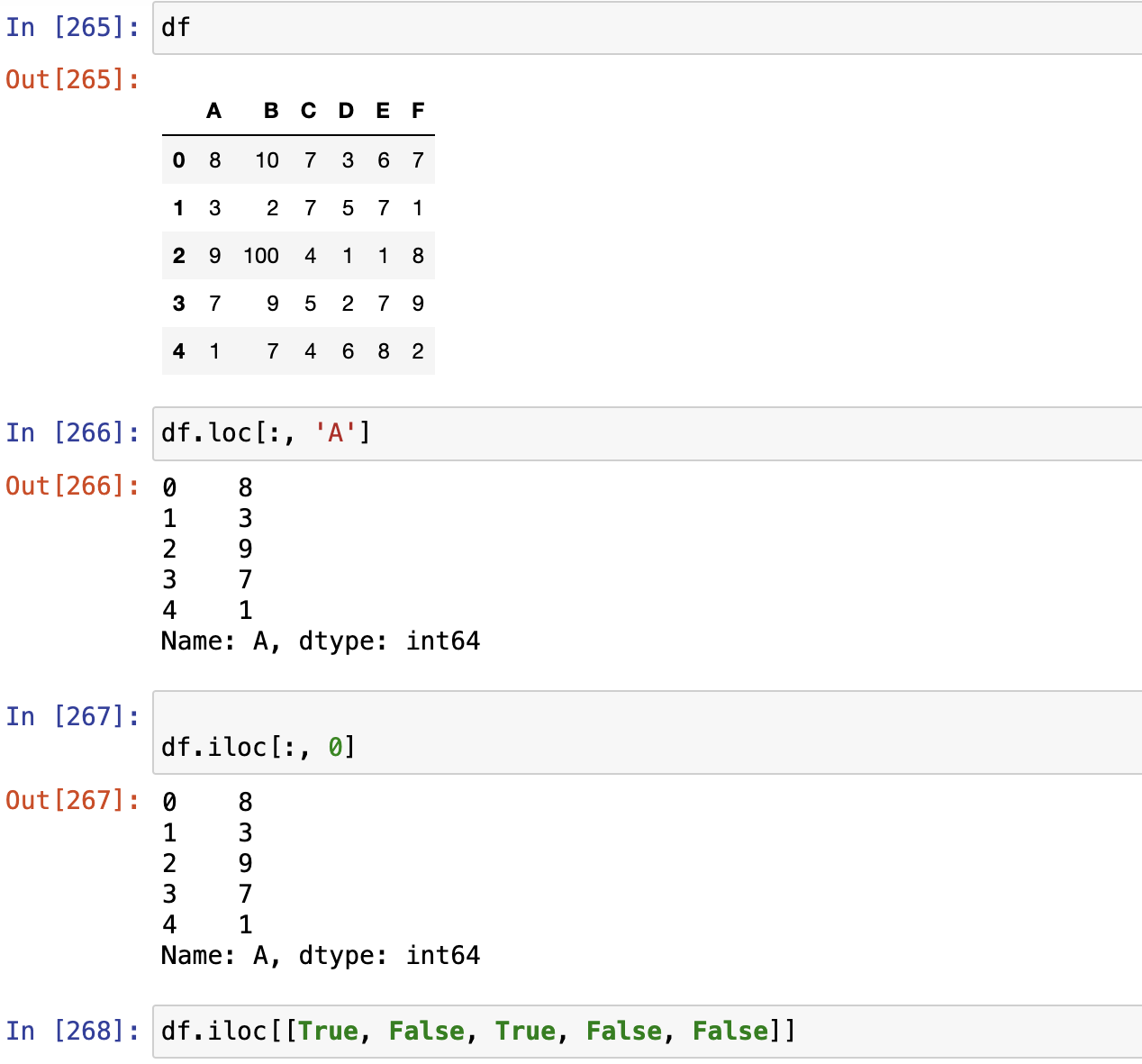
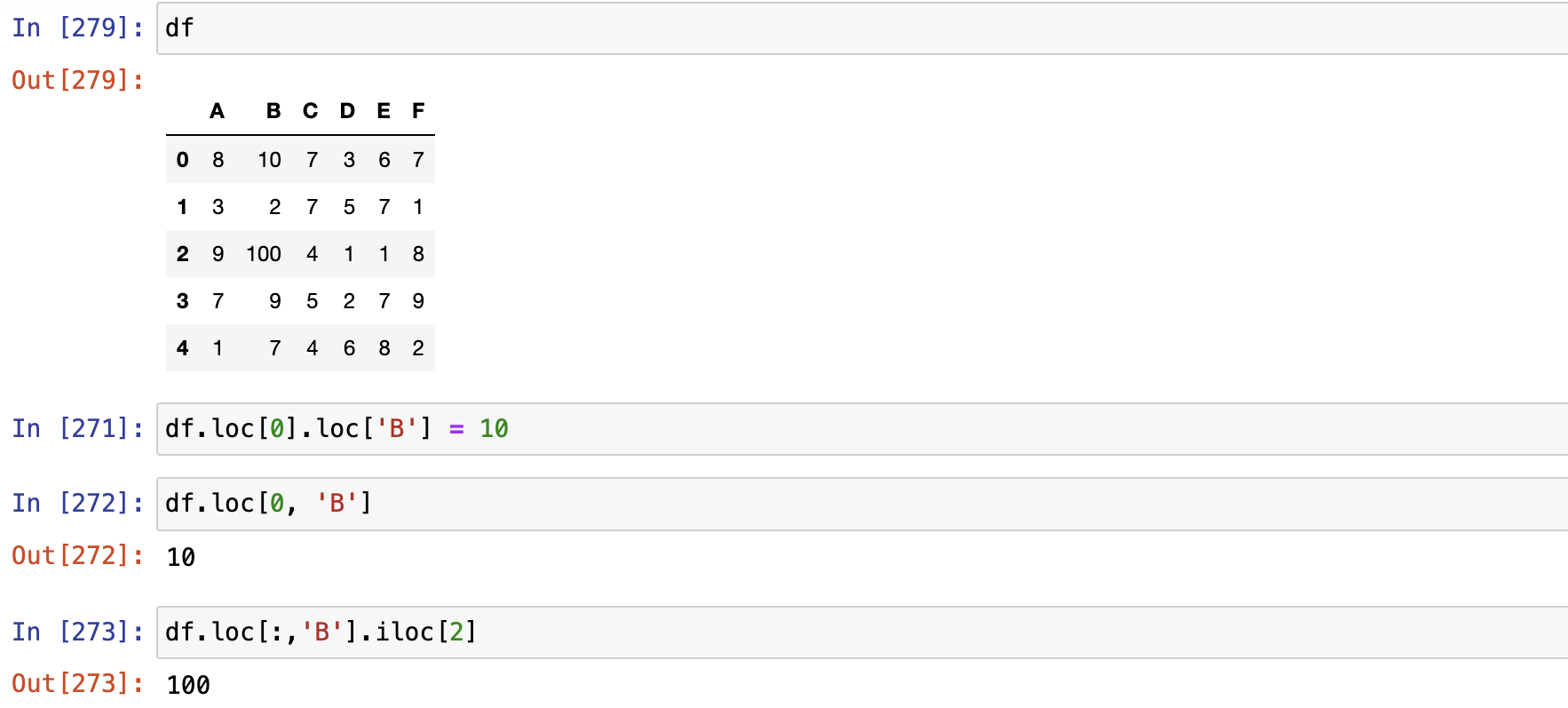
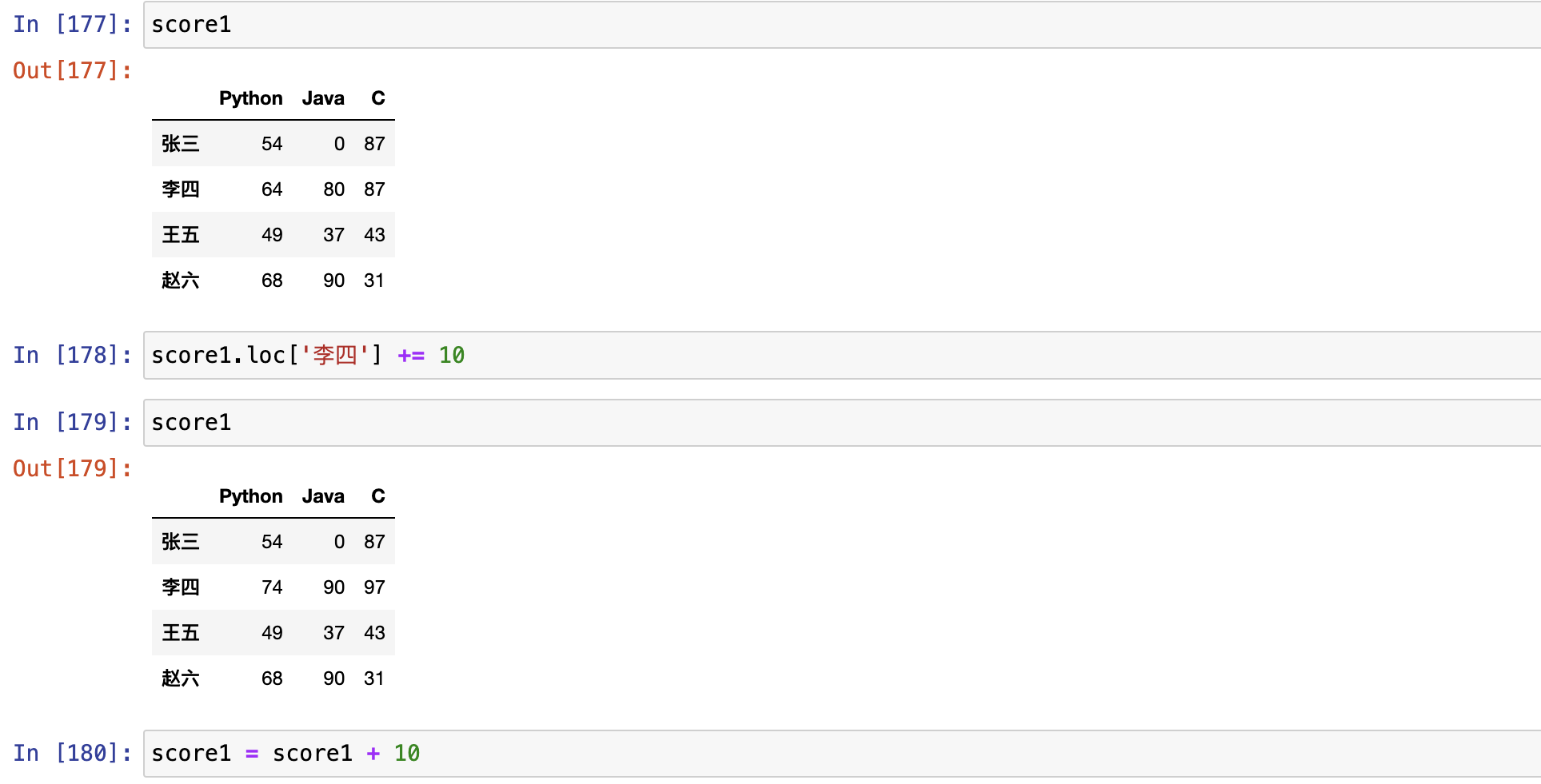
间接访问(禁止!!!)
- 会让程序不知道访问的到底是df对象,还是切片对象,存在安全风险
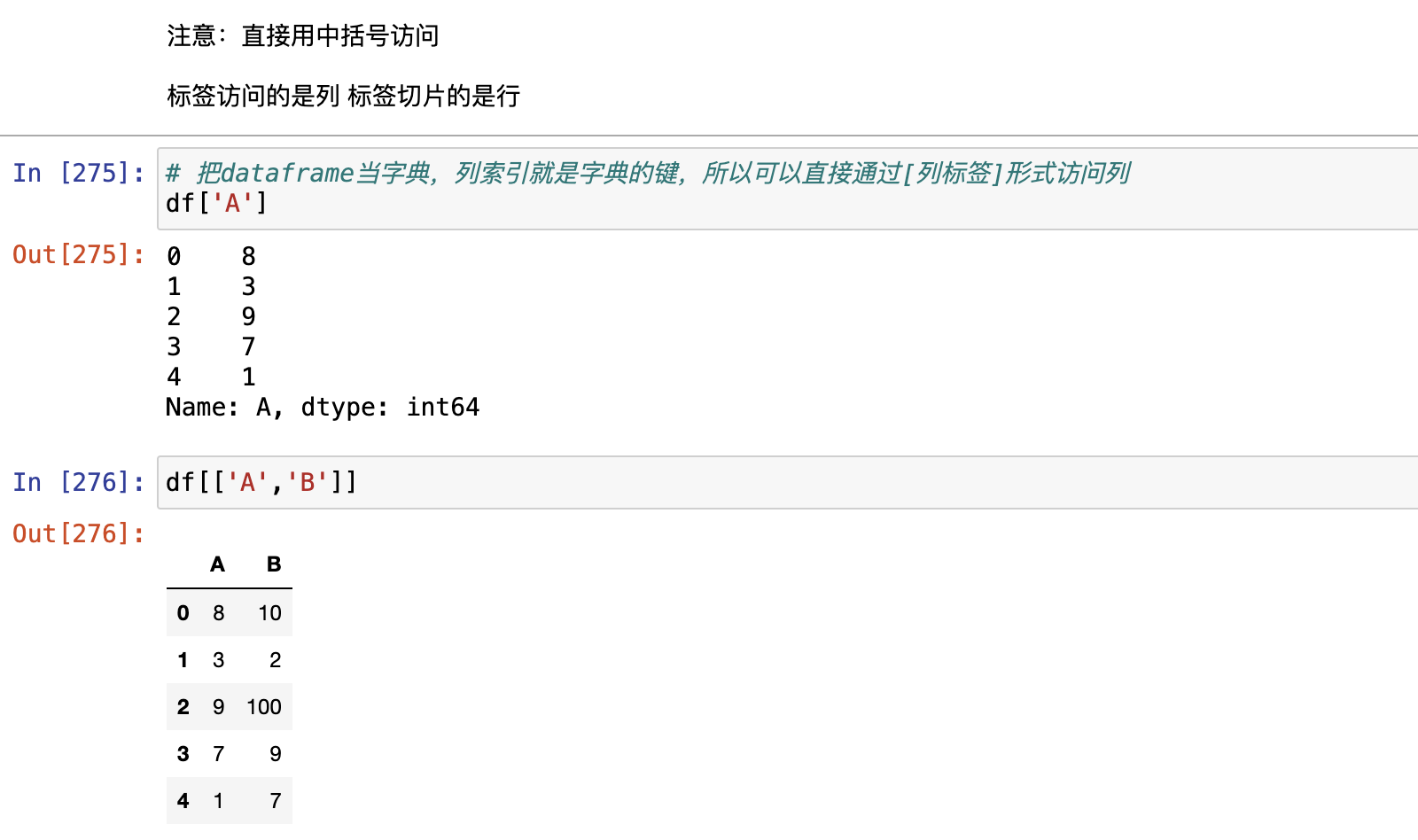
- Dataframe可以看成是Series组成的字典
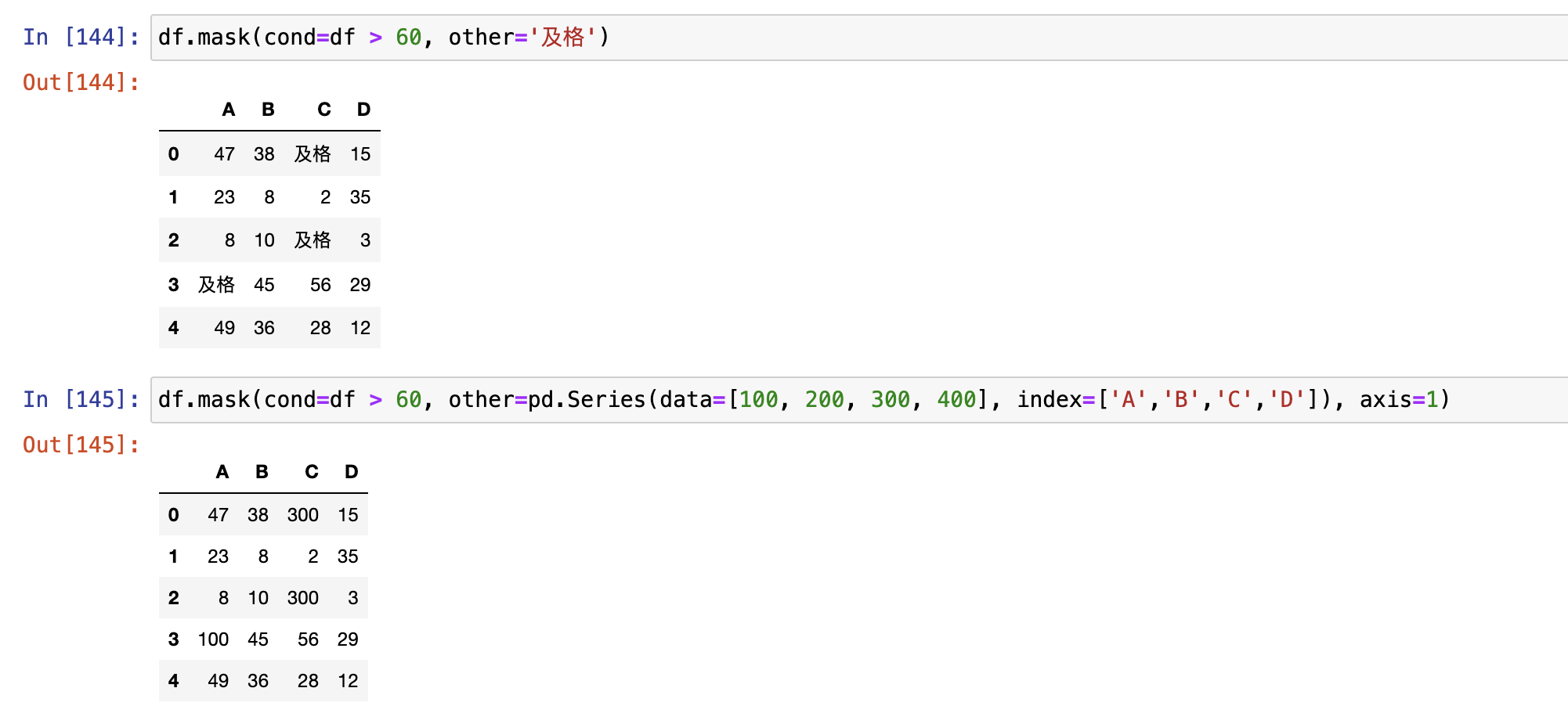
Pandas高级查找
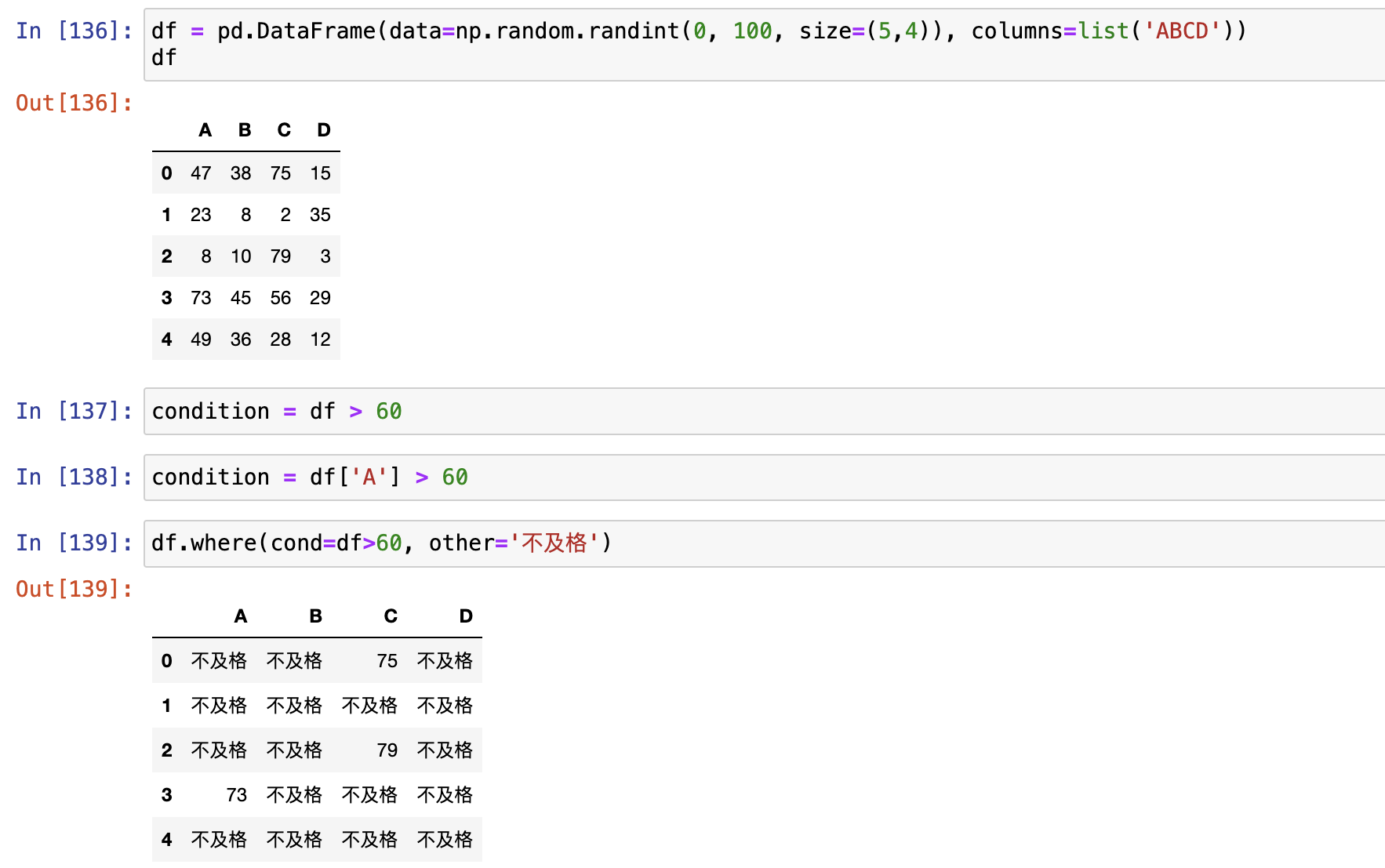
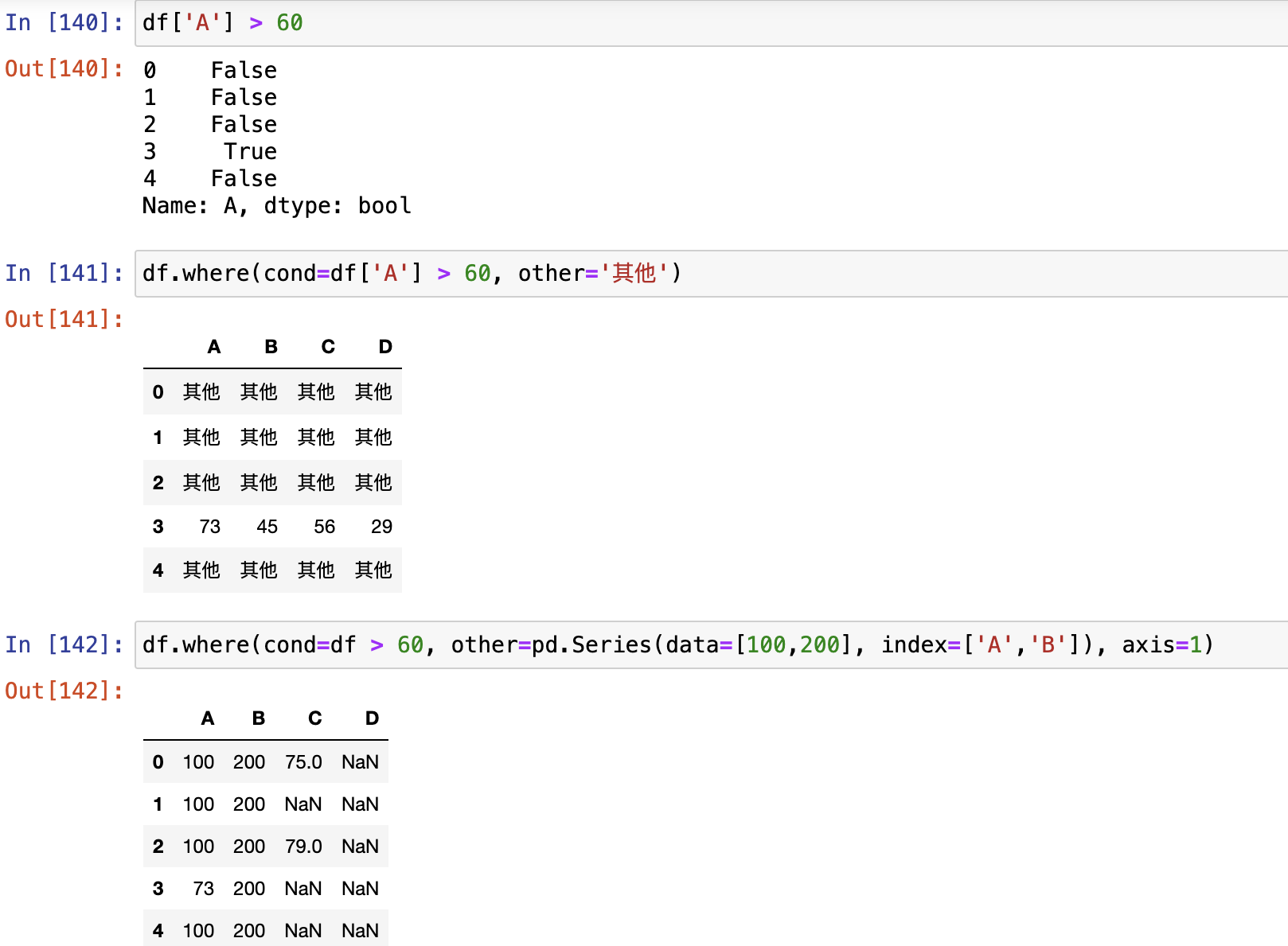
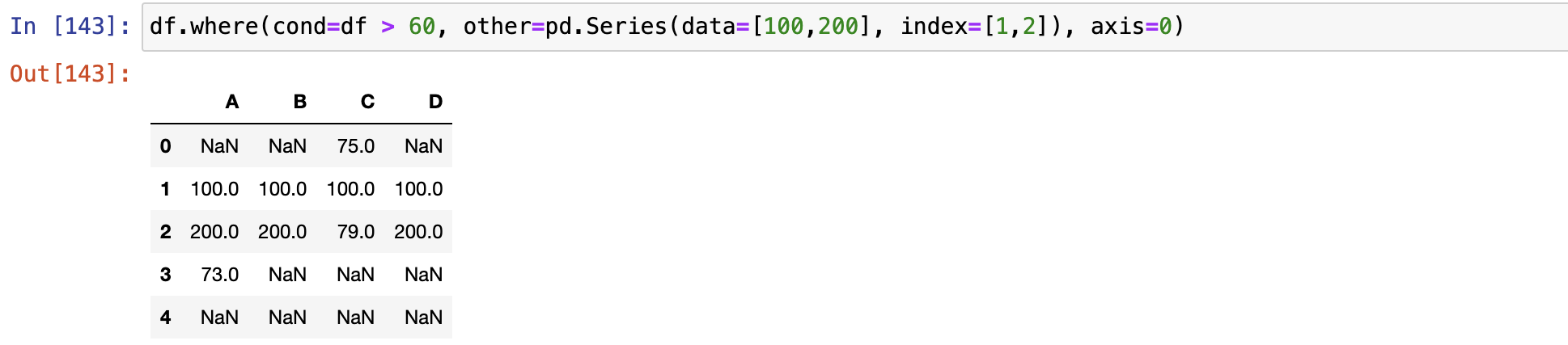
where()和 mask()
- where():满足con条件的保留,其他用other填充
- mask():不满足con条件的保留,其他用other填充
where()
mask()
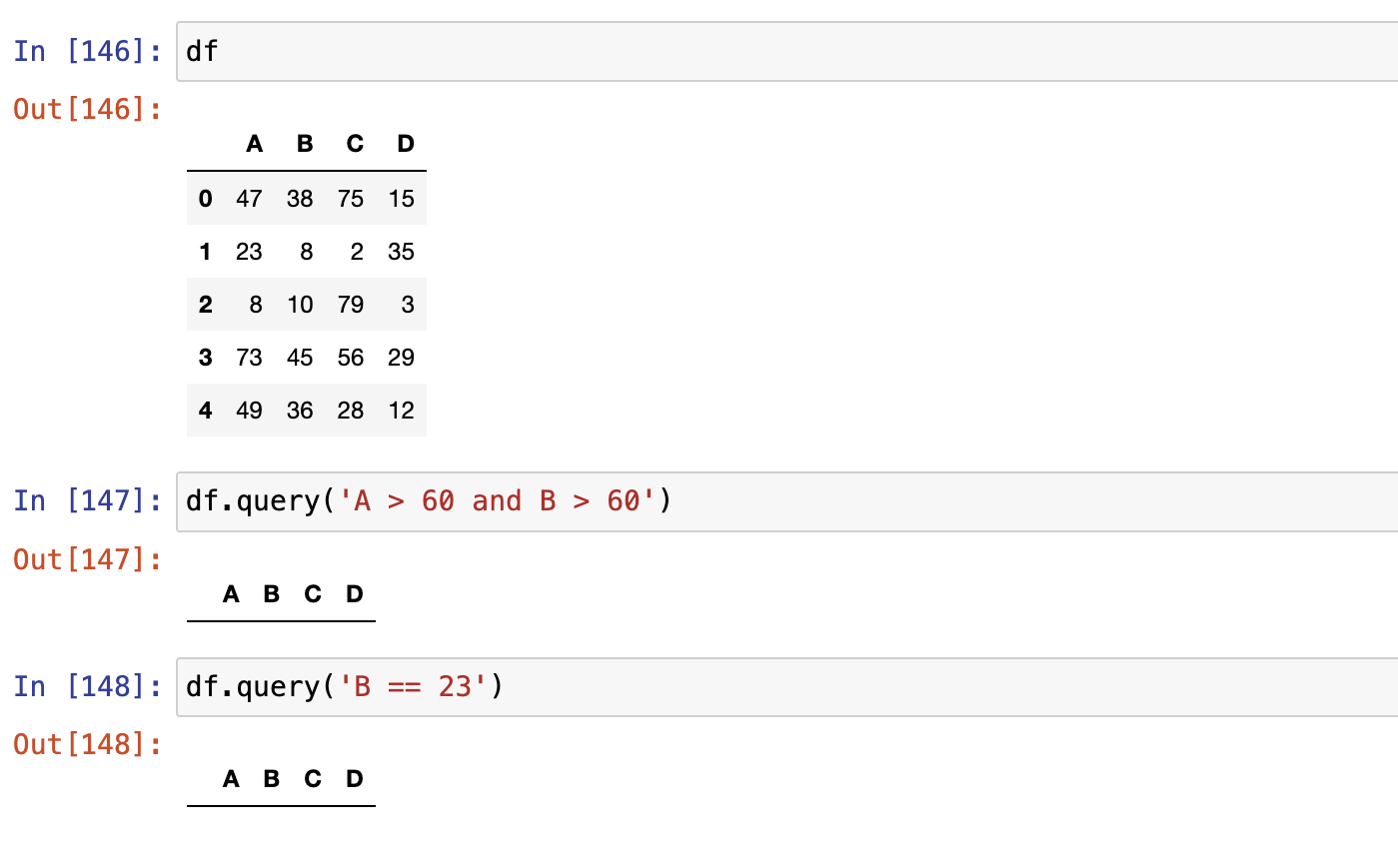
query()
- query()不会用写df名字,直接写字段名就行
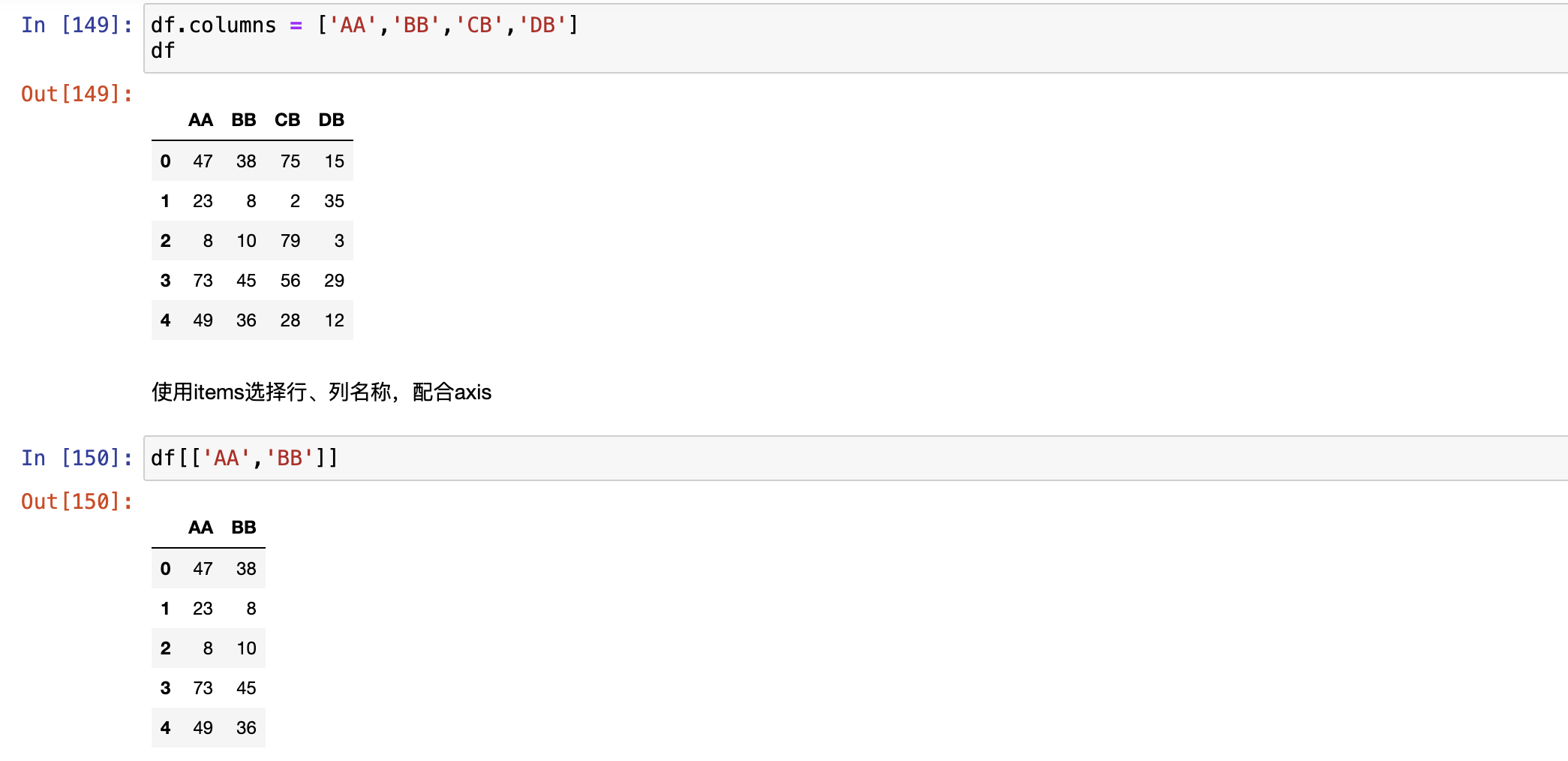
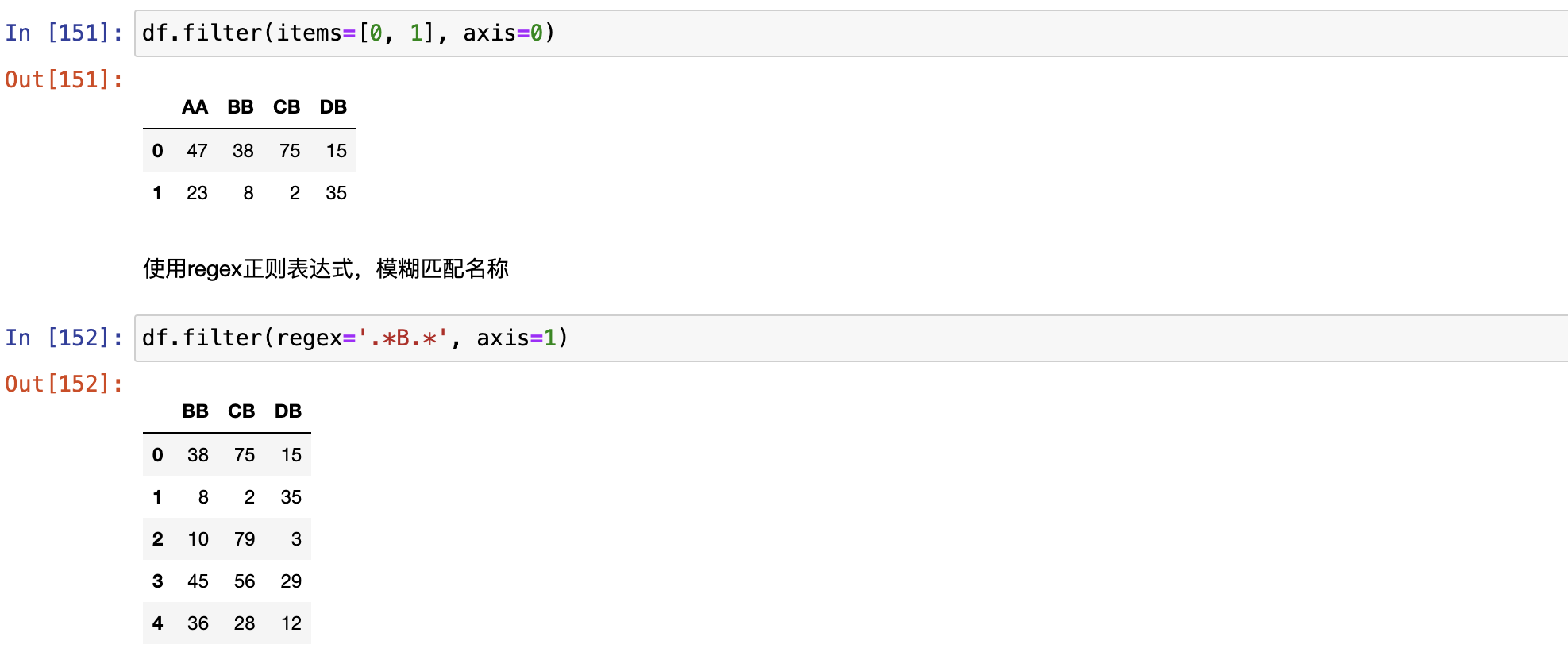
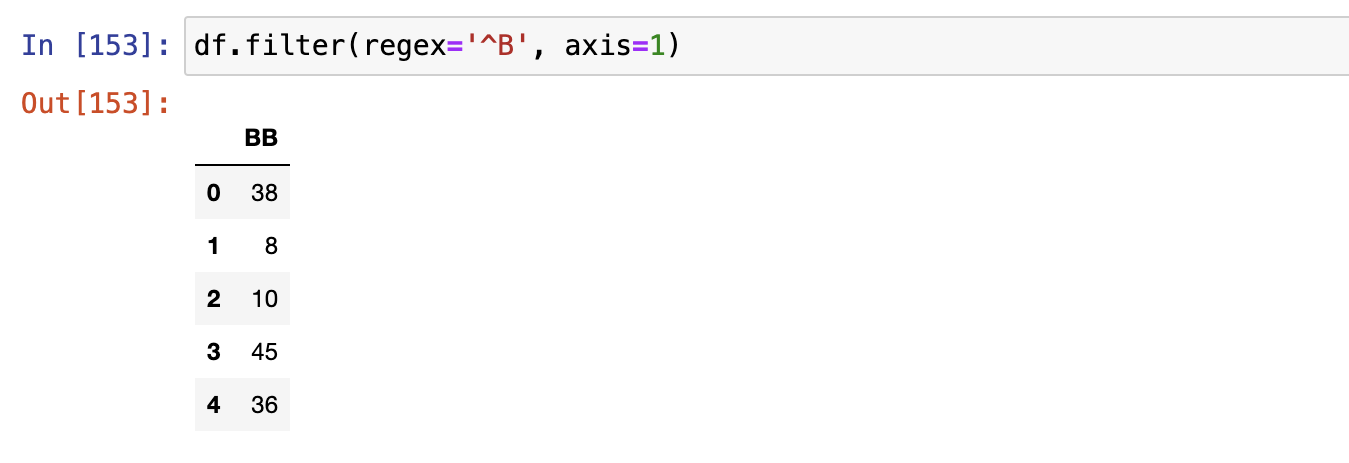
filter() + 正则
对行名和列名进行筛选
使用item选择行,列名称,配合axis
使用regex正则表达式,模糊匹配名称
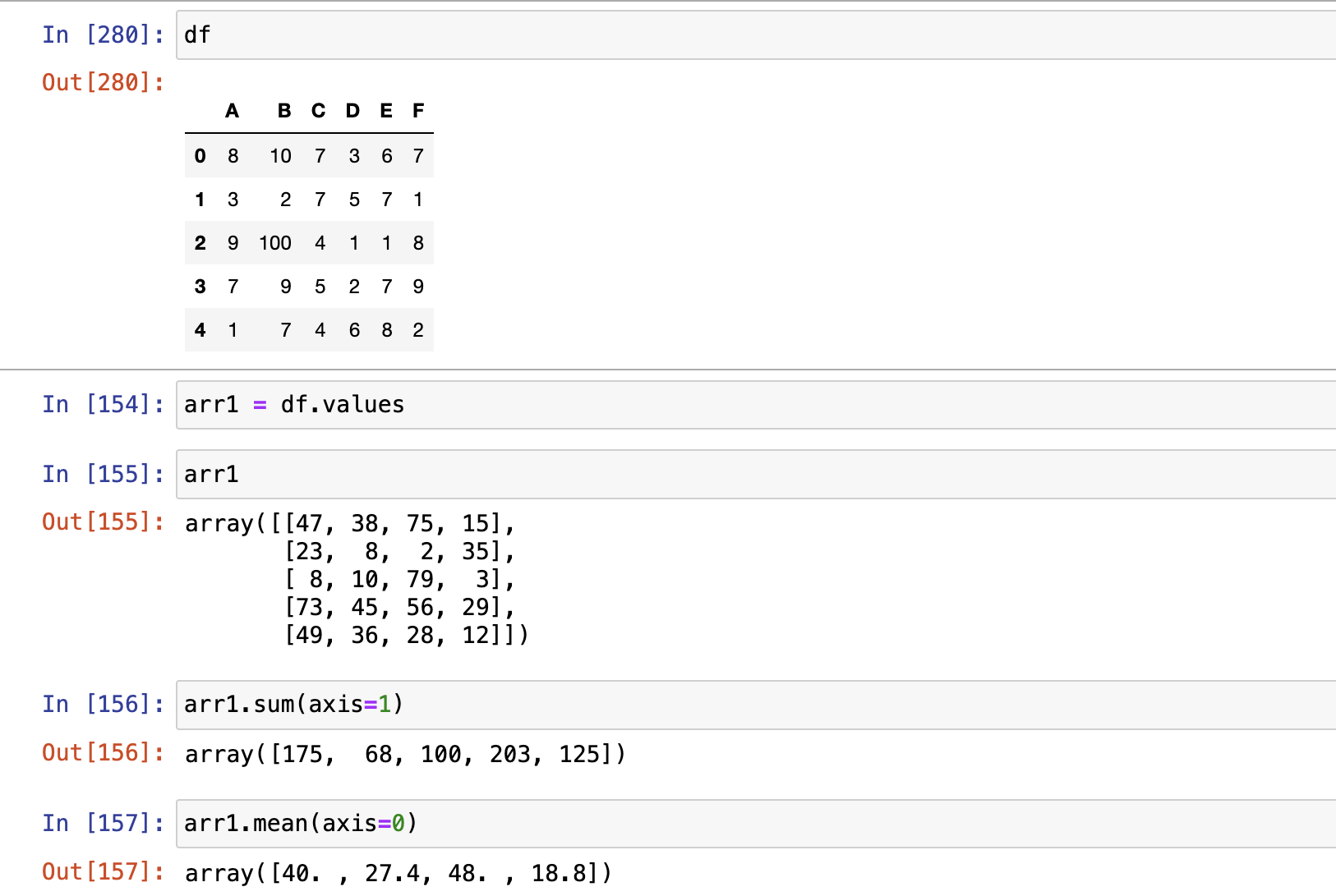
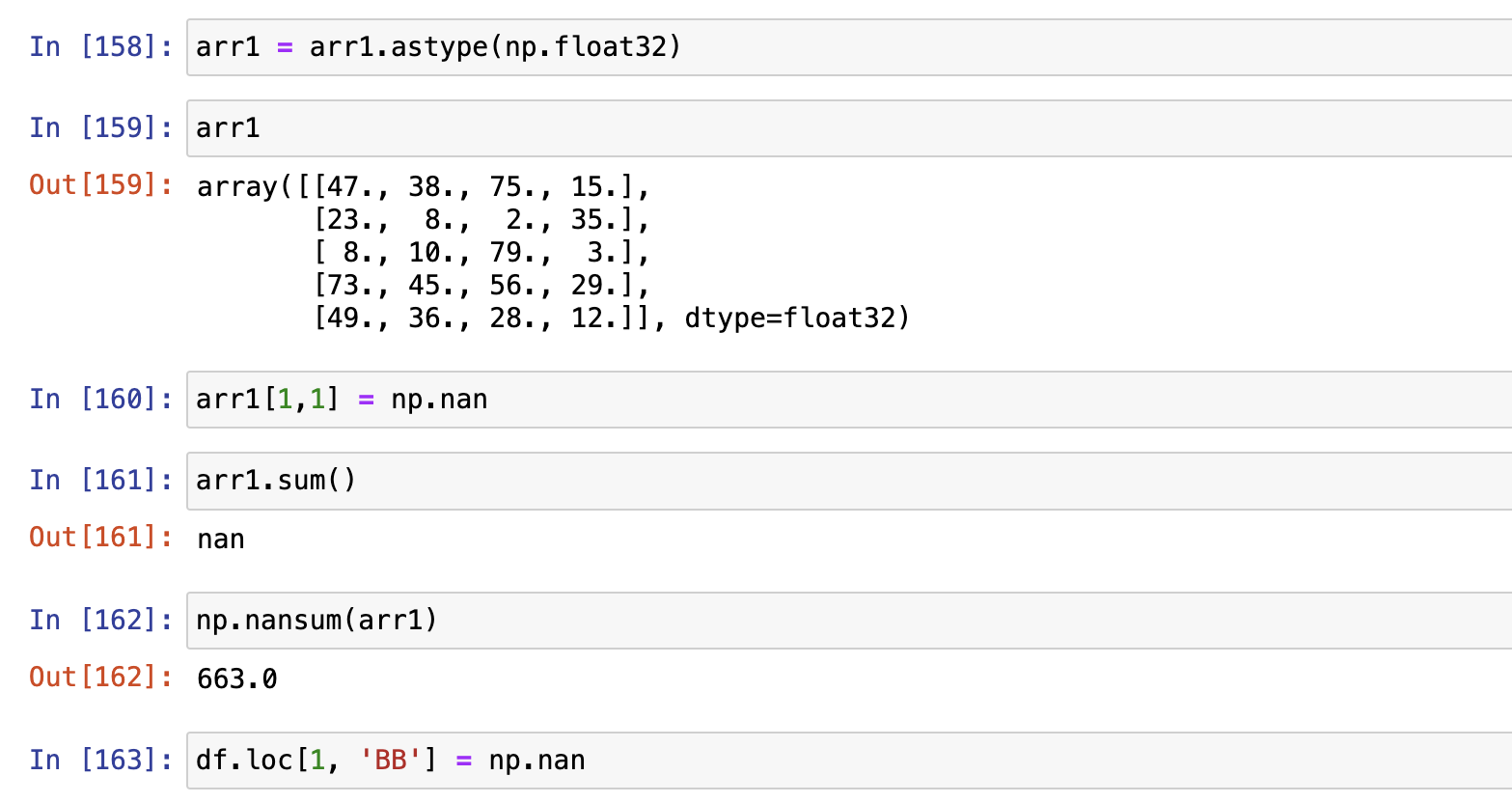
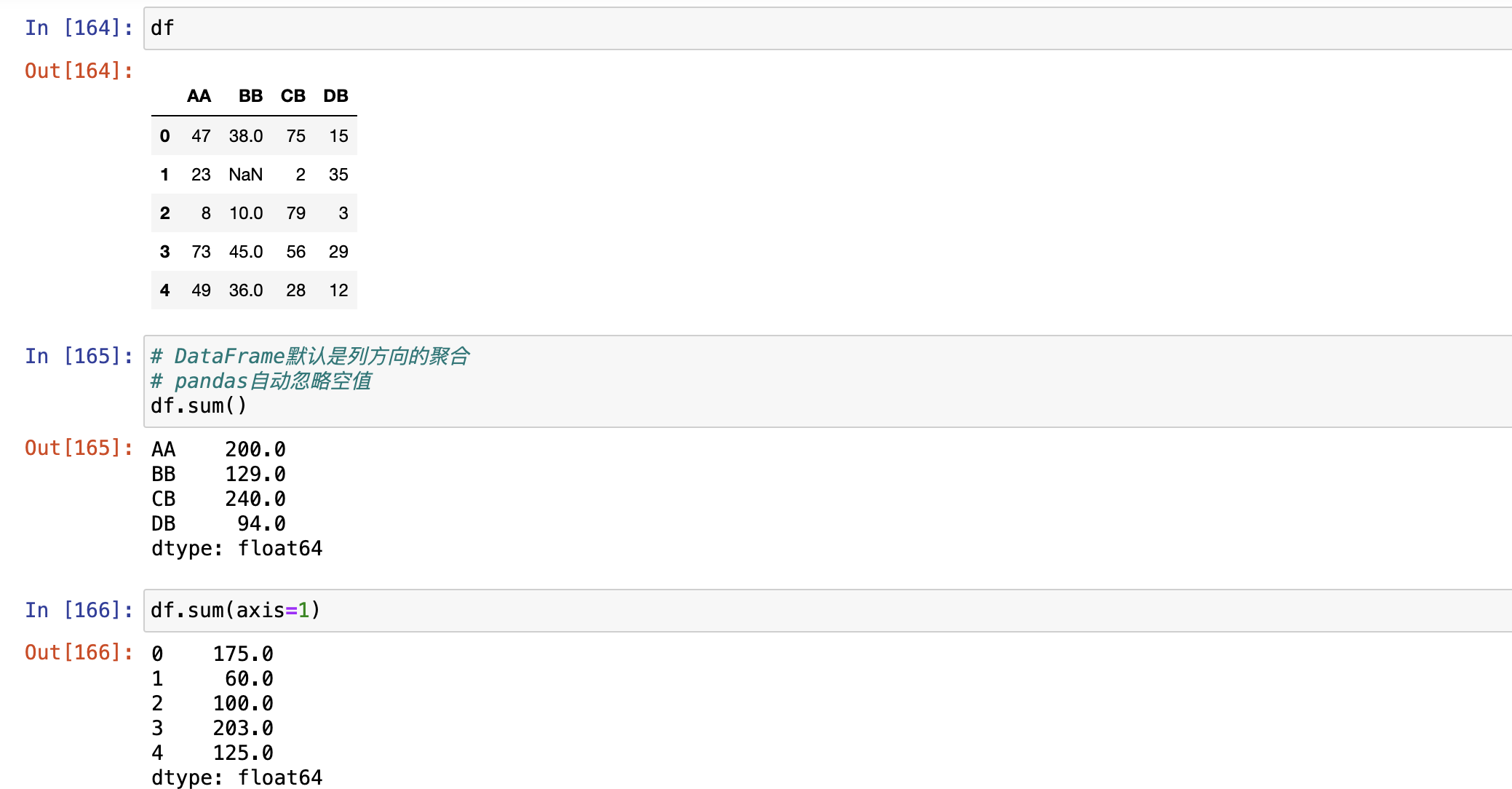
Pandas聚合操作
- DataFrame默认是列方向的聚合
- Pandas都自动忽略空值,不参与运算
| Fuction | 备注 |
|---|---|
| count | 个数 |
| sum | 求和 |
| nansum | 除了nan之外的求和 |
| cumsum | 累加 |
| mean | 平均 |
| mad | 绝对值均值 |
| median | 中位数 |
| min | 最小值 |
| max | 众数 |
| abs | 绝对值 |
| prod | 乘积 |
| cumprod | 累积 |
| std | 标准差 |
| var | 方差 |
| quantitle | 分位数 |

习题
背景:假设班级有 张三、李四、王五、赵六四位同学,考试要考的科目有Python、Java、C
1. 假设score1是期中考试成绩,score2是期末考试成绩,请自由创建score1和score2,并将其相加,求期中期末平均值。
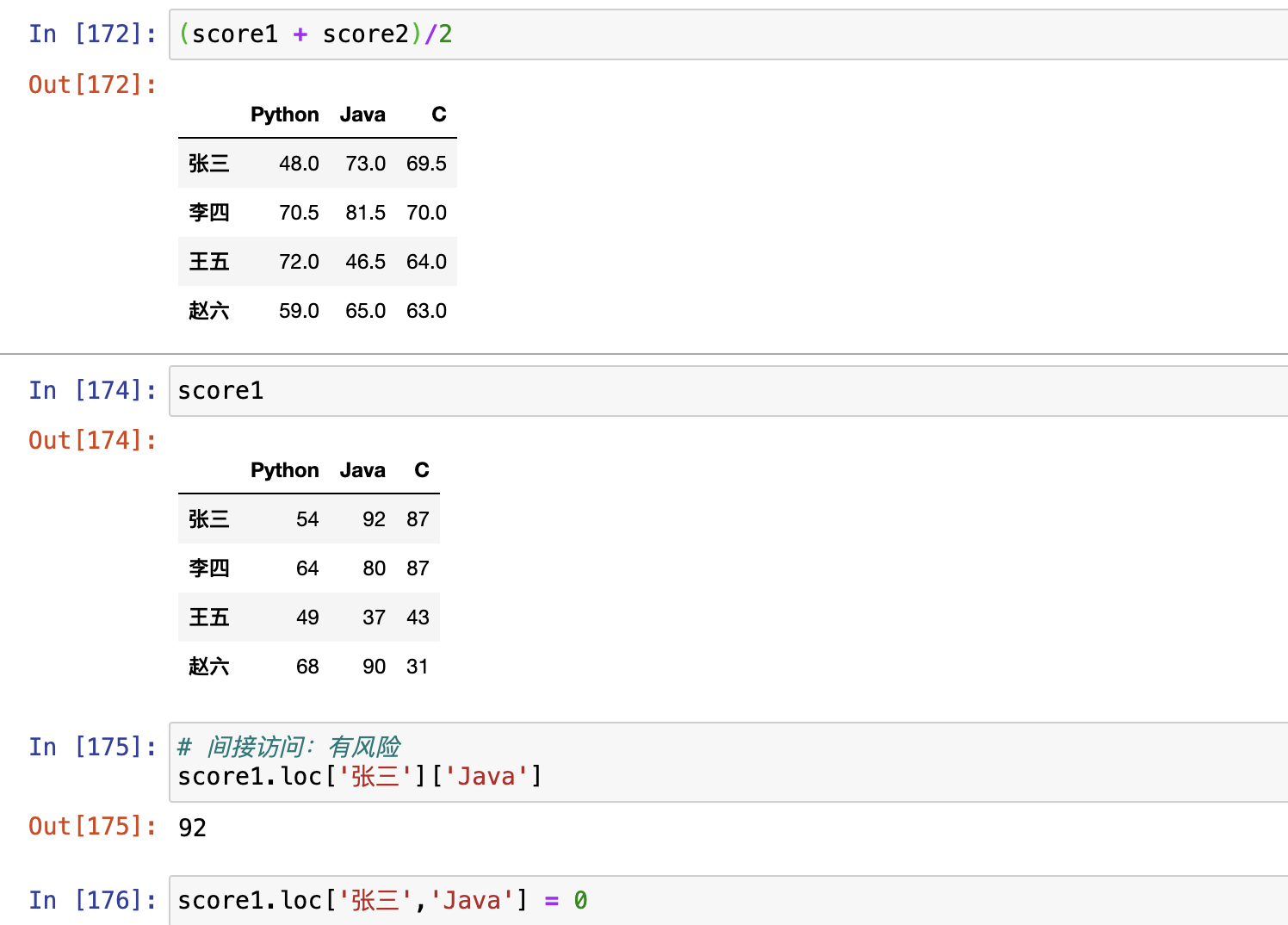
2. 假设张三期中考试Java被发现作弊,要记为0分,如何实现?
3. 李四因为举报张三作弊立功,期中考试所有科目加10分,如何实现?
4. 由于有一道题出错,要给所有学生加10分,如何实现?
5. Python老师想知道哪些同学的Java成绩比Python好,如何实现?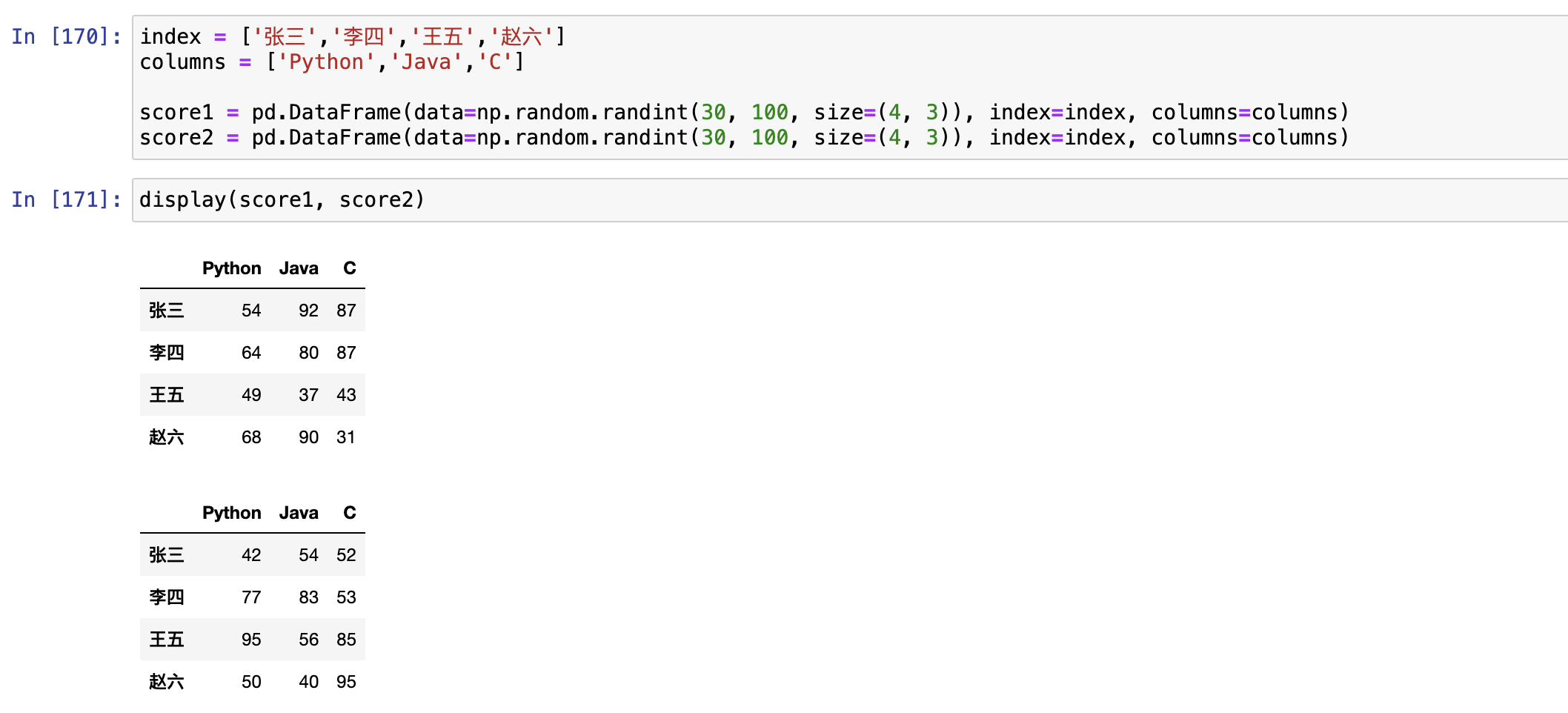

索引
单层索引
- 使用
pd.Index()可以定制索引 pd.Index()可以给索引加name
#怎么使用索引:
pd.Index是pandas提供的专门用于构造索引的类,它有很多子类,CategoricalIndex, RangeIndex
所有的子类都具备Index类的特点,比如可以使用索引访问元素
通常如果需要对索引定制(name),可以使用pd.Index系列方法来构造索引
如果没有特殊需求,使用普通的列表完全没有问题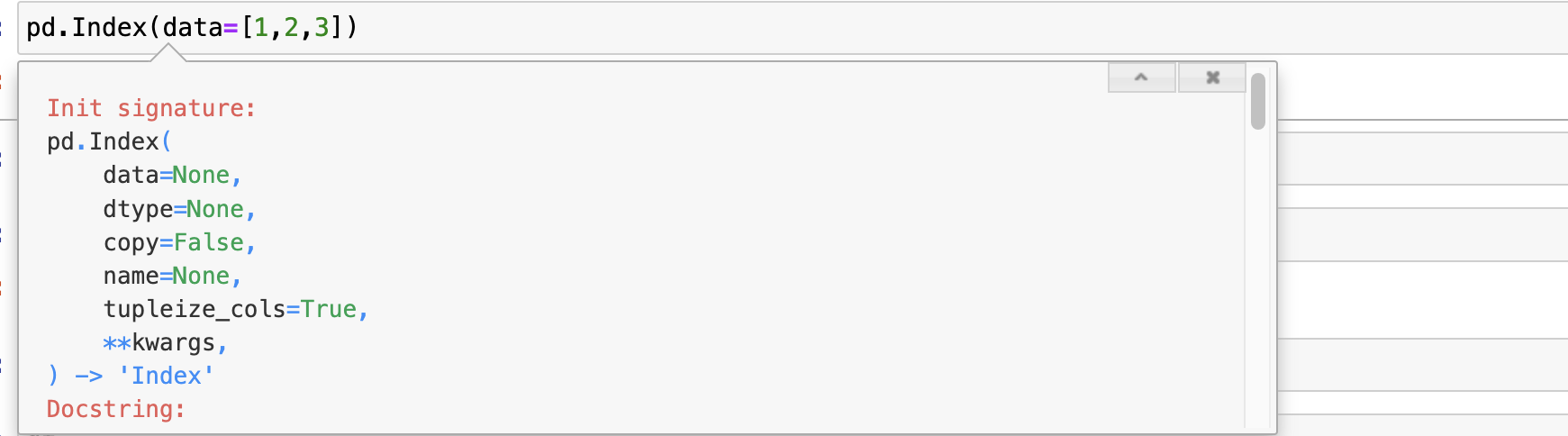
代码示例:

多层索引
多层索引构造
- 使用
pd.MultiIndex.from_arrays() - 使用
pd.MultiIndex.from_tuples() - 使用
pd.MultiIndex.from_product()
使用pd.MultiIndex.from_arrays()
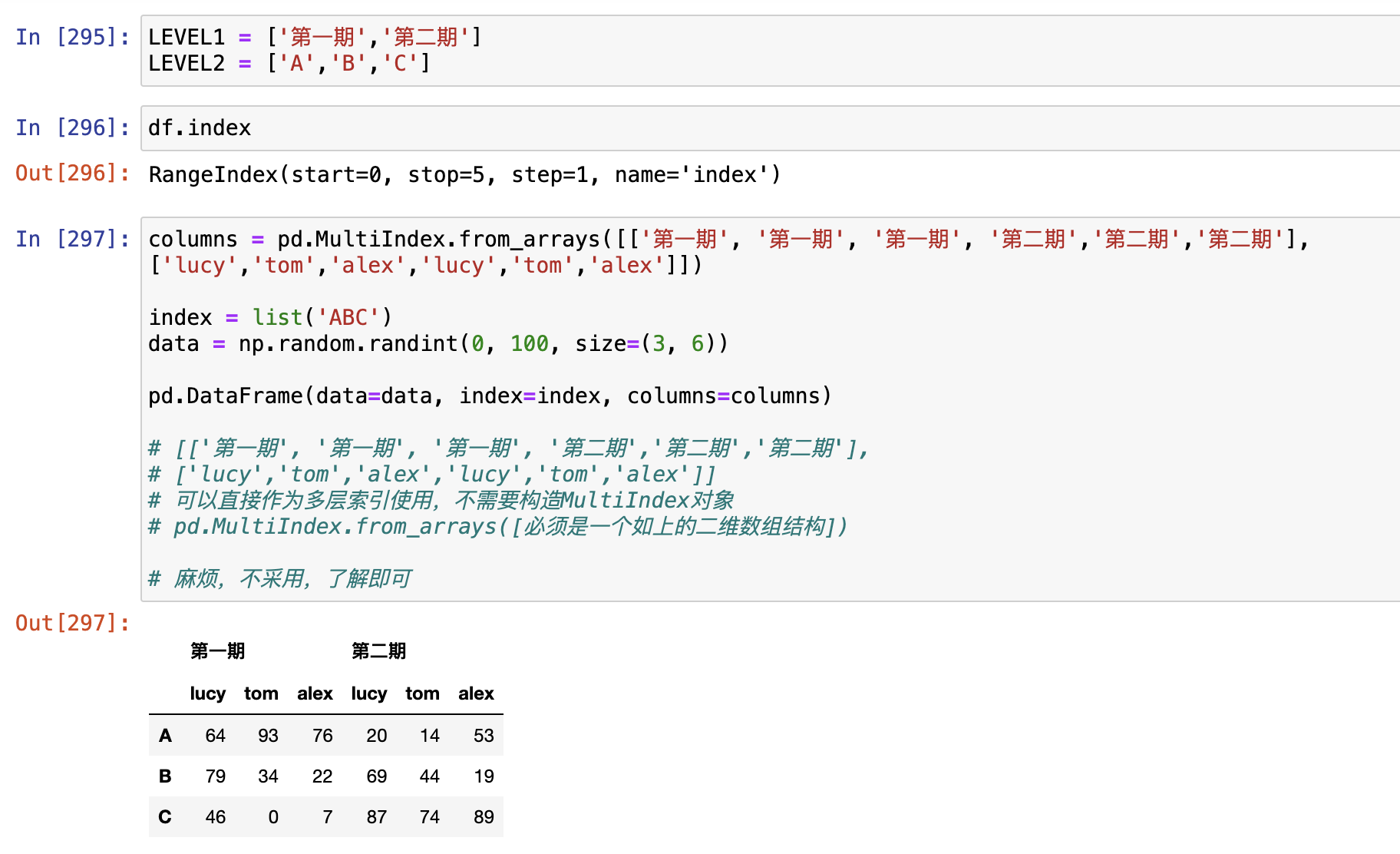
使用pd.MultiIndex.from_tuples()
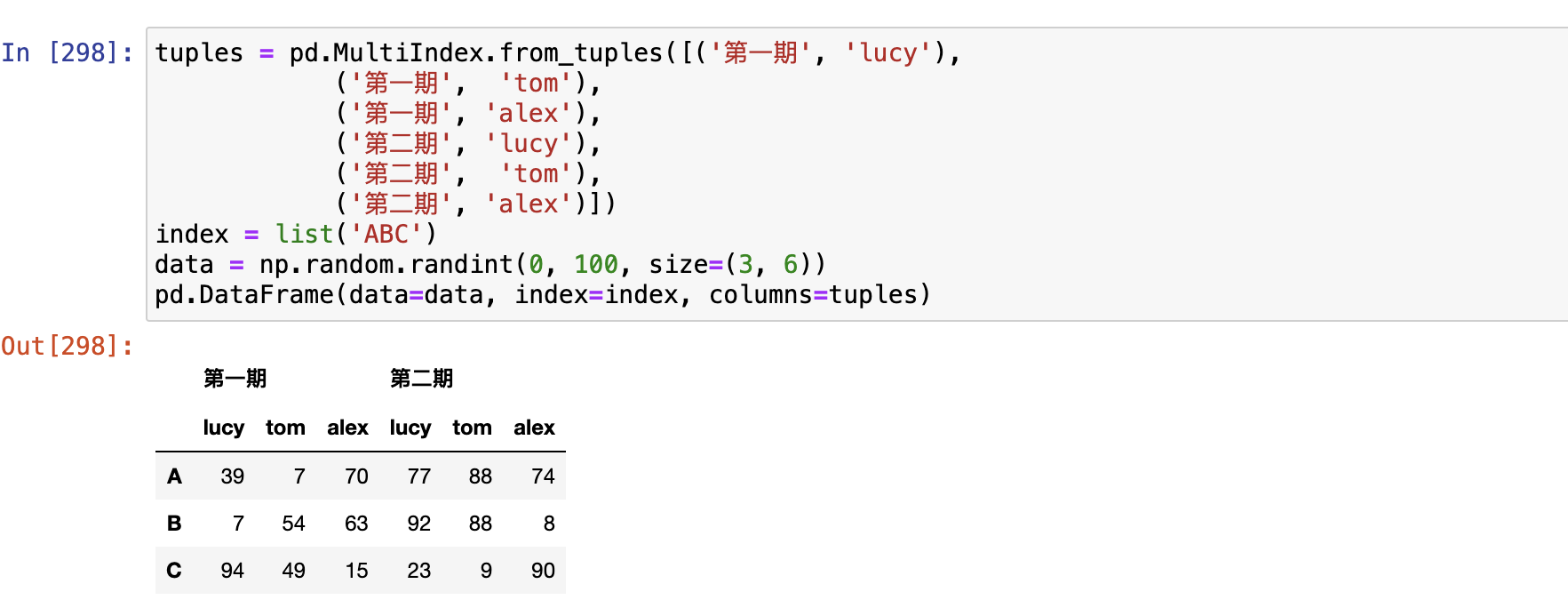
使用 pd.MultiIndex.from_product()
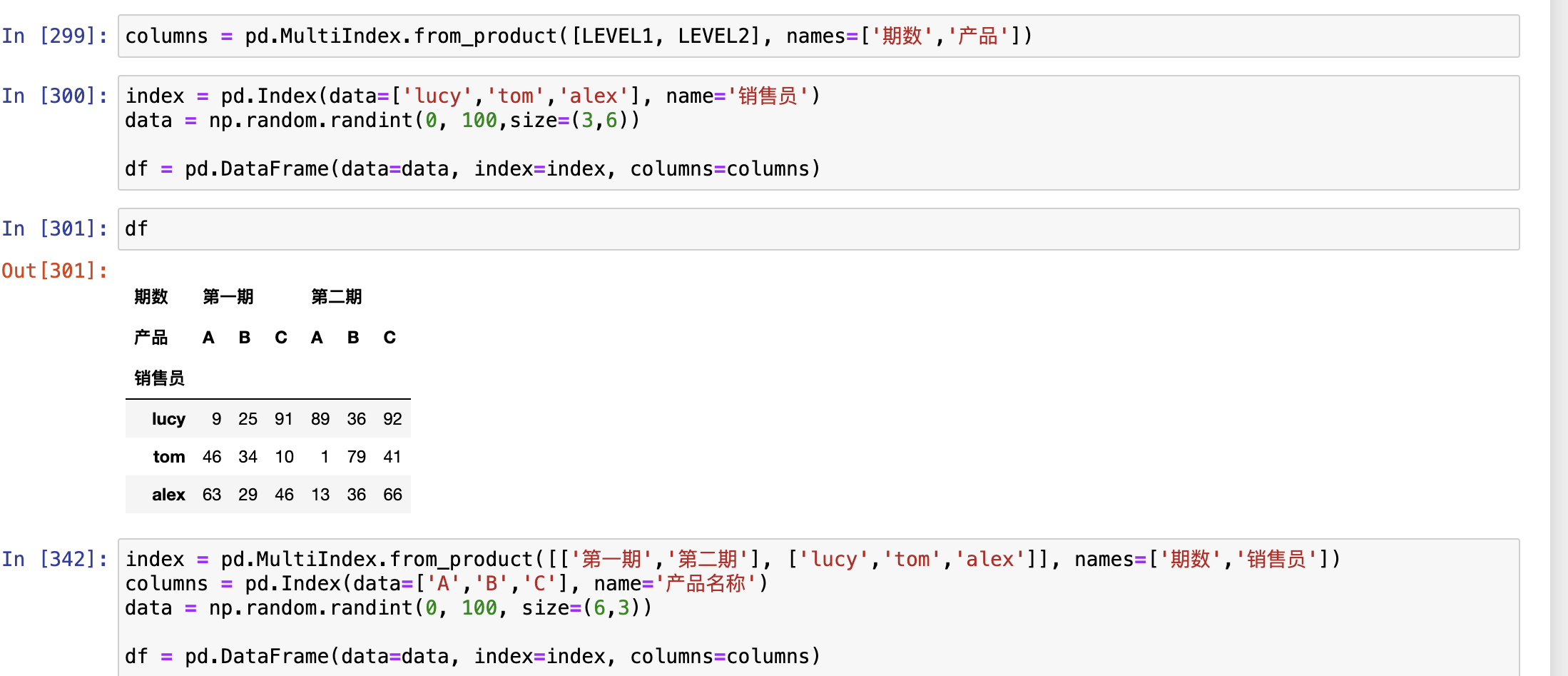

多层索引访问
显式索引访问
# 显示索引
df.loc[row_labels, col_labels]
s.loc[labels]
labels: 标签名称 标签名称列表 条件表达式 Bool列表 切片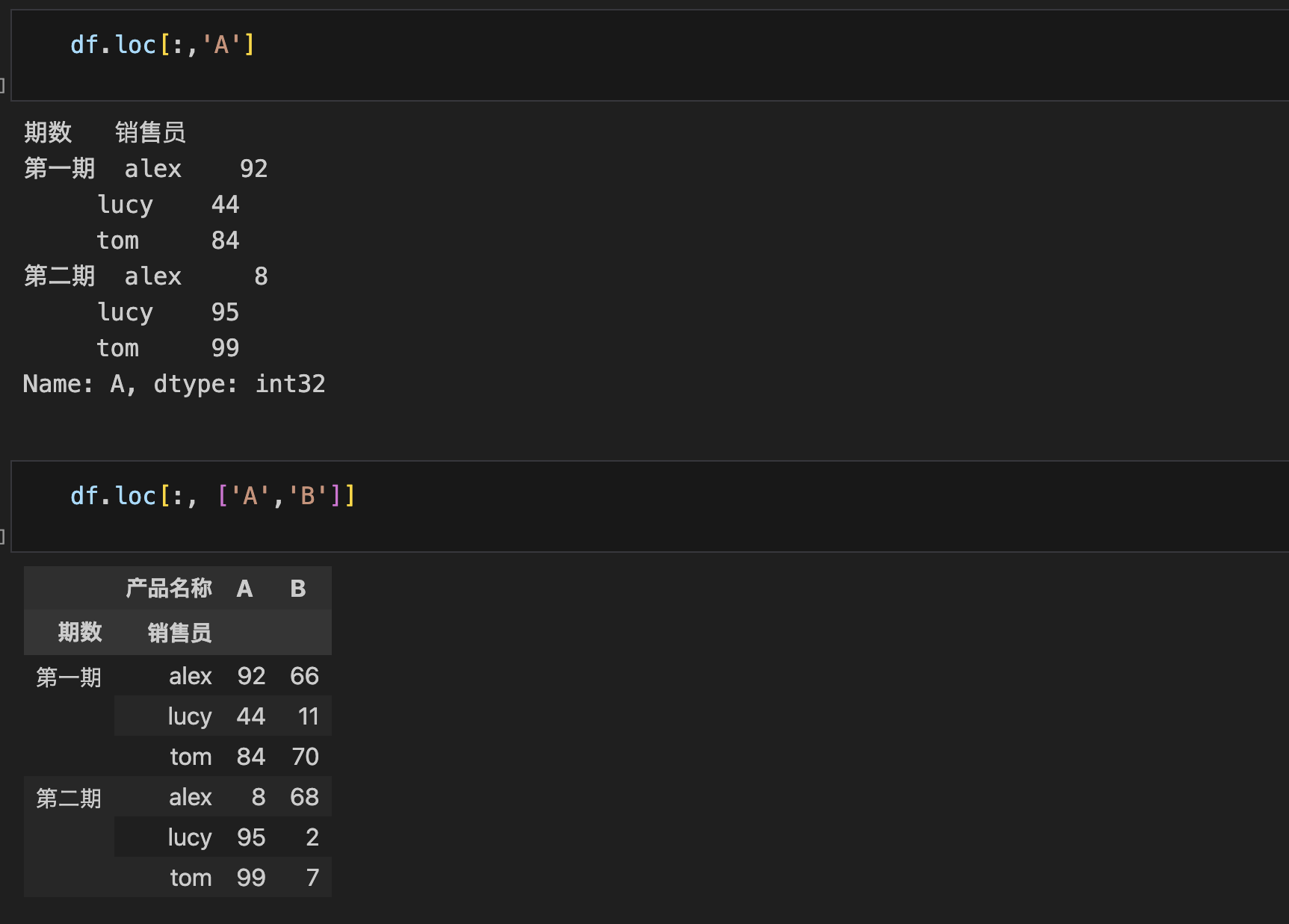
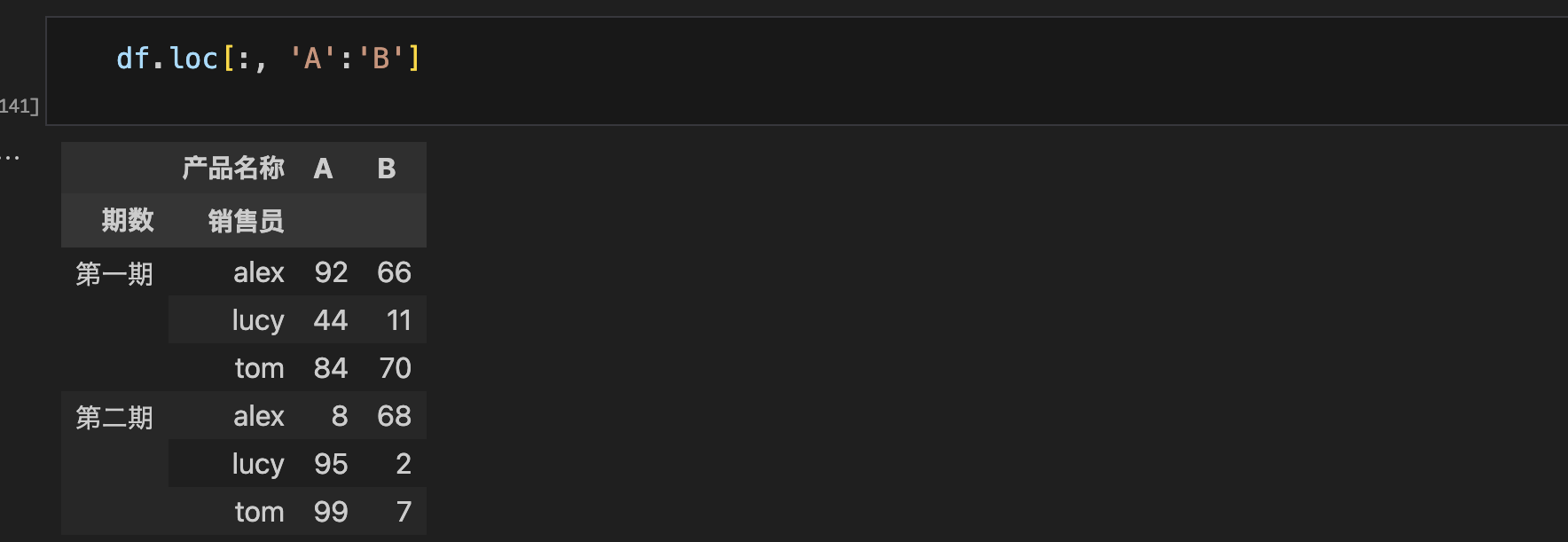
- 多层索引本质就是个元组,除此之外访问逻辑完全一致
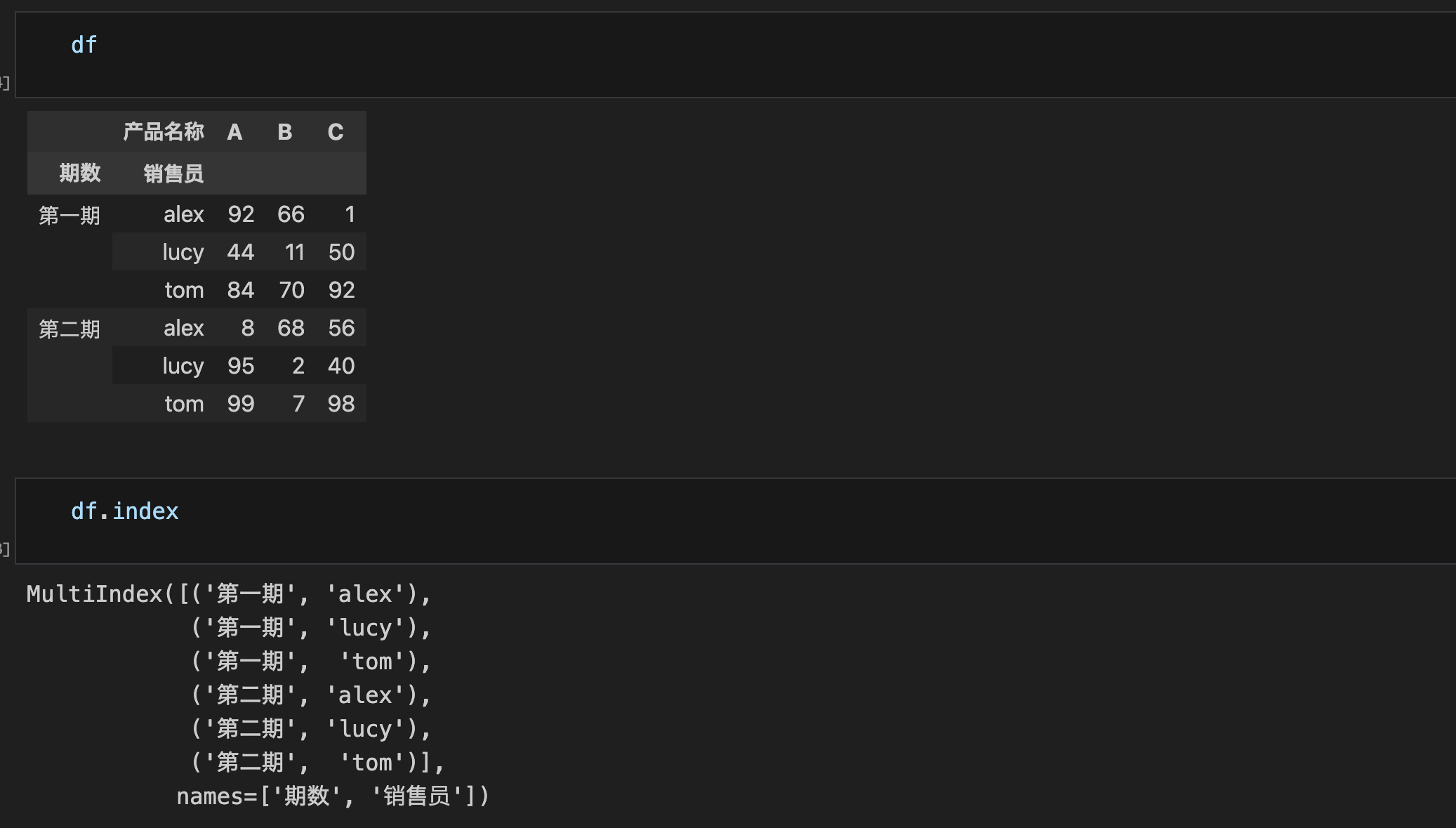
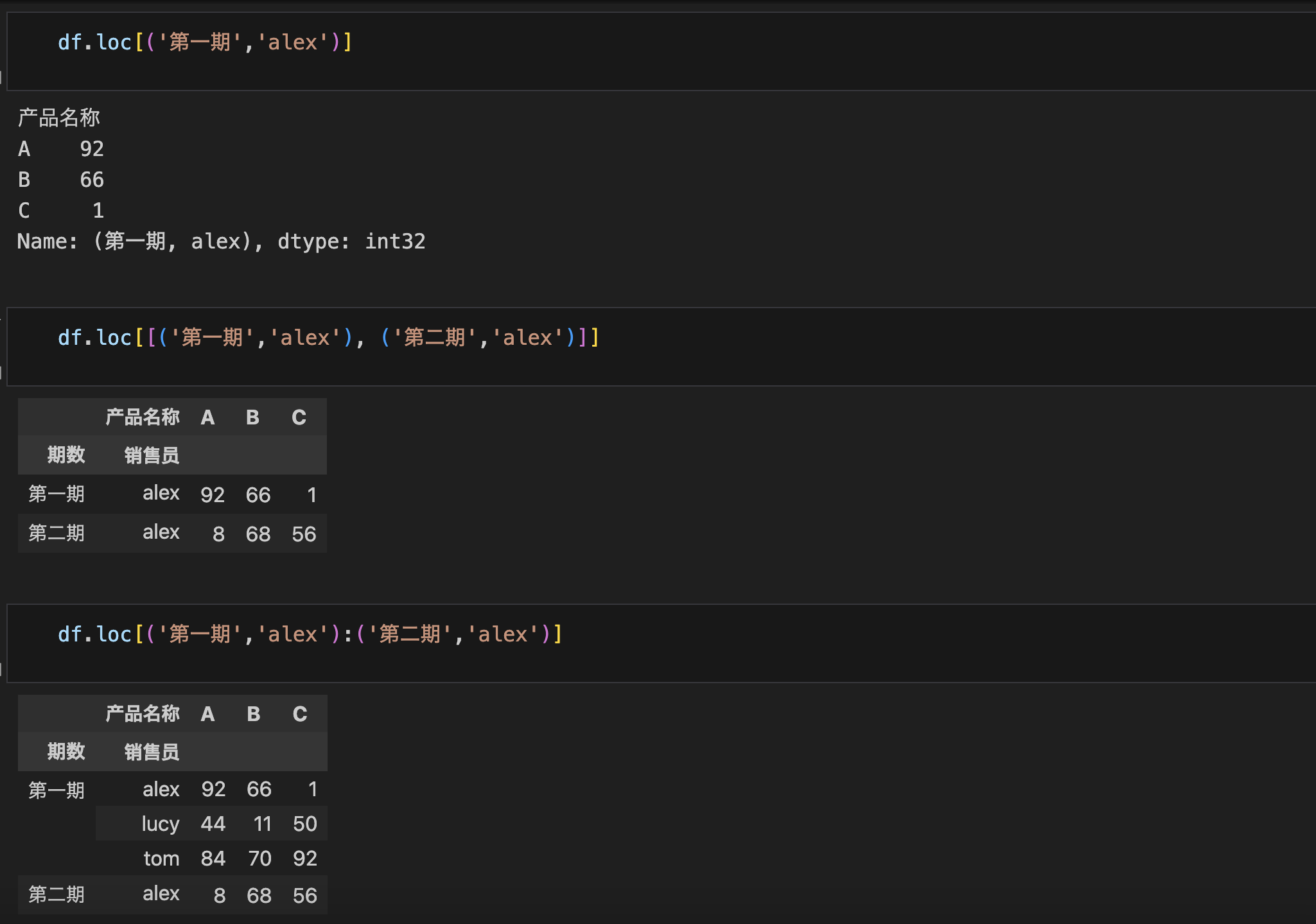
- 可以从外层索引开始,一级一级向内访问,但不能越级访问。
- 会变成间接访问的模式
- 读的话没办法
- 但不要往里写数据,安全问题!!!
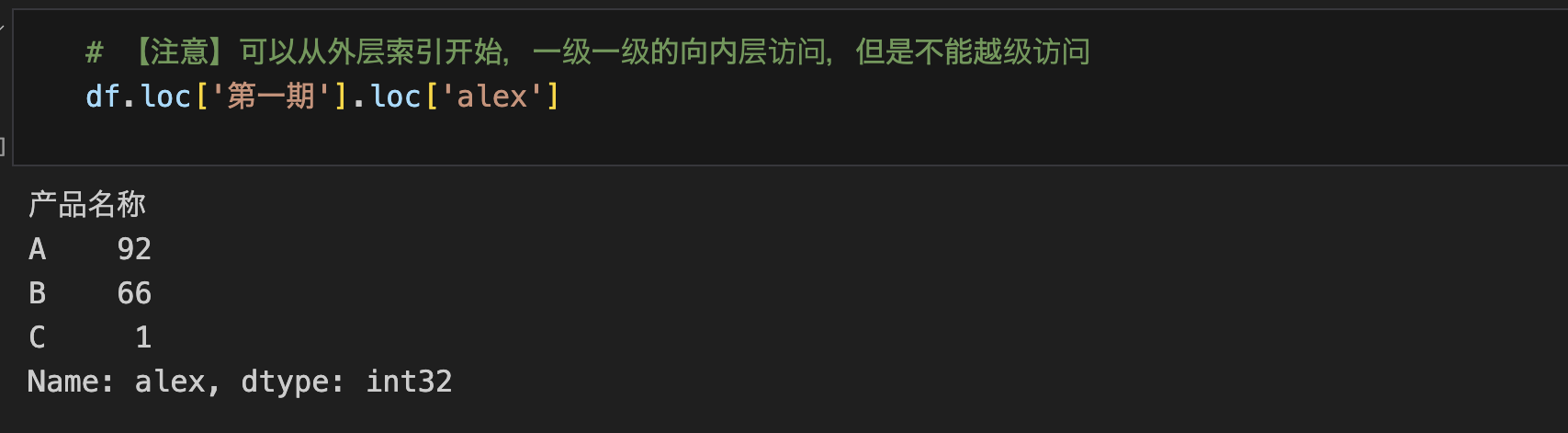
- 使用切片索引访问时,先排序,不然报错UnsortedIndexError。
- 排序:df.sort_index()
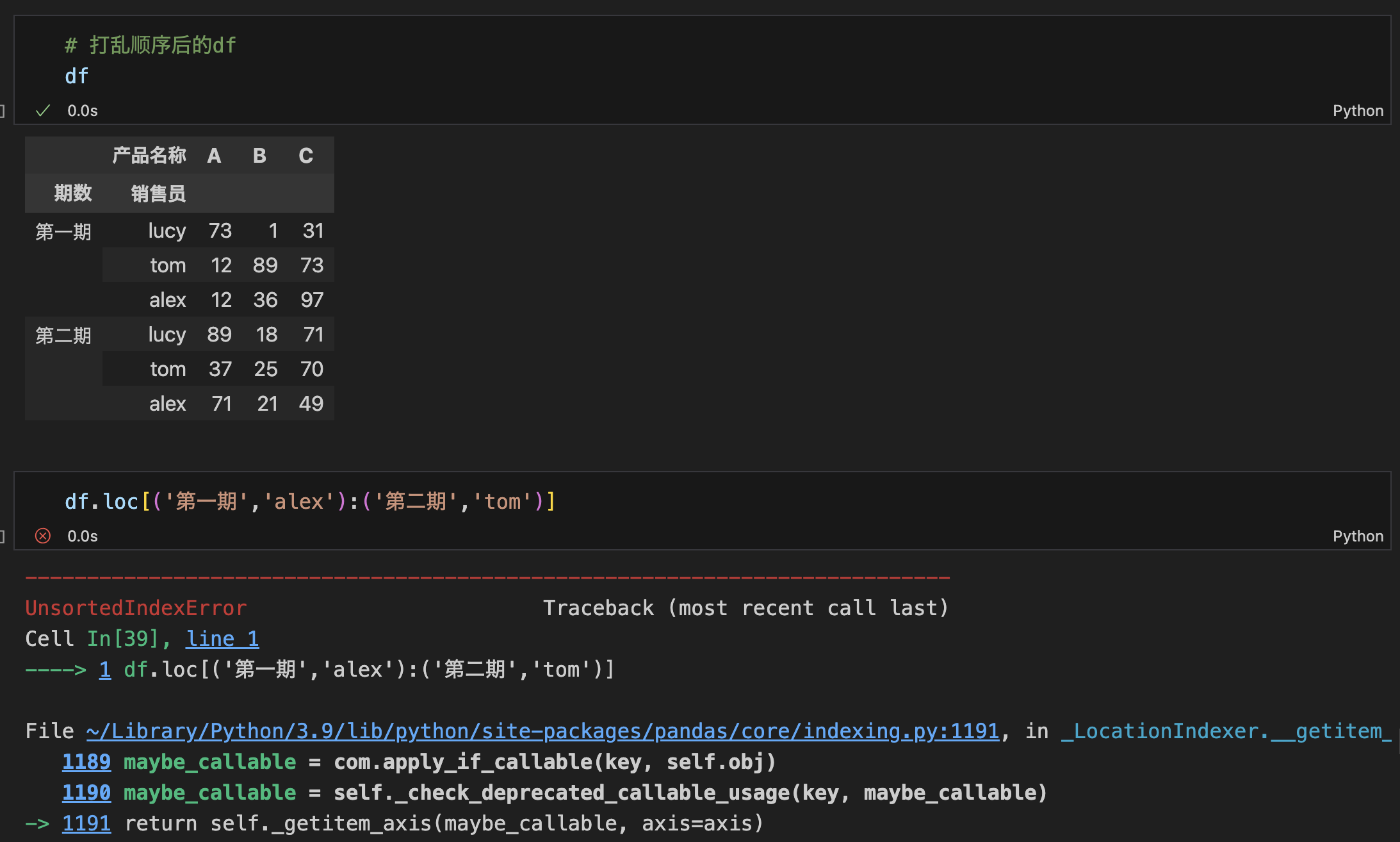
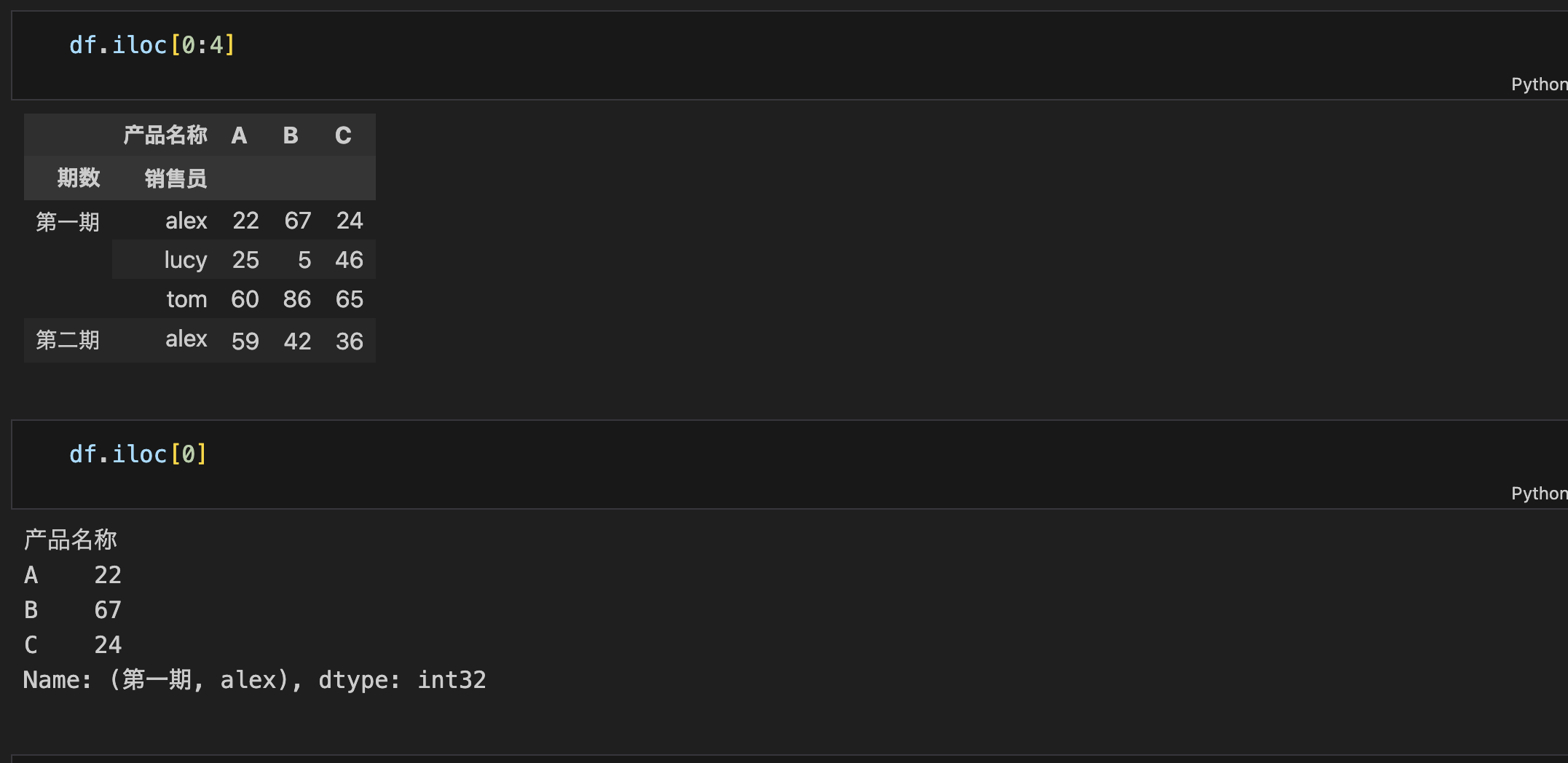
隐式索引访问
正常的行列逻辑,不赘述。
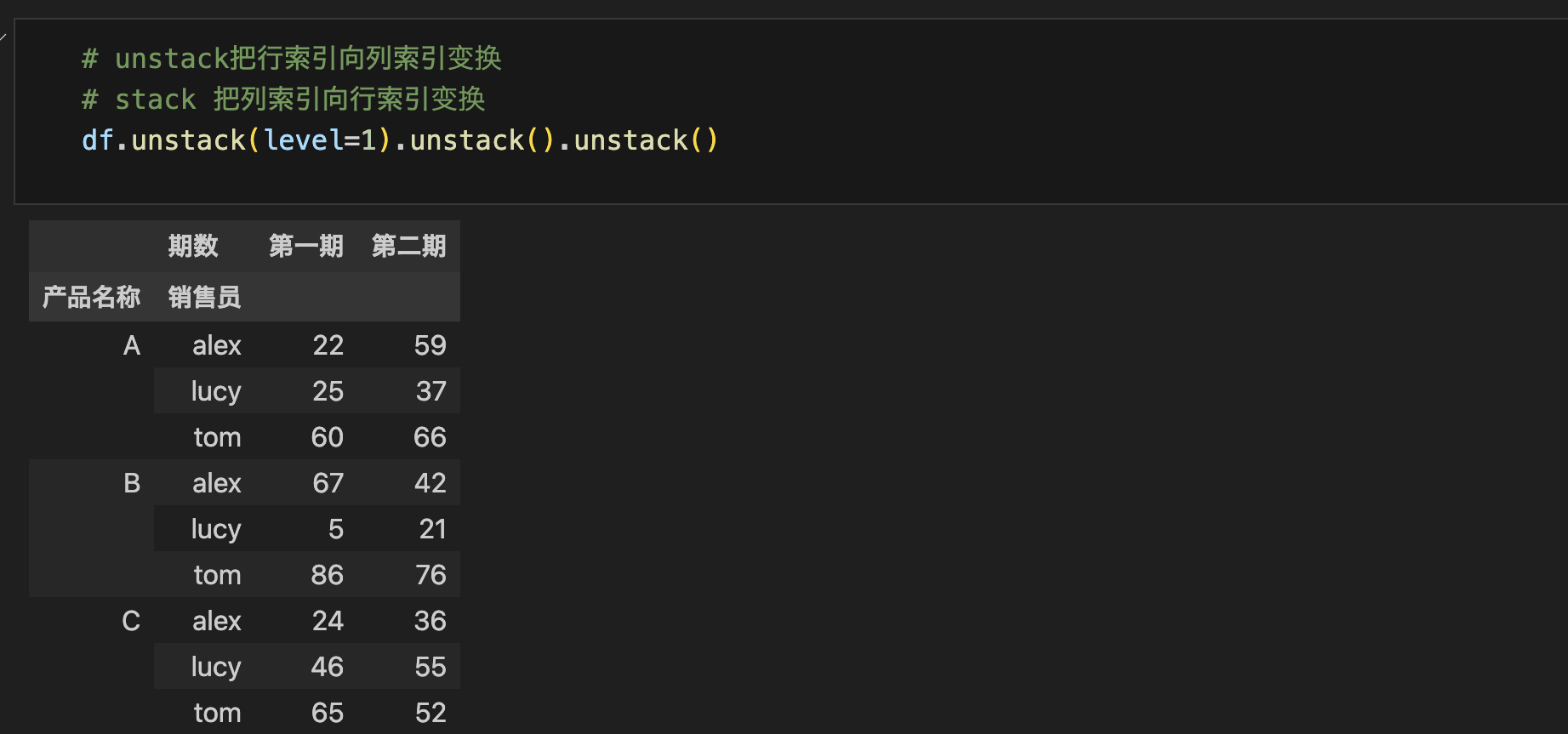
Stack和Unstack操作
- Unstack: 把index变为columns
- Stack:把columns变为index
- level:最里层为-1
练习
1. 创建一个DataFrame,表示出lucy,tom,jack期中期末各科(python,java,c)成绩
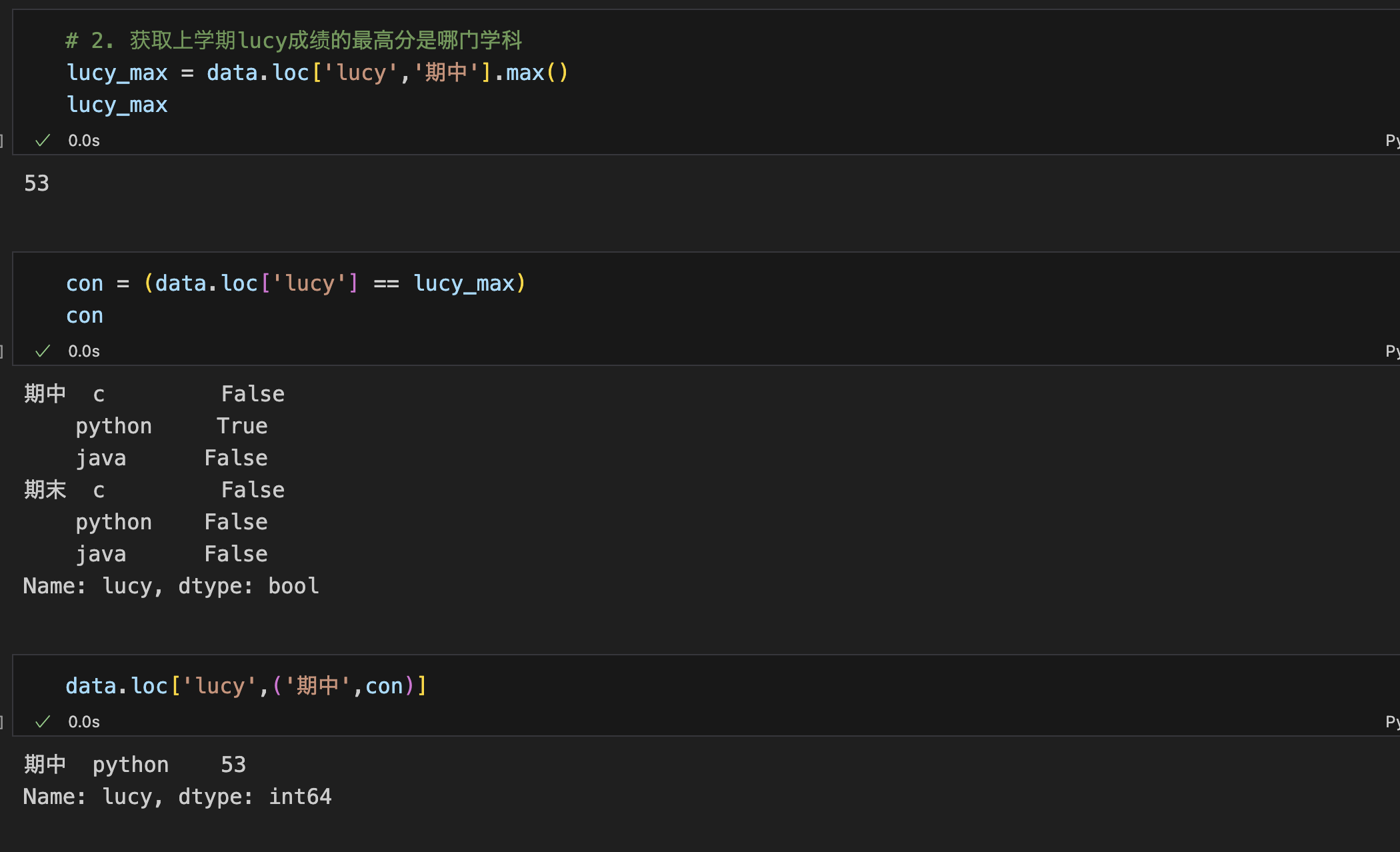
2. 获取上学期lucy成绩的最高分是哪门学科
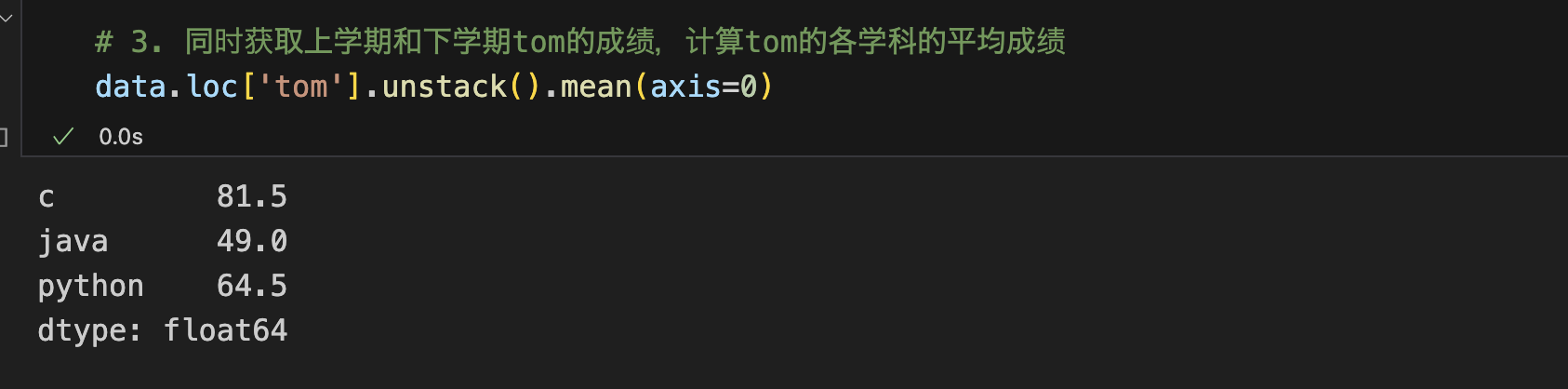
3. 同时获取上学期和下学期tom的成绩,计算tom的各学科的平均成绩
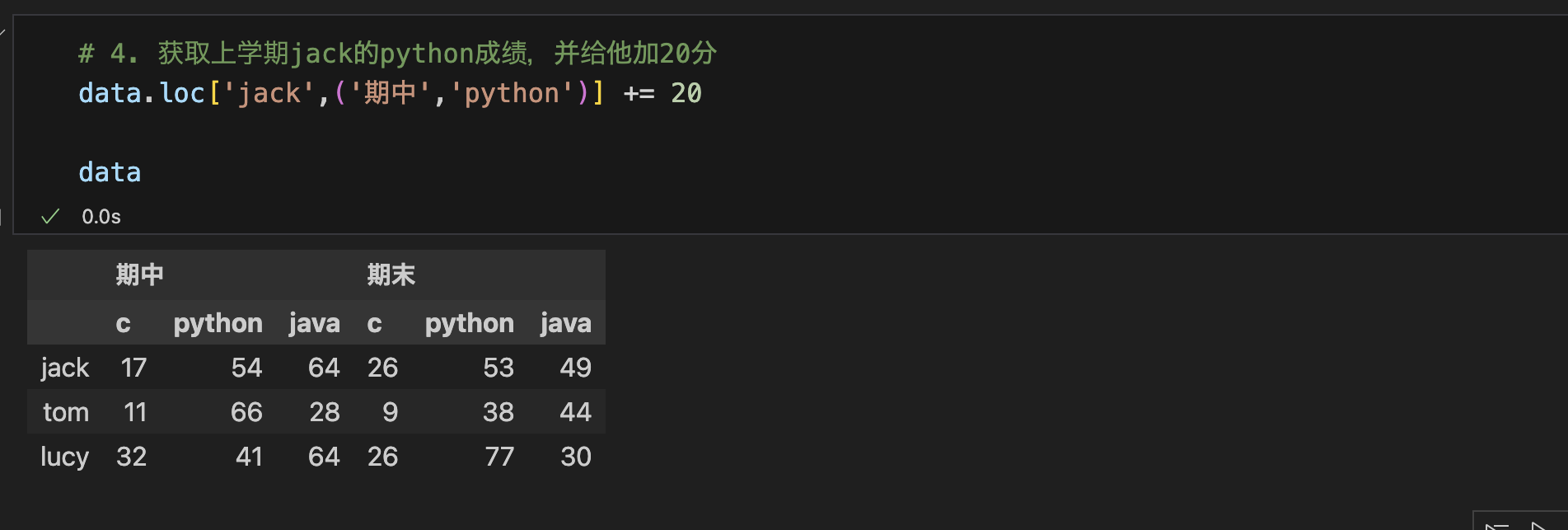
4. 获取上学期jack的python成绩,并给他加20分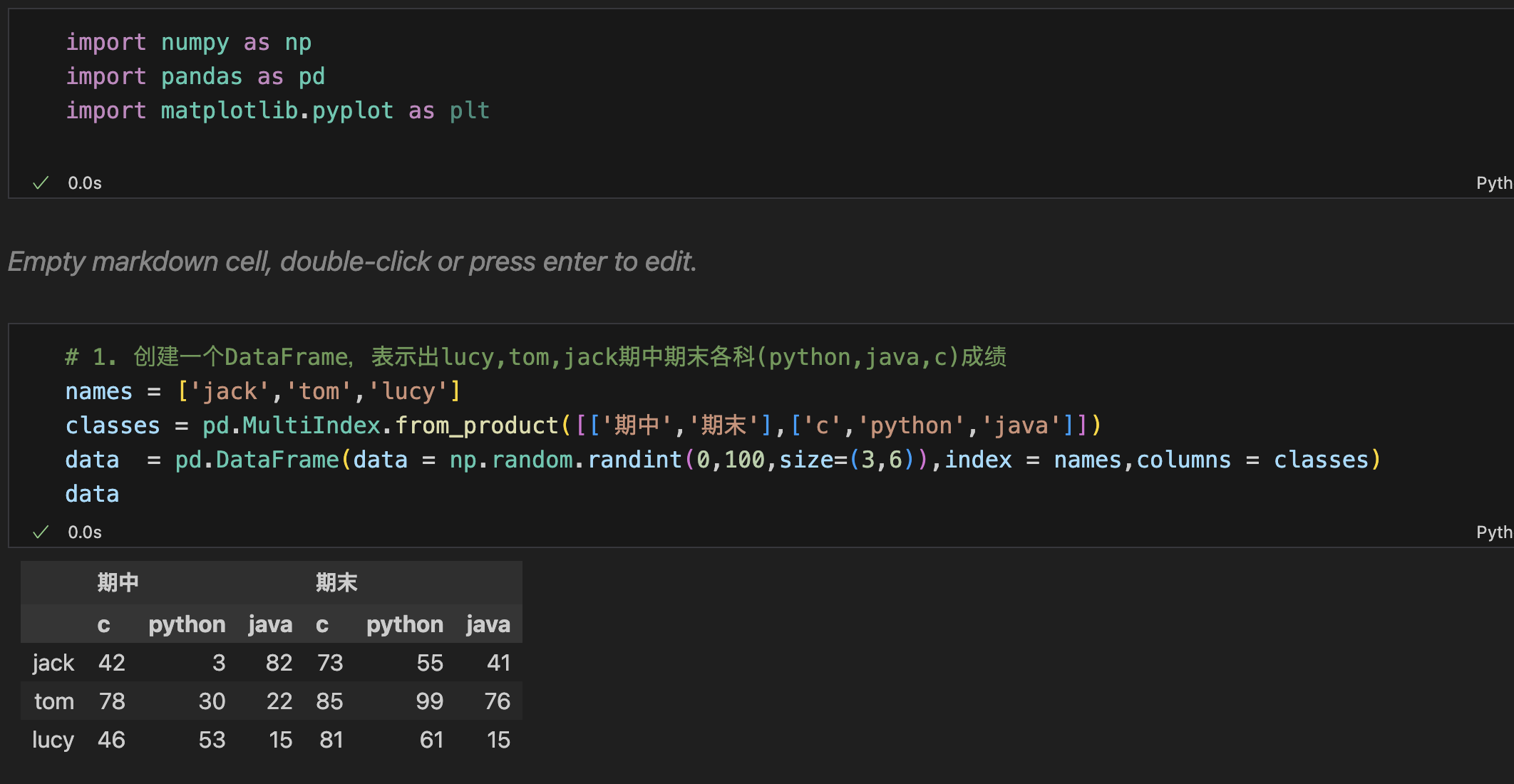
数据IO操作
- pandas的 IO操作主要是读取有特定格式的文件
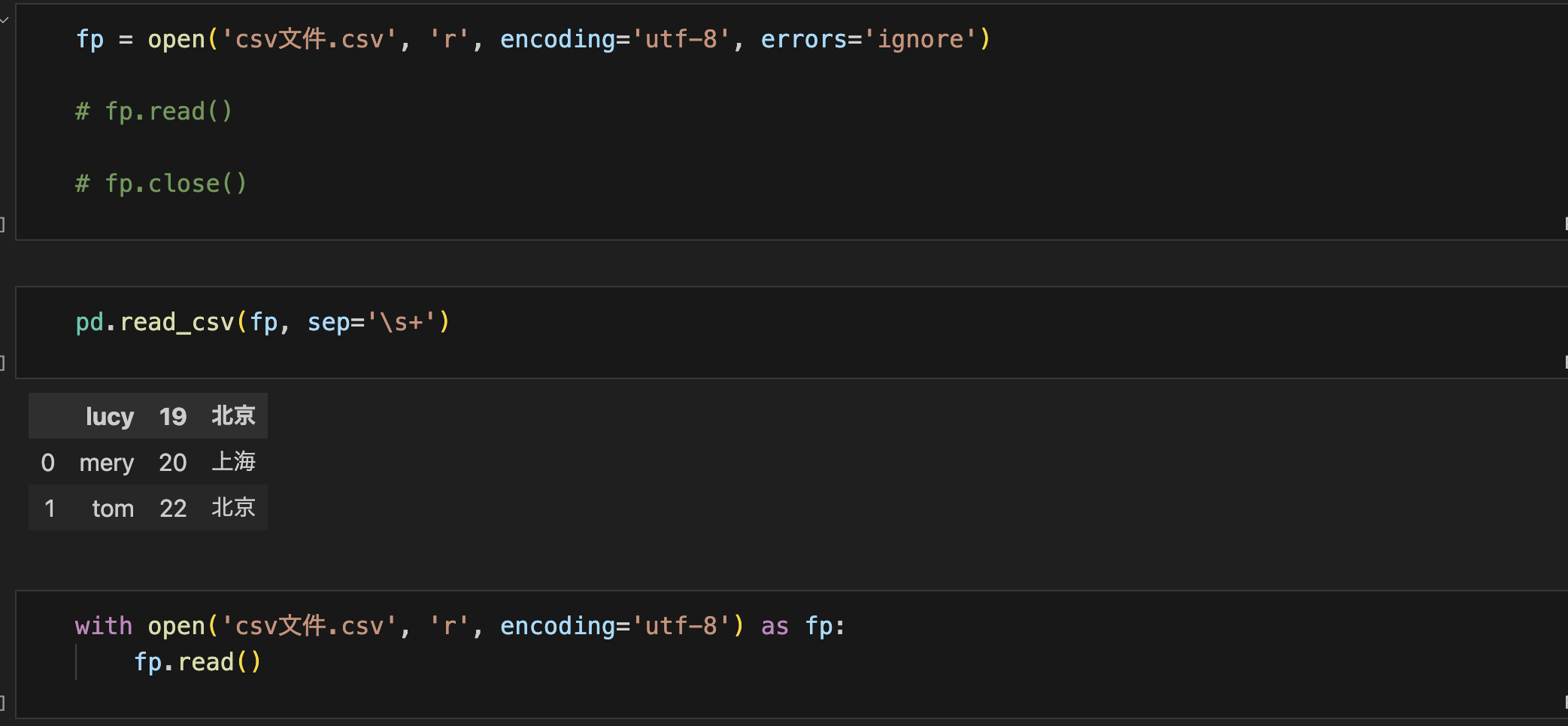
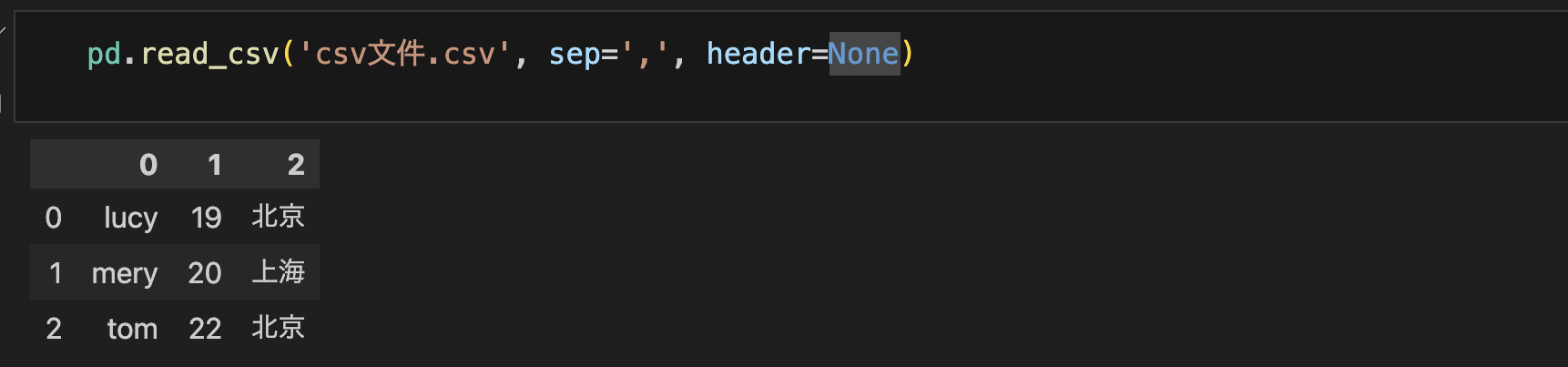
pd.read_csv()
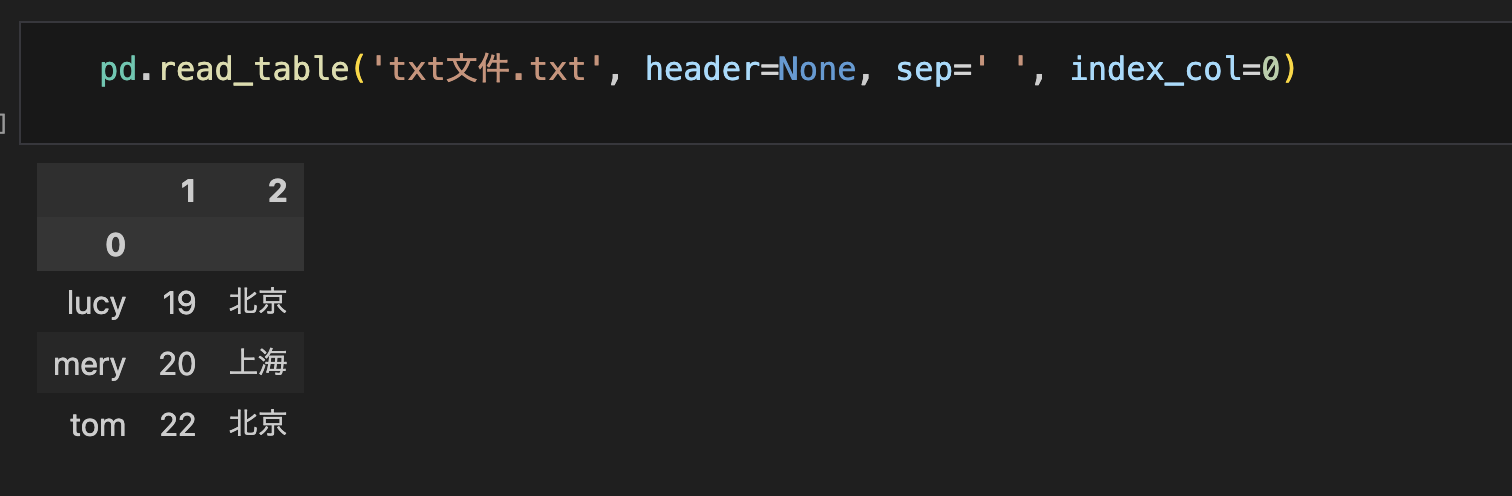
pd.read_table()
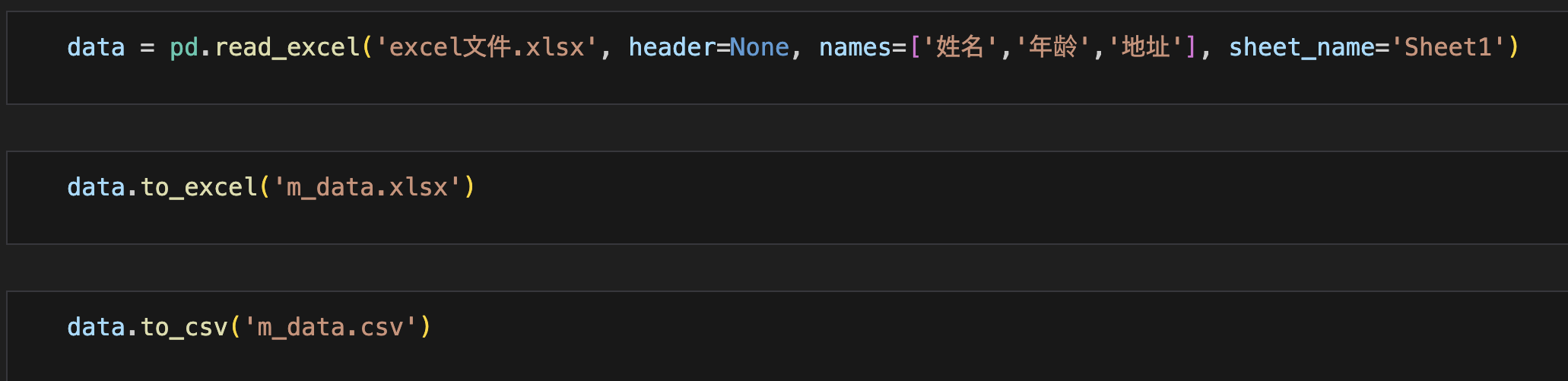
excel读取
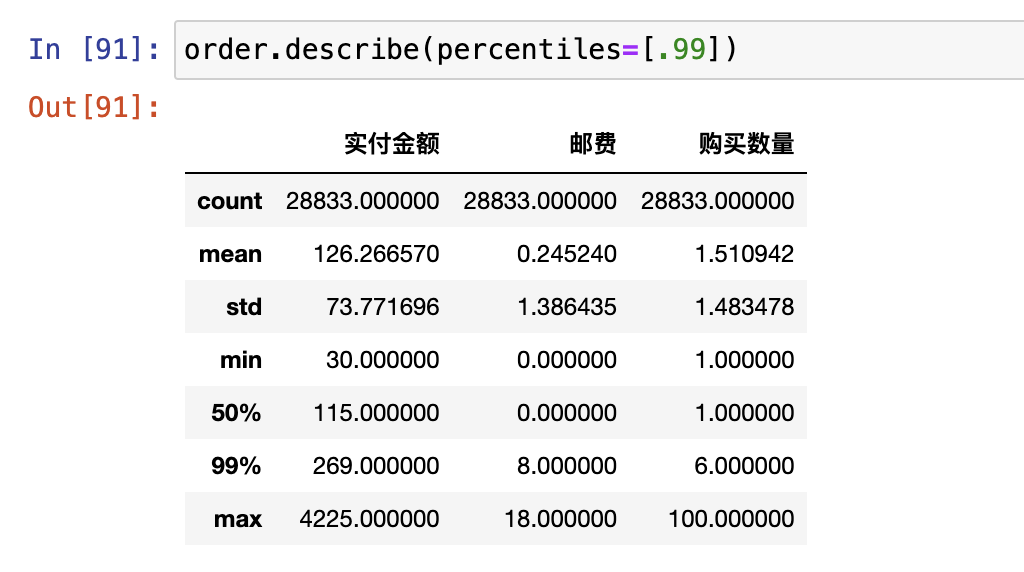
数据探索
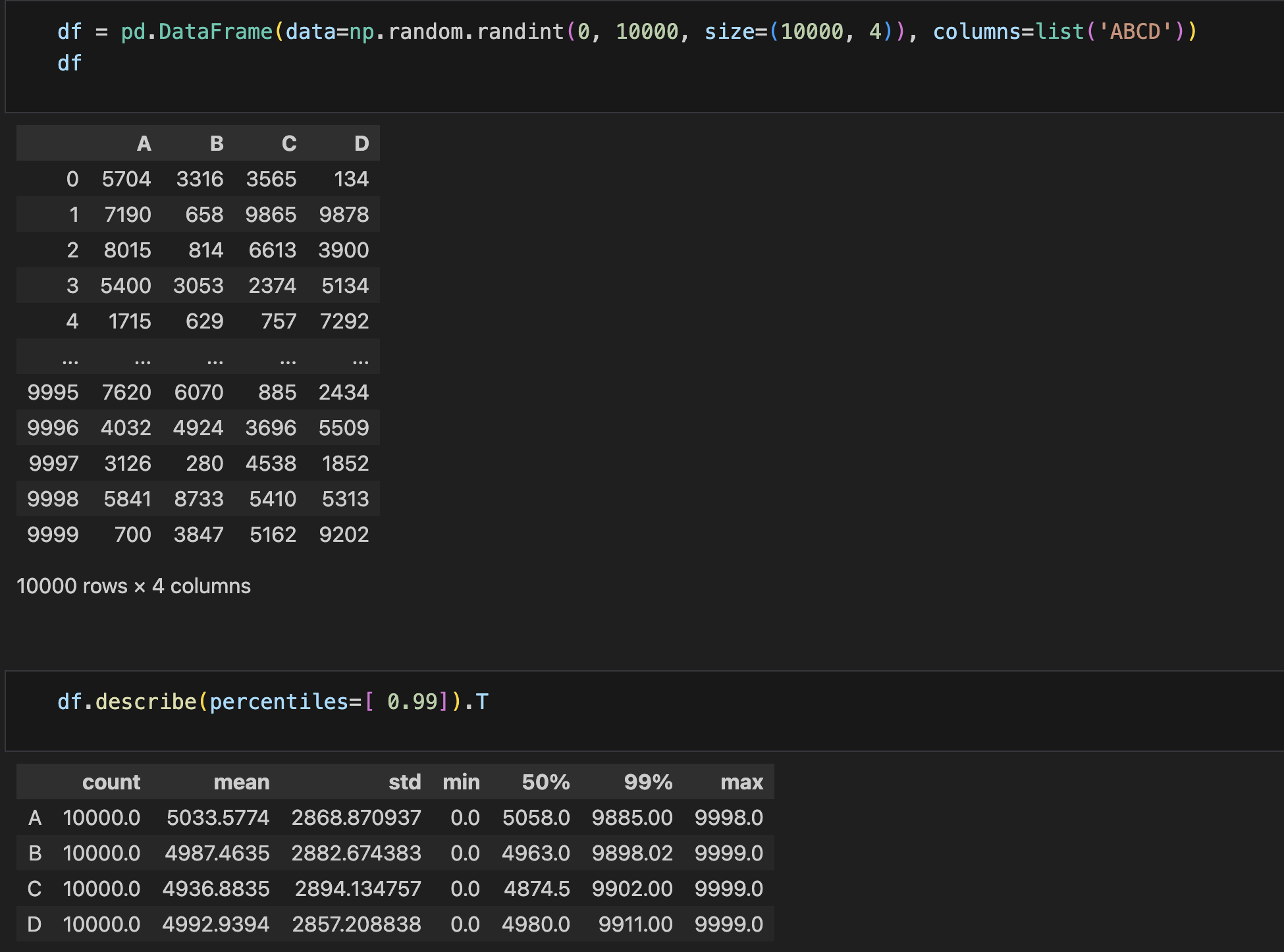
- Describe()
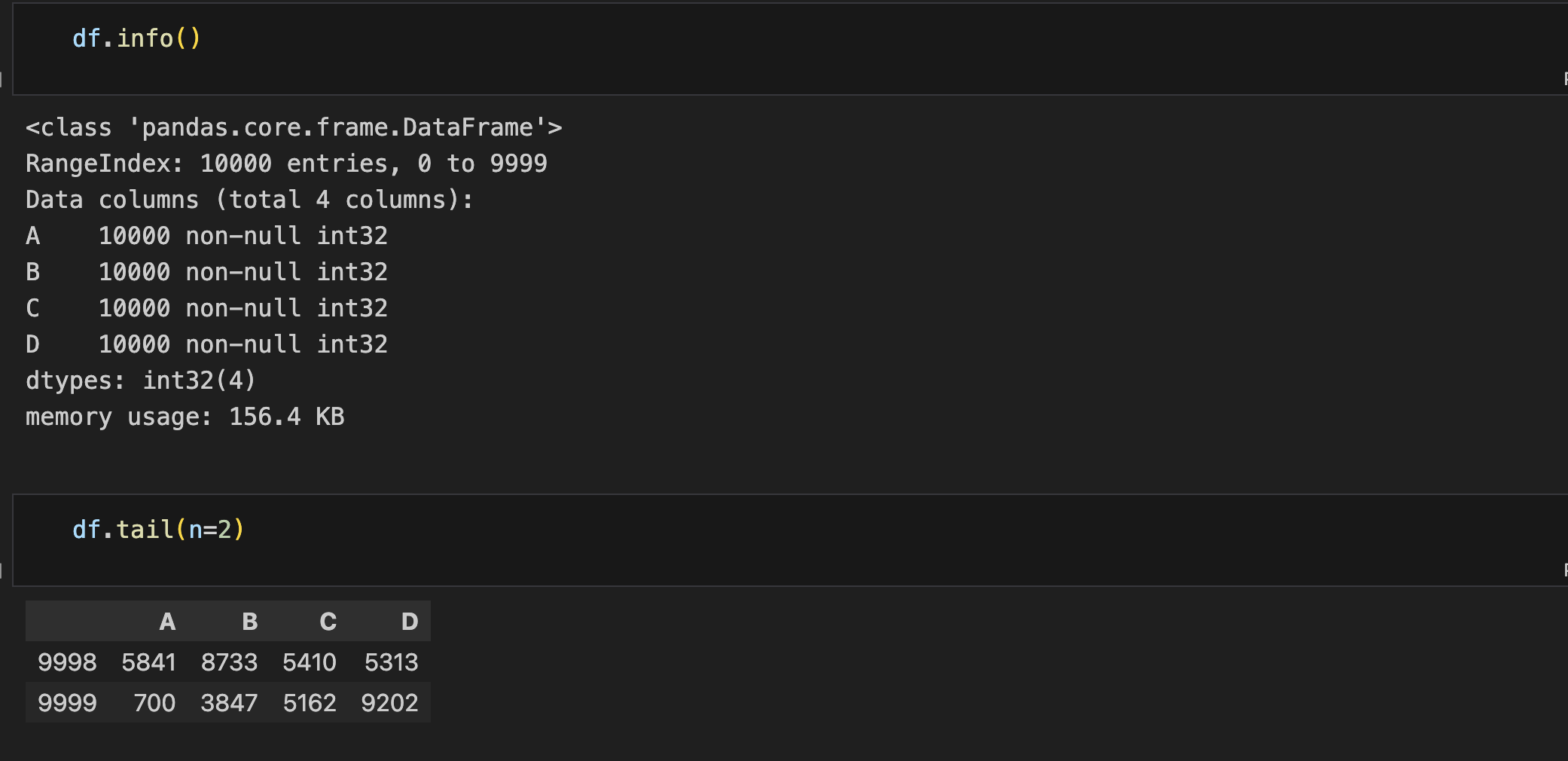
- Info()
- Head()
- Tail()
- Sample(),随机抽样
空值处理
基本就俩思路,看情况选:
- 删掉空值
- 把非空数据过滤出来
None
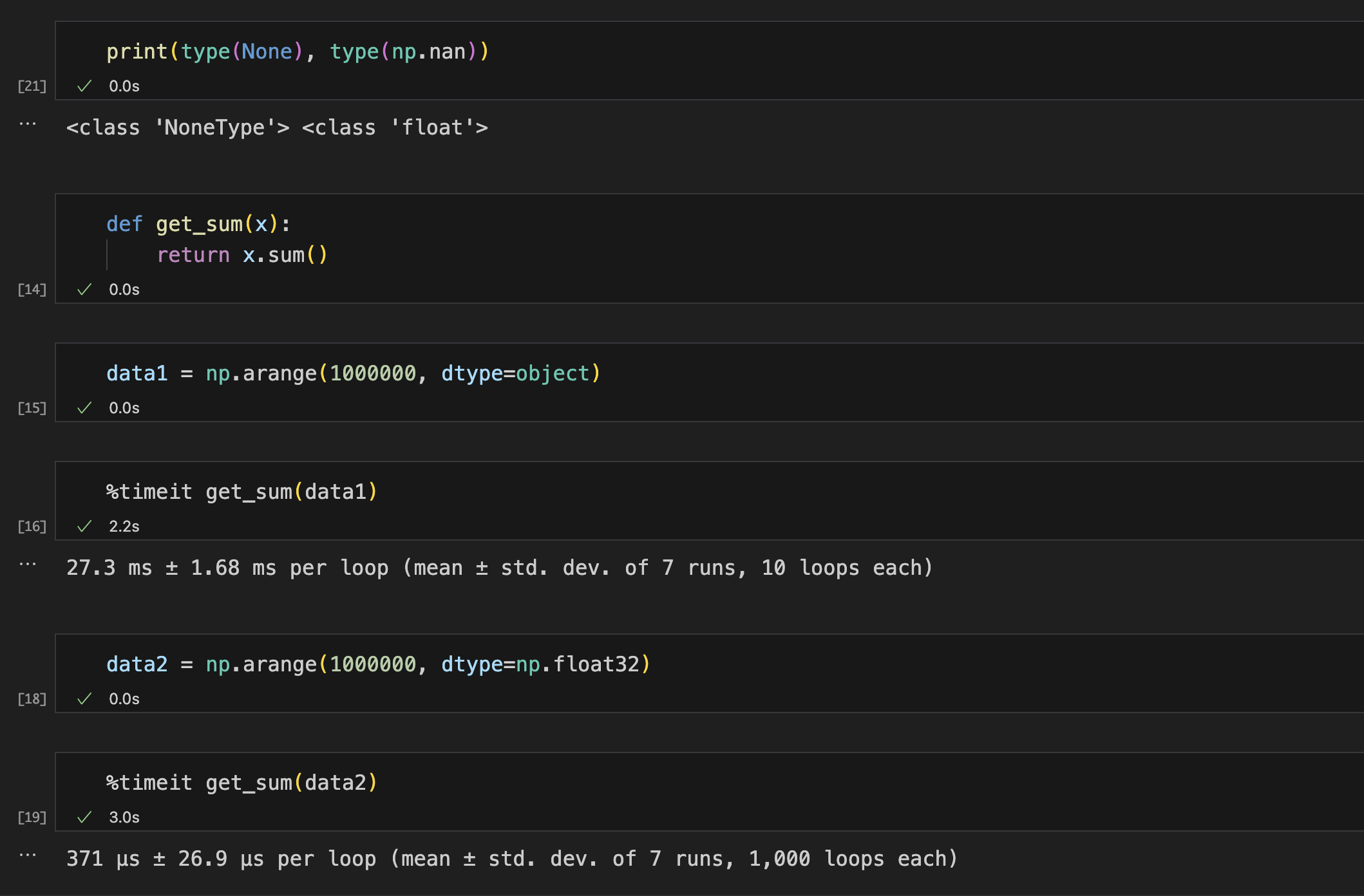
- None是Python自带的,其类型为python object。
- None不能参与到任何计算中。
- object类型的运算要比int类型的运算慢得多
np.nan
np.nan是numpy提供的 一个常量,用于表达空值,是一个float,能参与到计算中。
NaN(not a number) 是一个符号,不是一个量。
pandas对象中,所有的np.nan都是以NaN展示
在numpy中,可以使用np.nanxxx()函数来计算nan,此时视nan为0。
pandas自动把None处理成np.nan
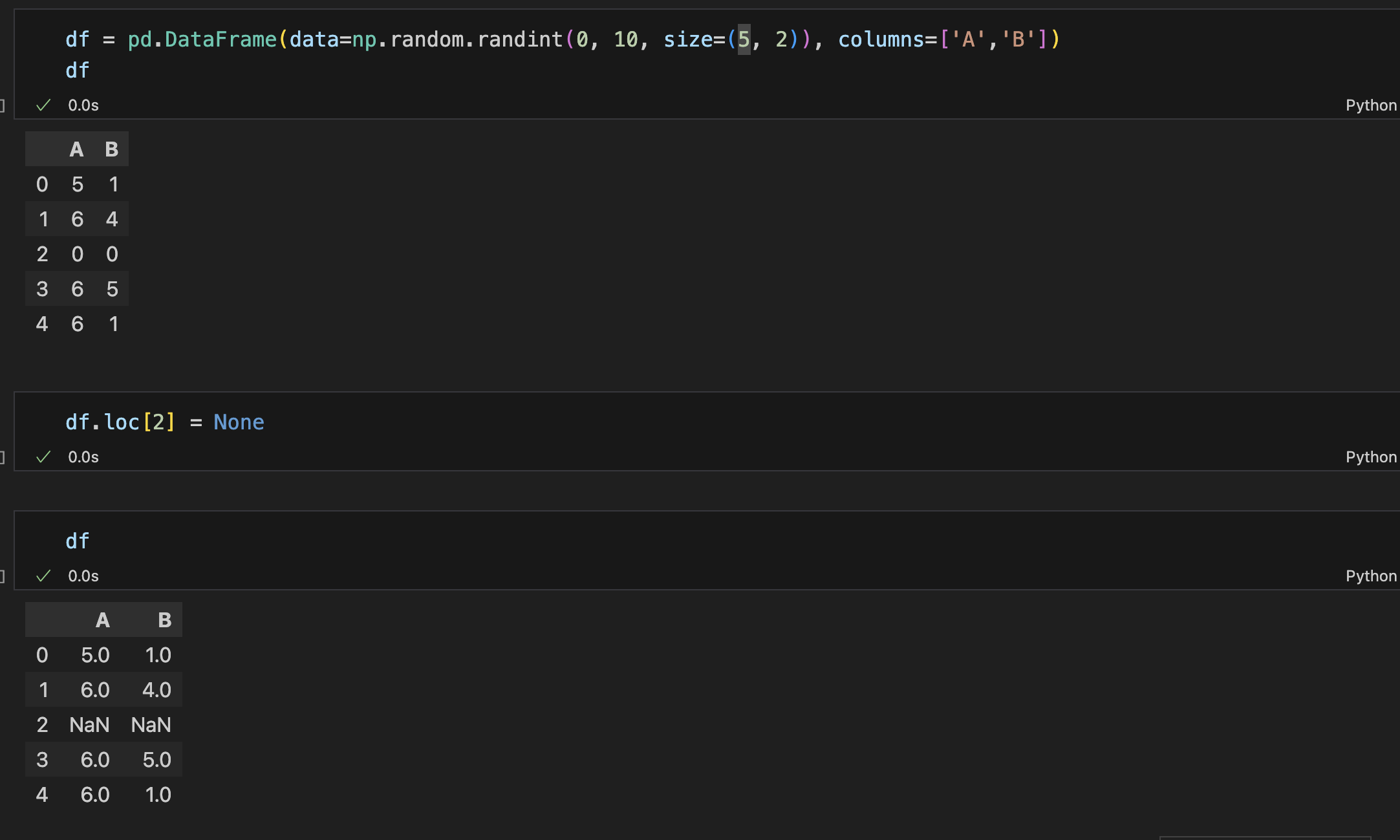
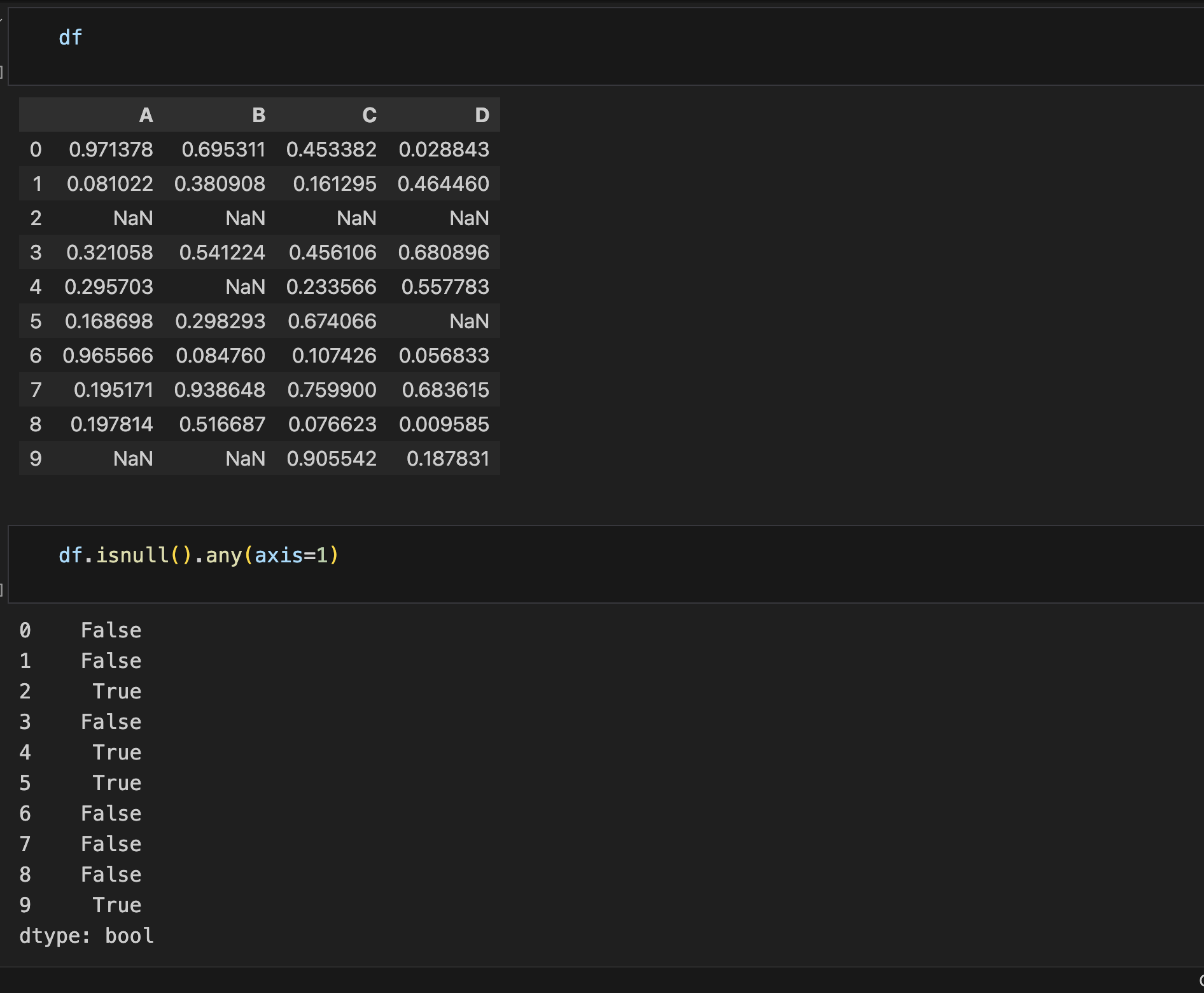
空值查找
- Isnull()
- notnull()
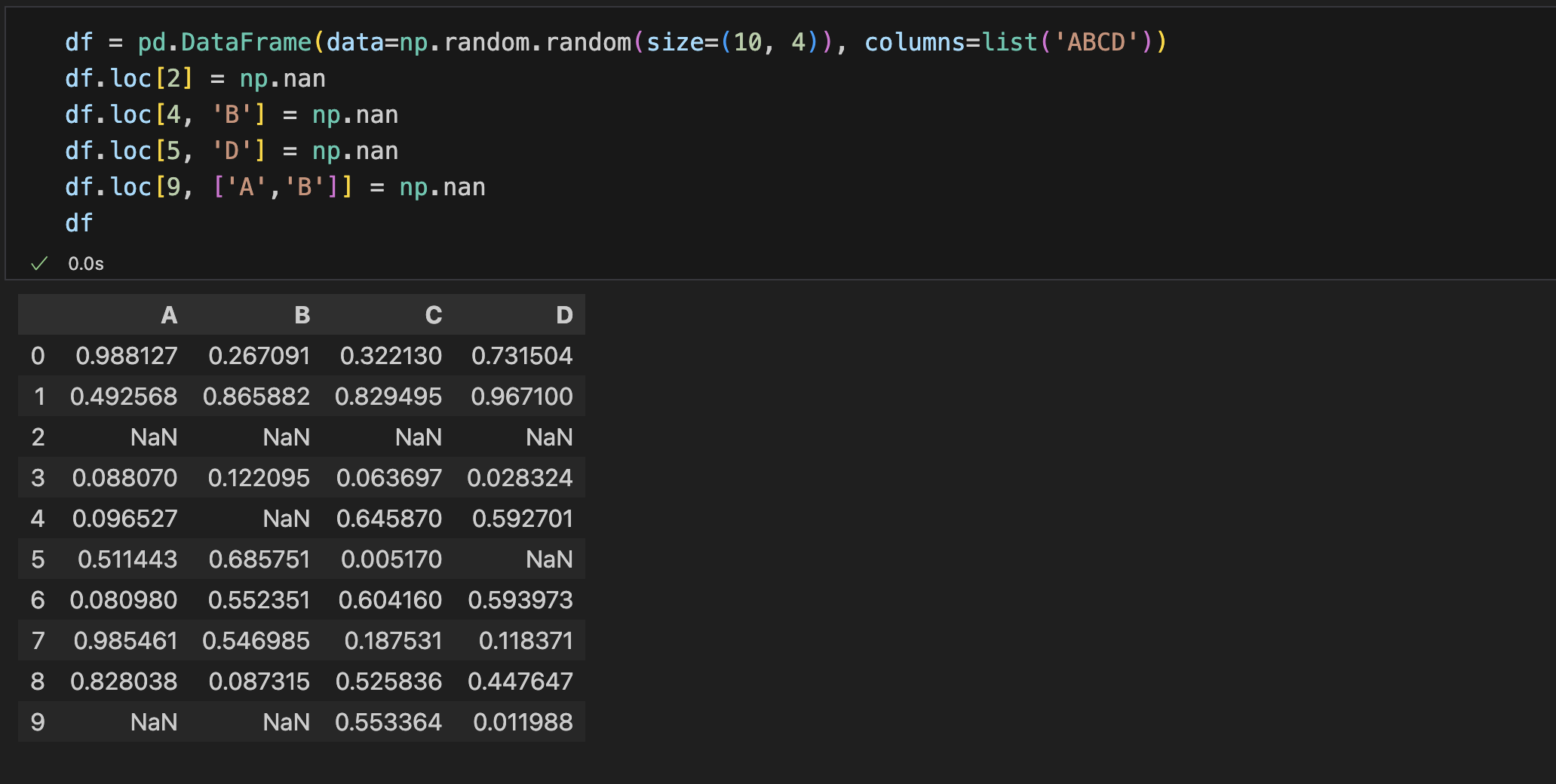
空值填充
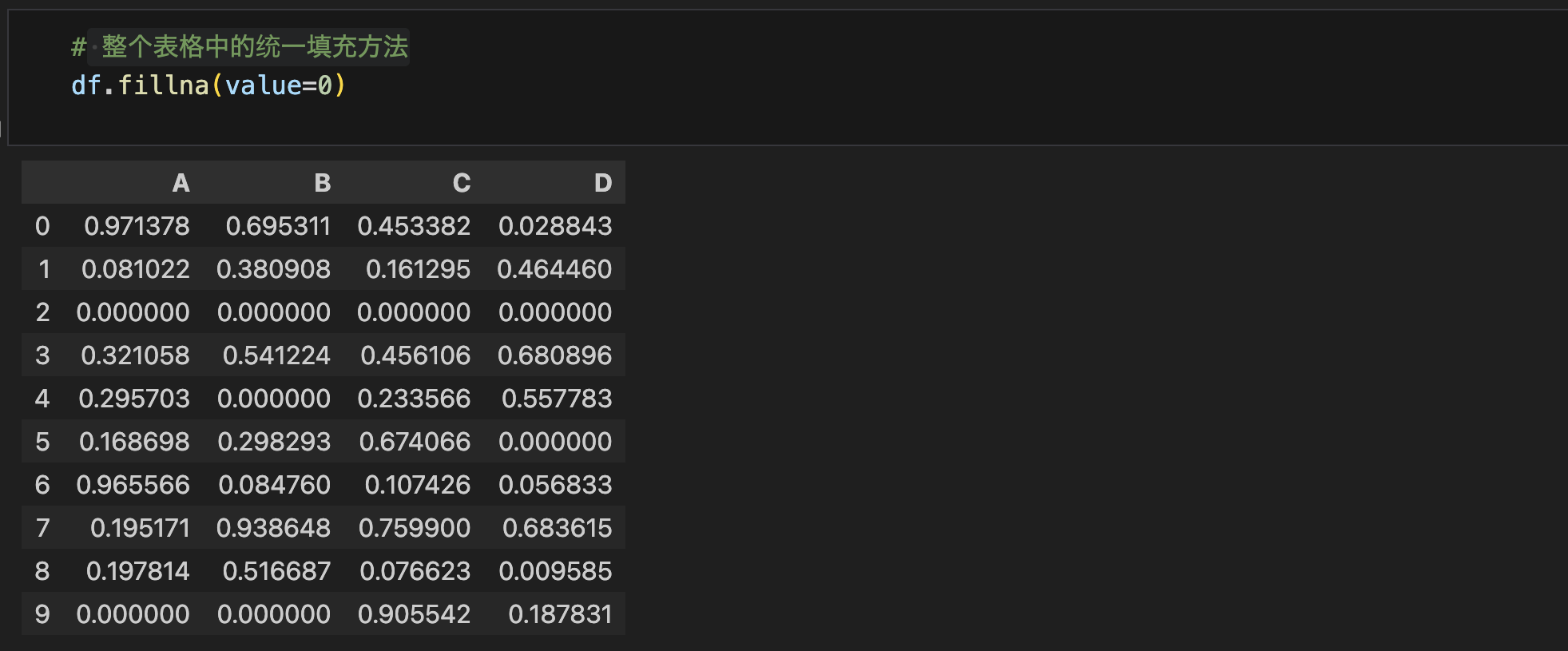
- fillna()
整个表格中的统一填充方法
使用均值来填充空值
可以使用序列(Series)来批量填充, 默认列索引对齐
使用临近值填充,不需要再指定value
空值过滤
基本就俩思路
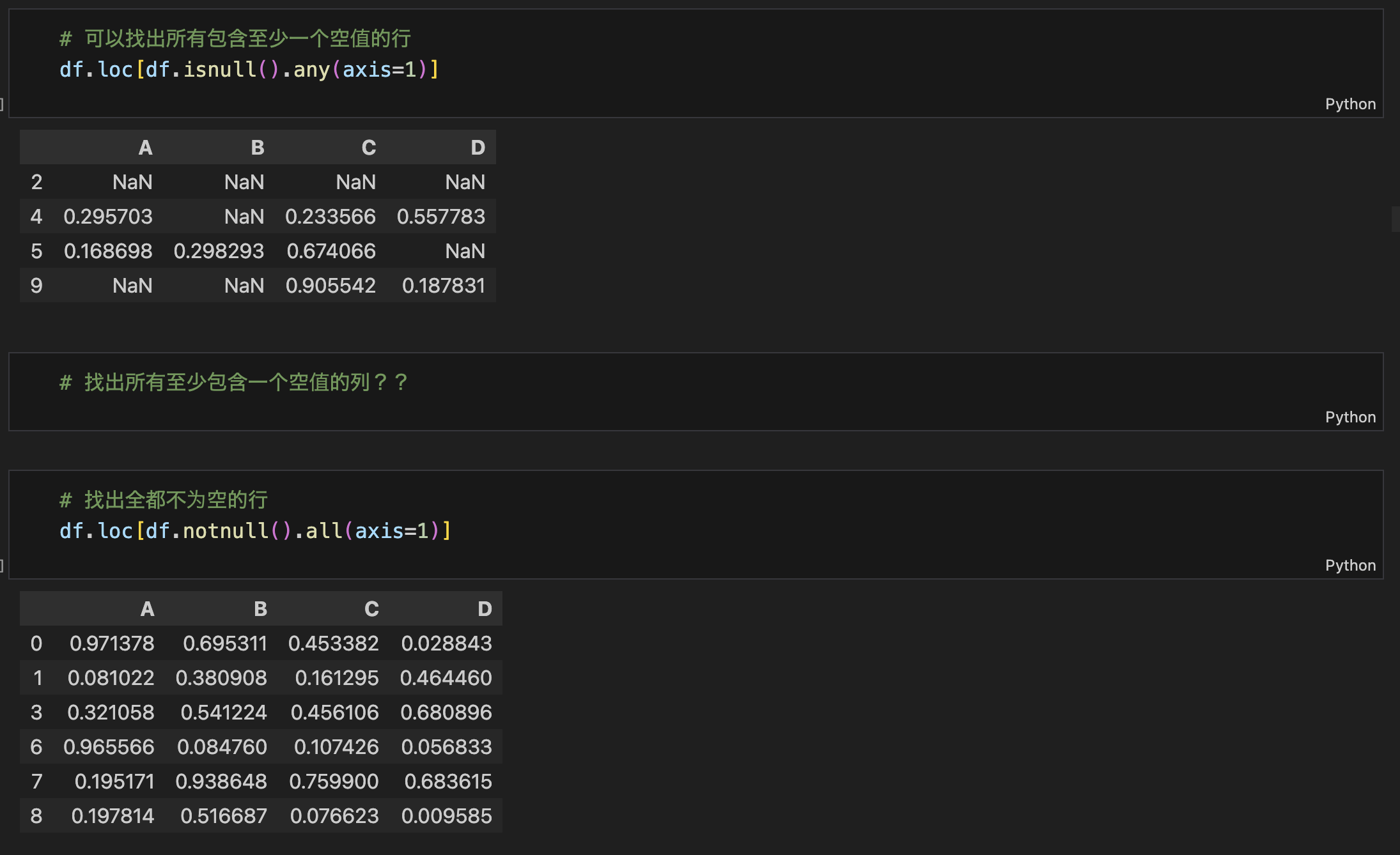
过滤出非空数据
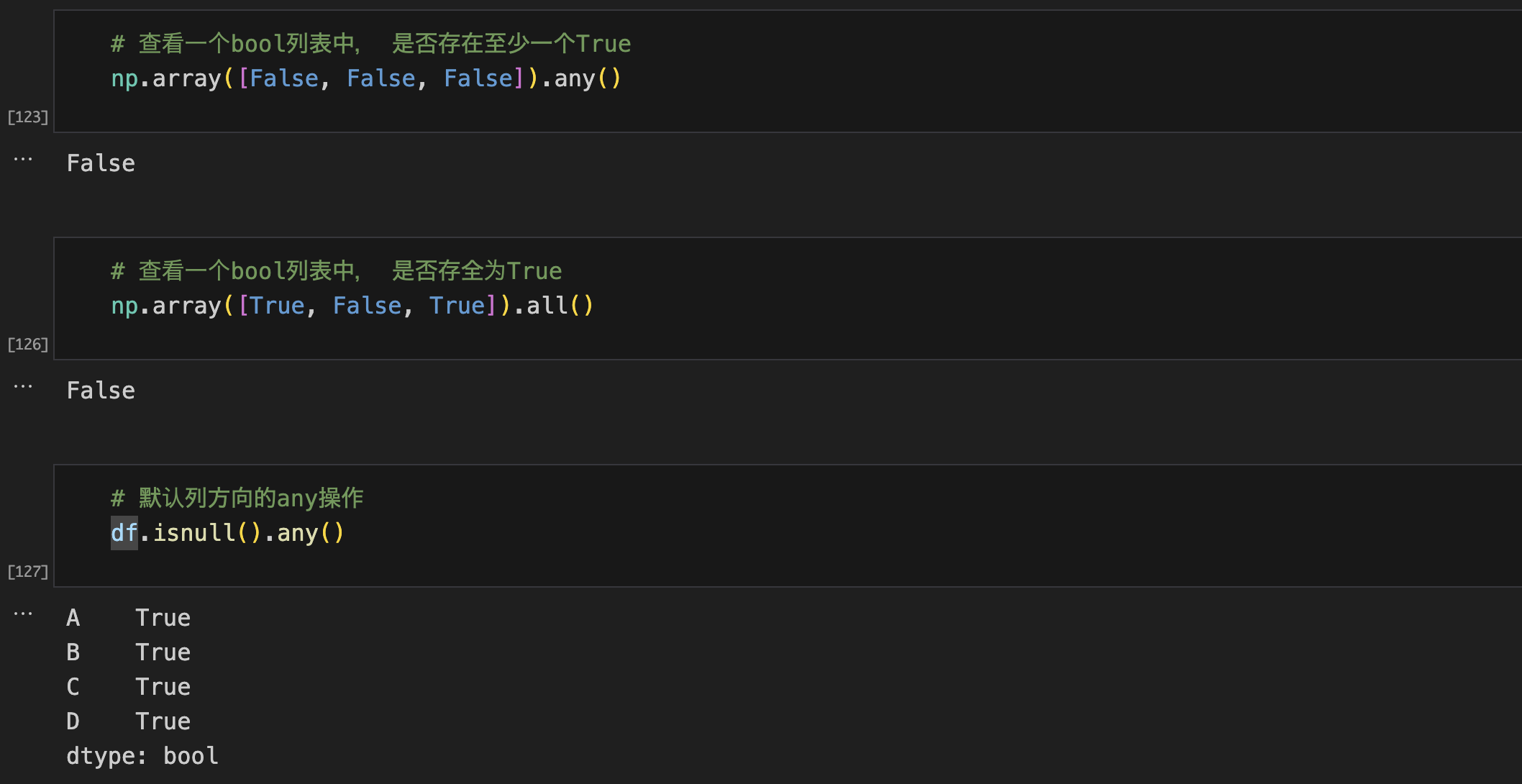
isnull(),notnull()any(),all()以上两个函数结合来确定一个最终条件,然后再利用loc访问,实现过滤非空数据
删除有空值的行
dropna()
过滤非空数据
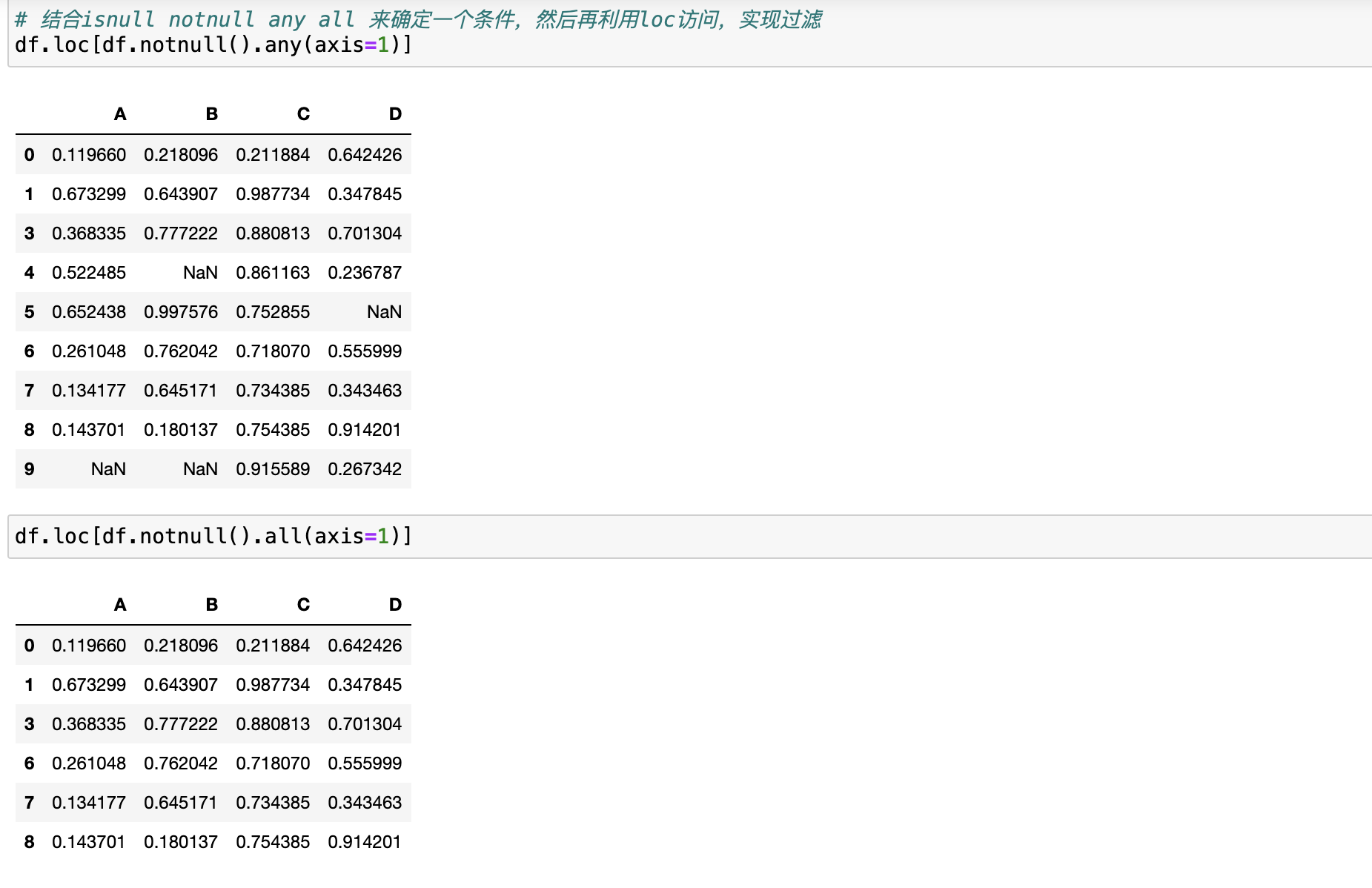
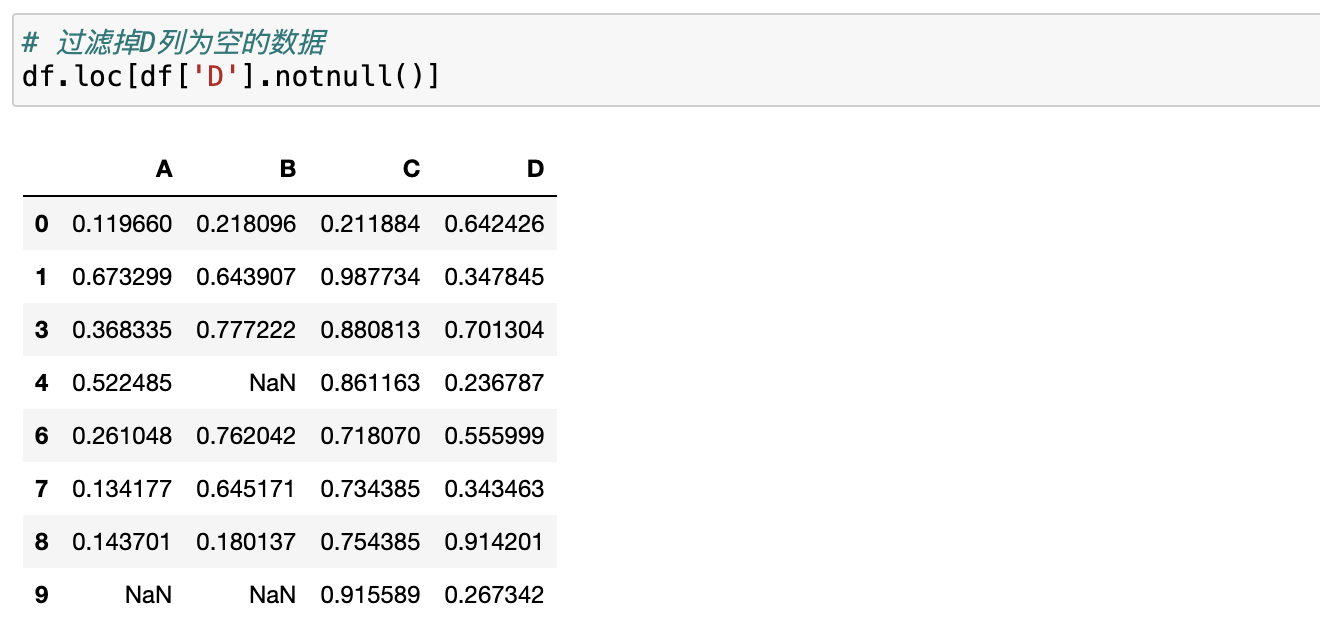
删除空值
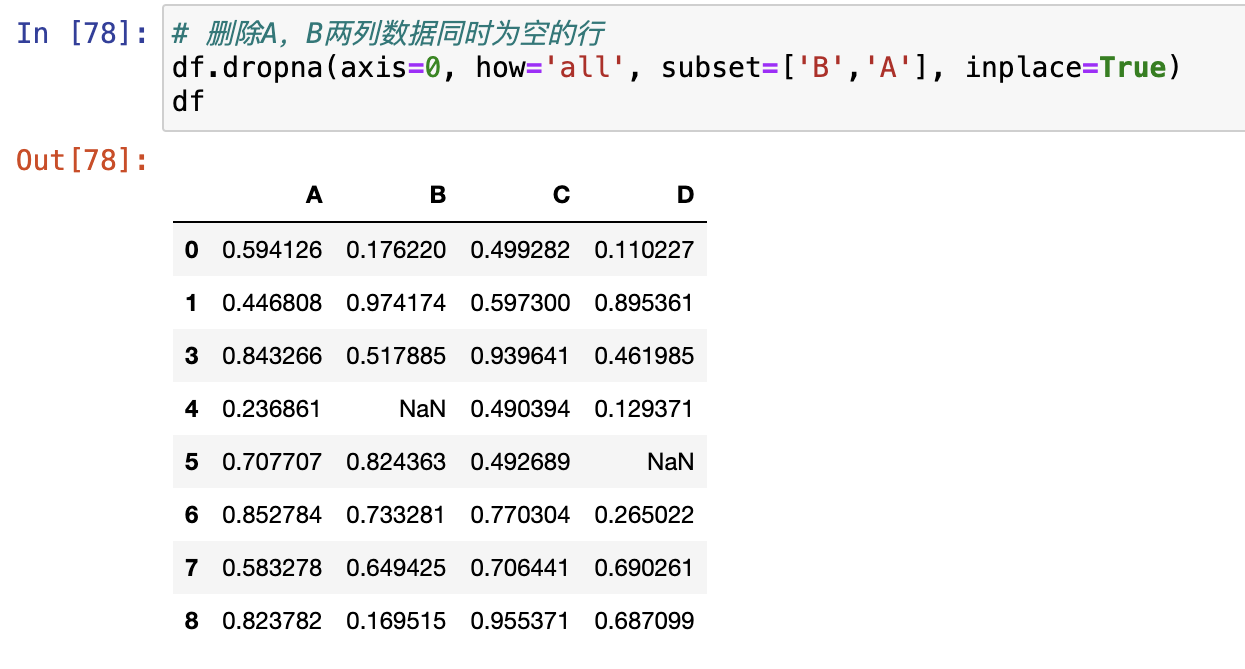
异常值处理
异常值:简单说就是不能代表普遍规律的值,用来建模会出问题
- 不符合统计学特征的值
- 不符合业务逻辑的值
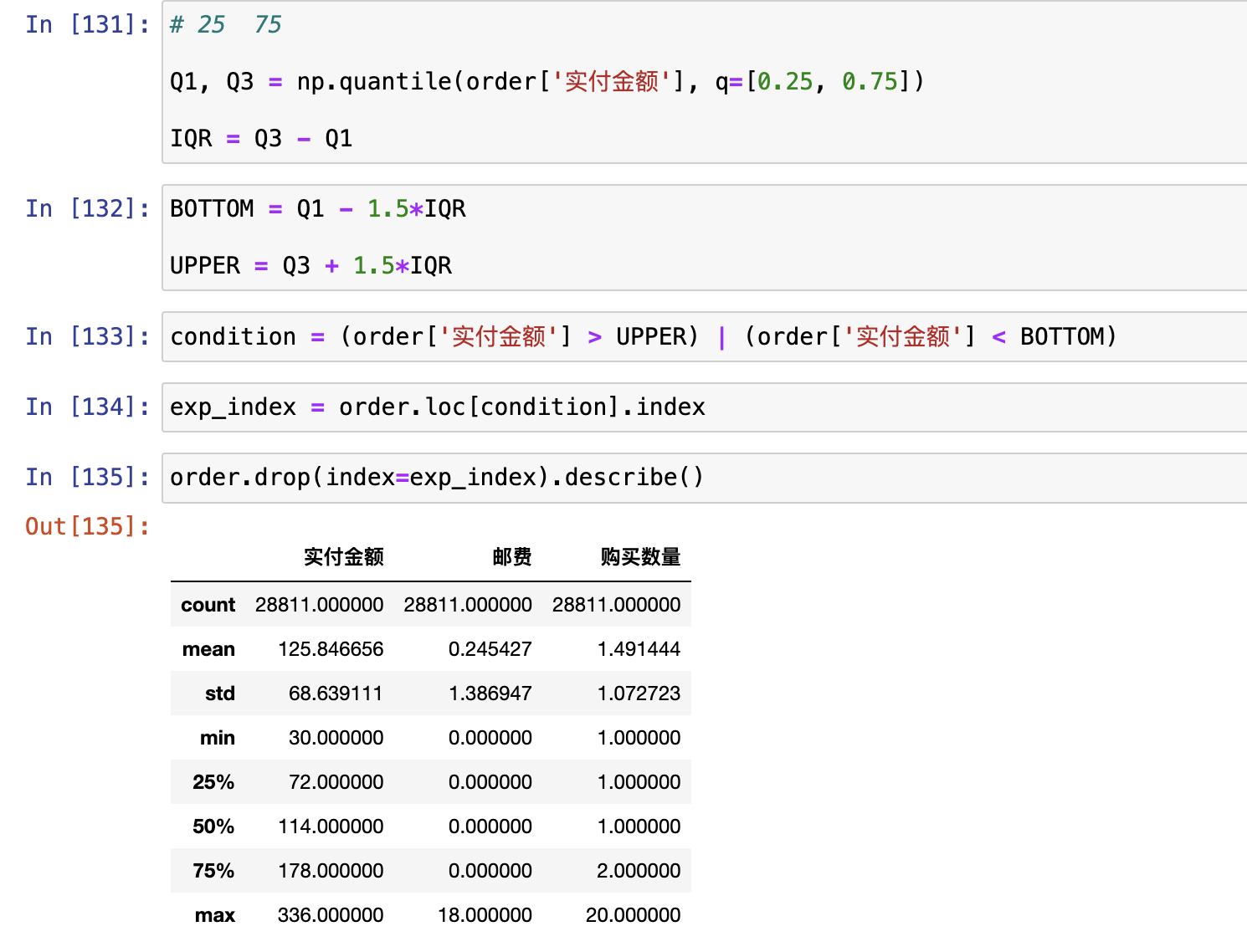
异常值分析
使用describe()来分写每一列的描述性统计量
异常值认定
不符合业务逻辑的异常值

使用平均值和标准差进行判断
大于3倍标准差的可以视为异常值
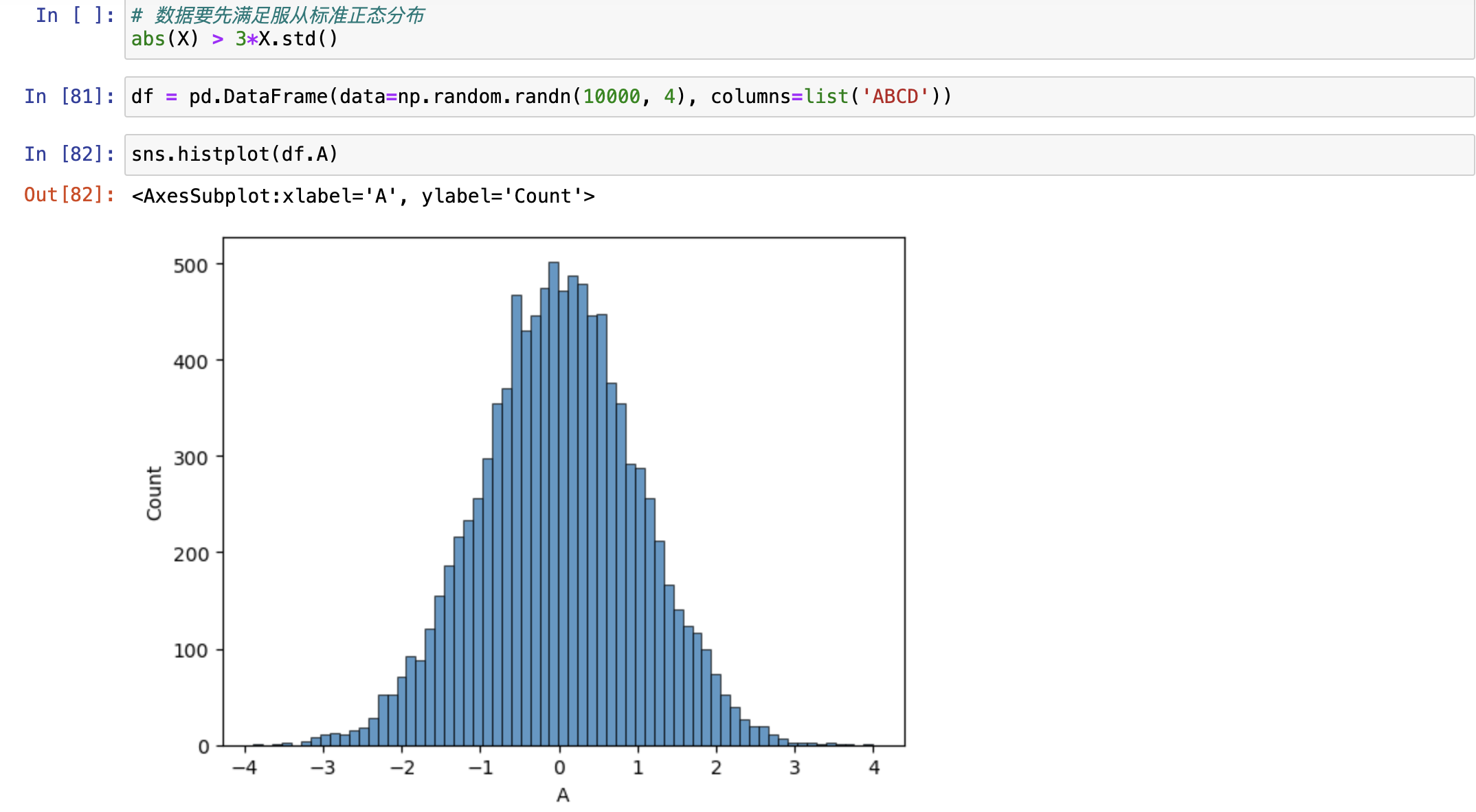
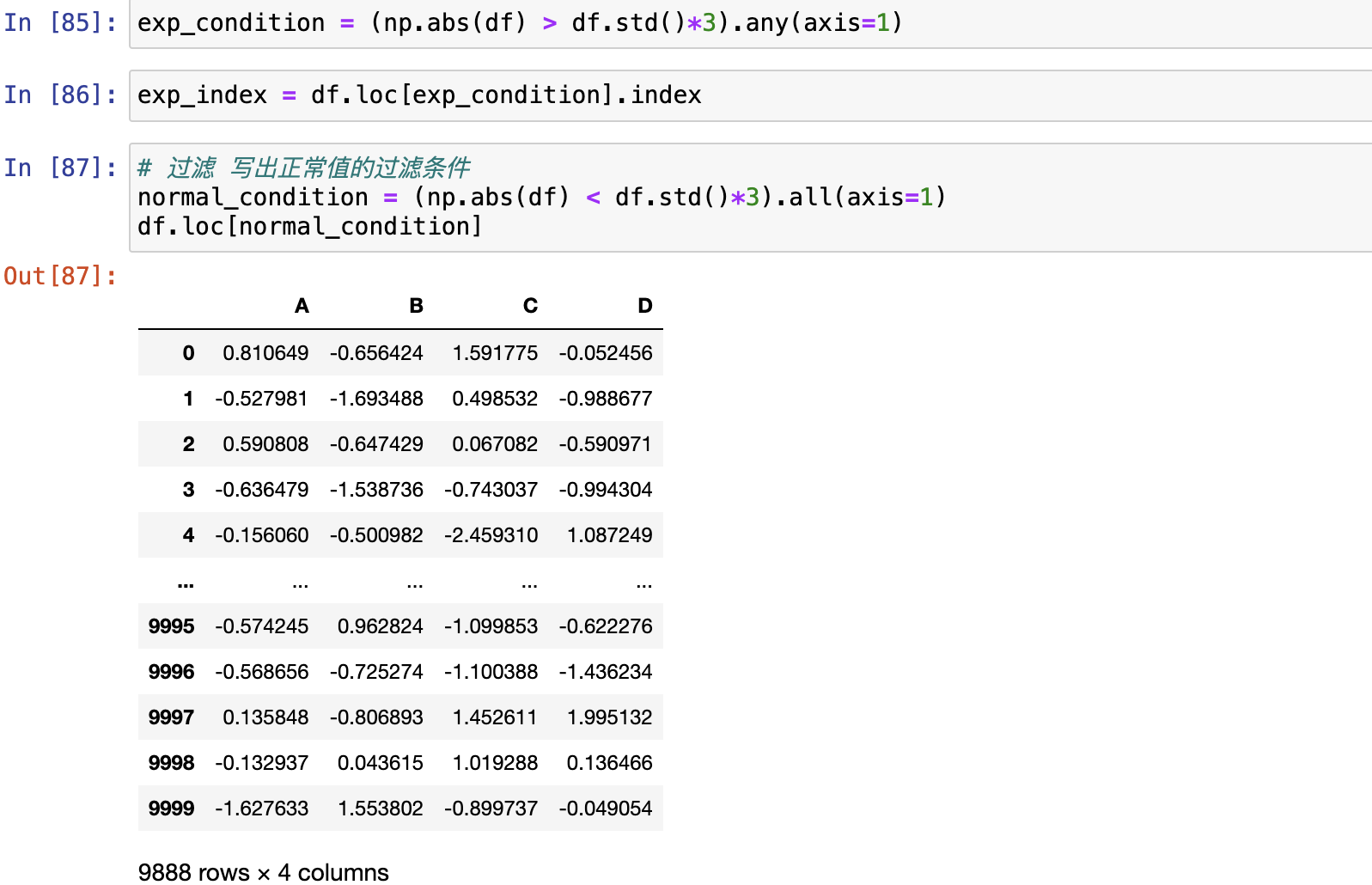

使用上四中位数和下四中位数进行异常值判定
- ,可以先画个箱型图看一眼
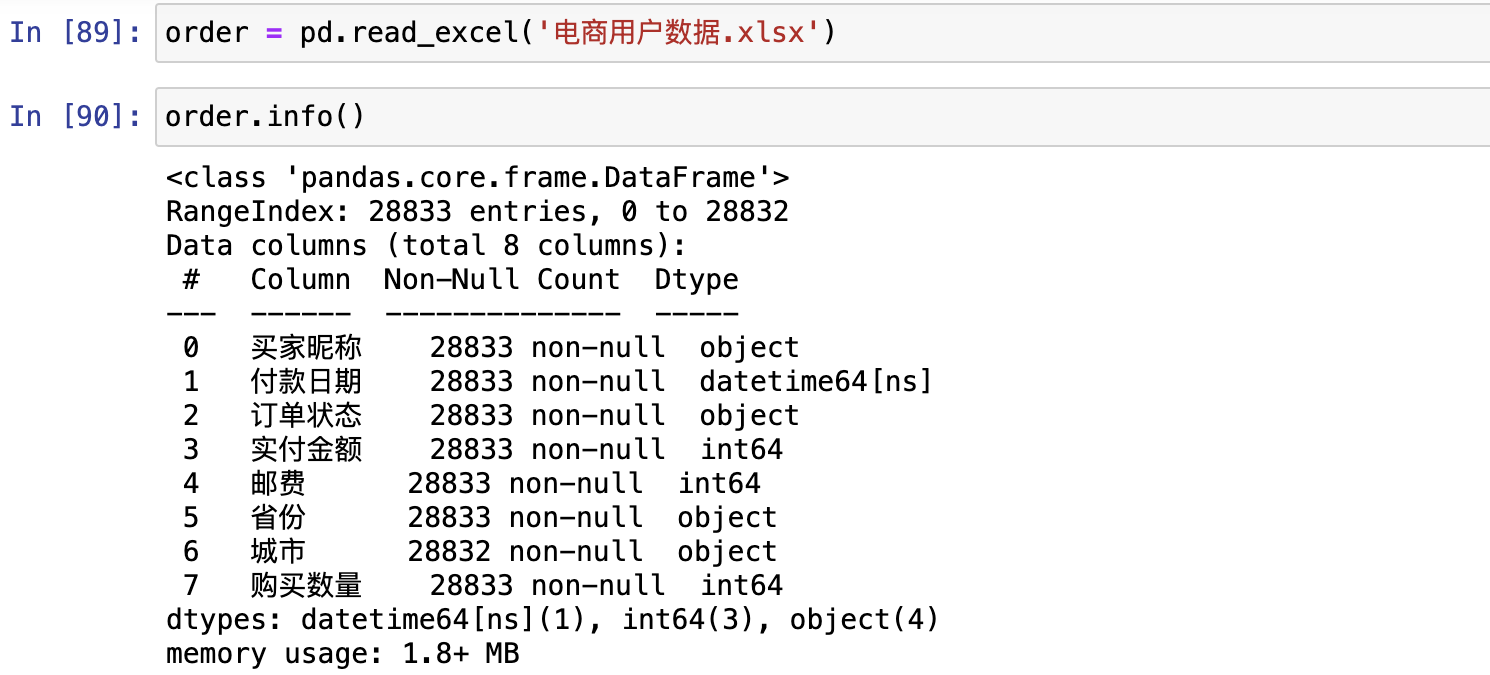
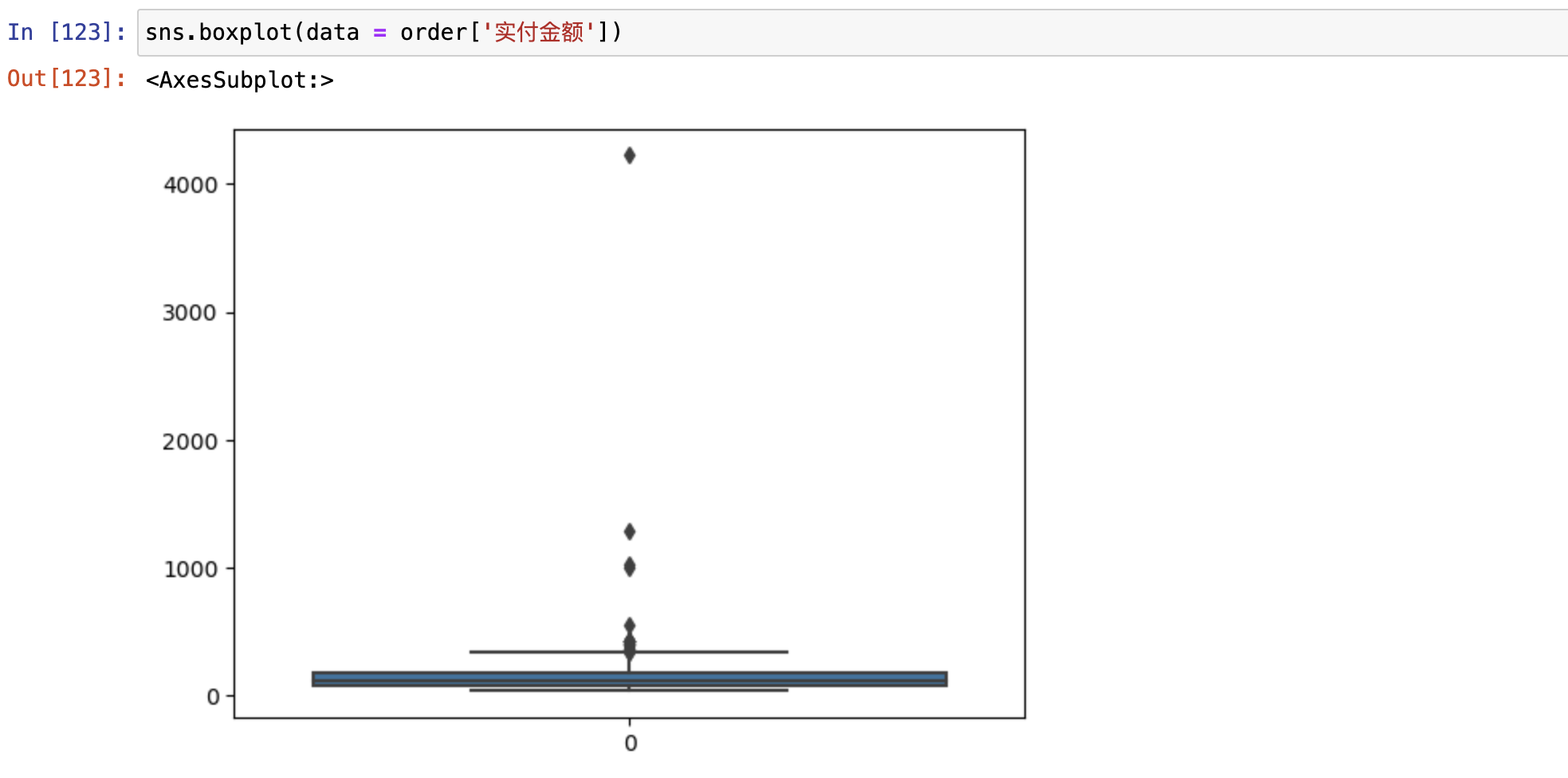
异常值处理
- 删除
df.drop()
- 过滤
过滤删除本质是一样的,不必特意区分
重复值处理
- 检查
- 过滤
- 删除方法
检查重复值
df.duplicated()
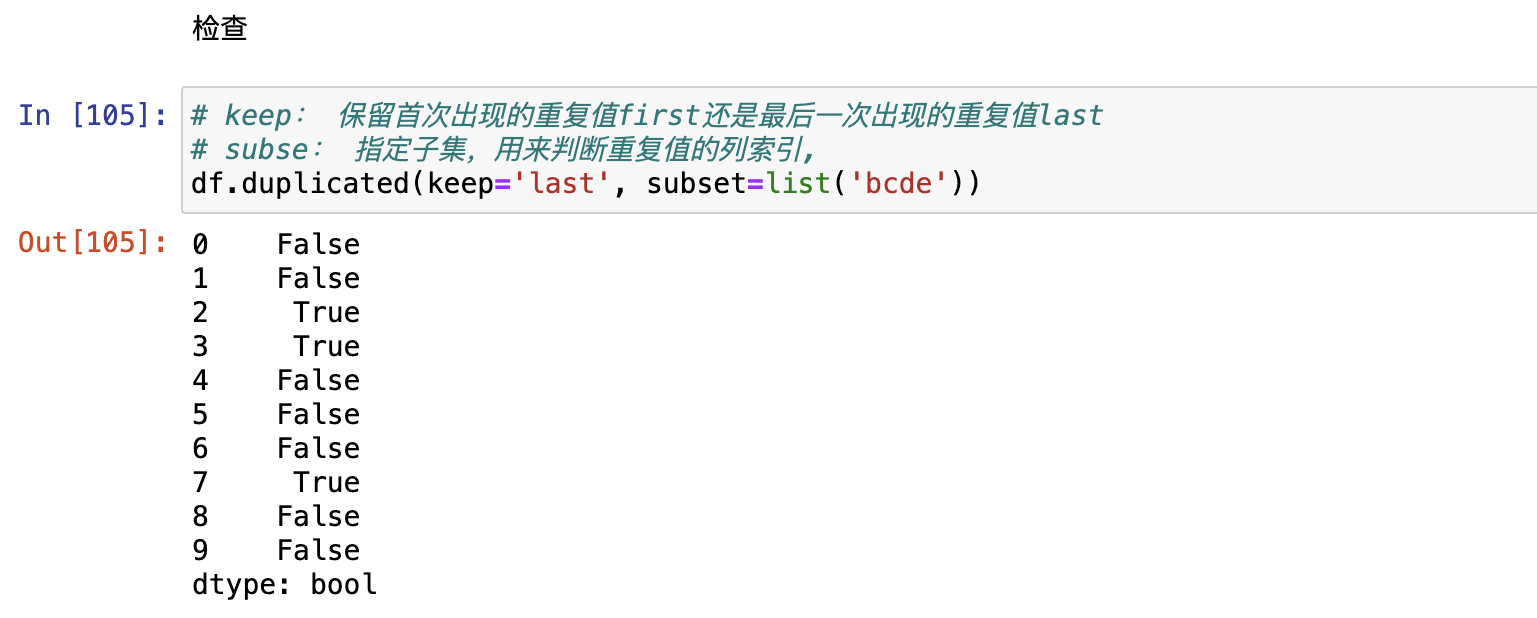
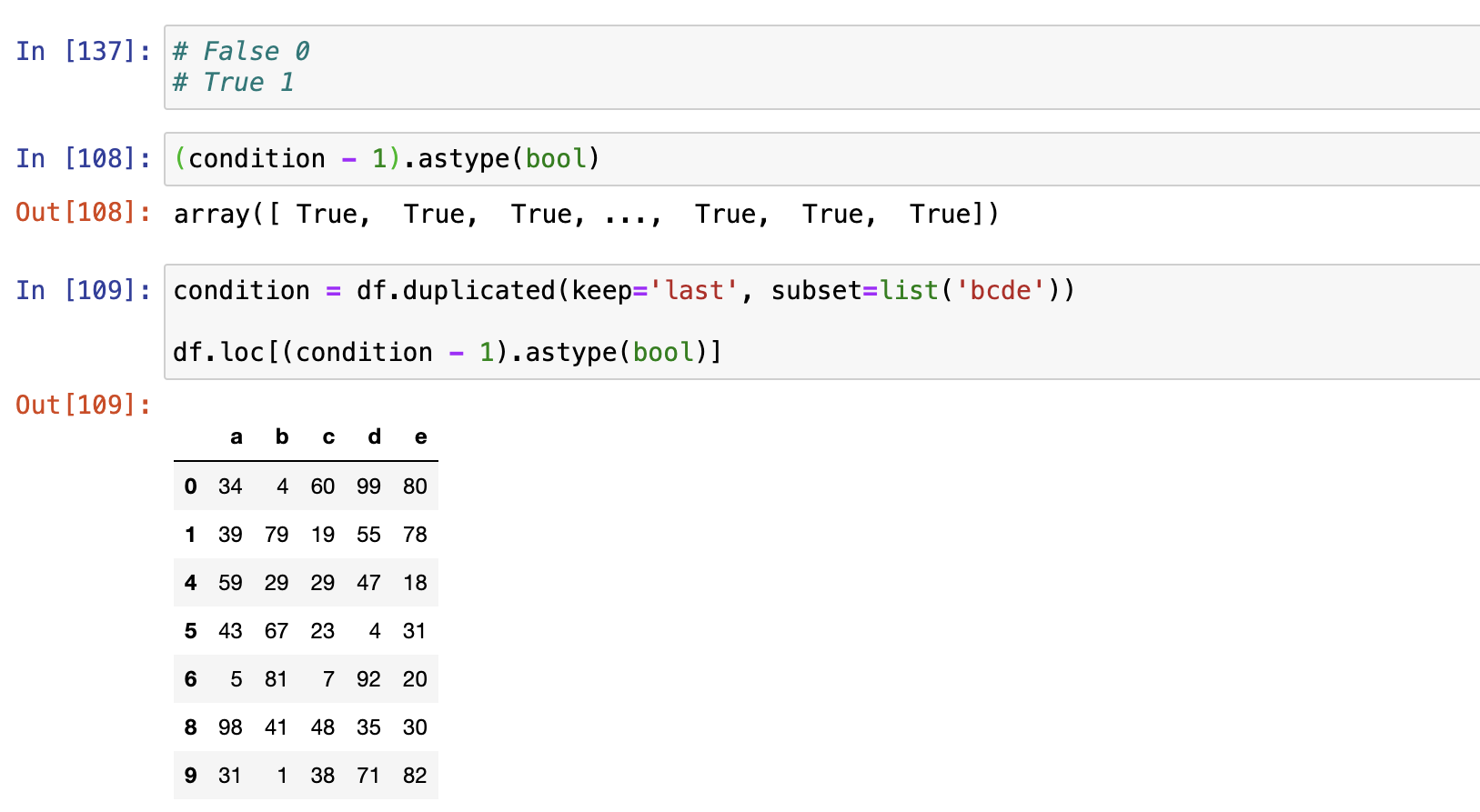
过滤重复值
删除重复值
drop_duplicates()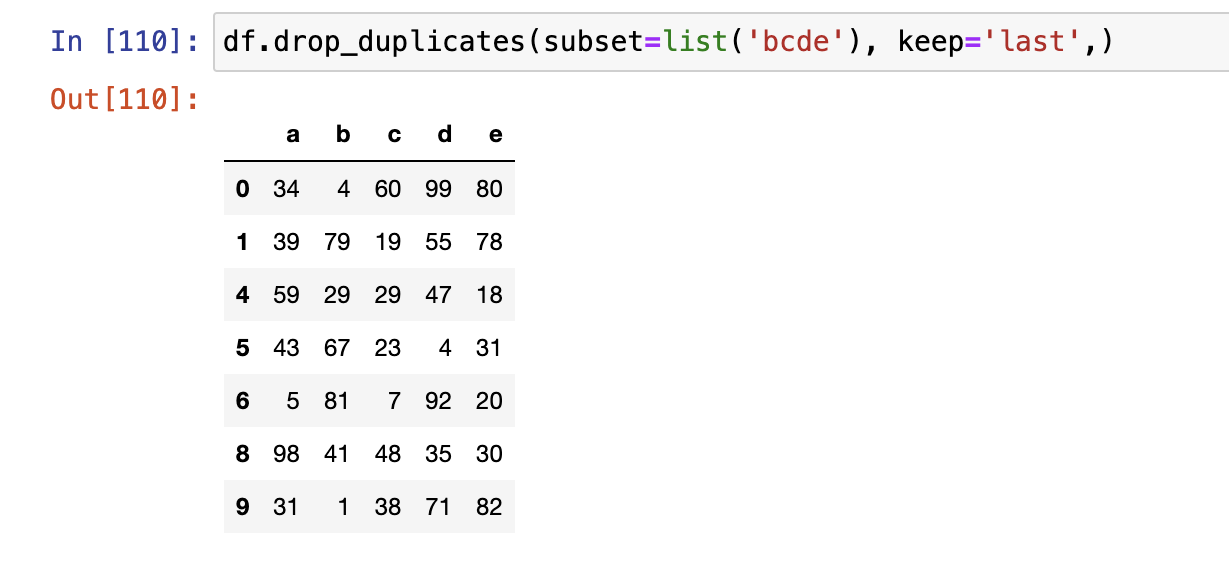
删除重复值之后,索引是乱的,重置索引
python# 把reset_index() 里的drop参数设置为True即可 df_area_process.drop_duplicates().reset_index(drop=True)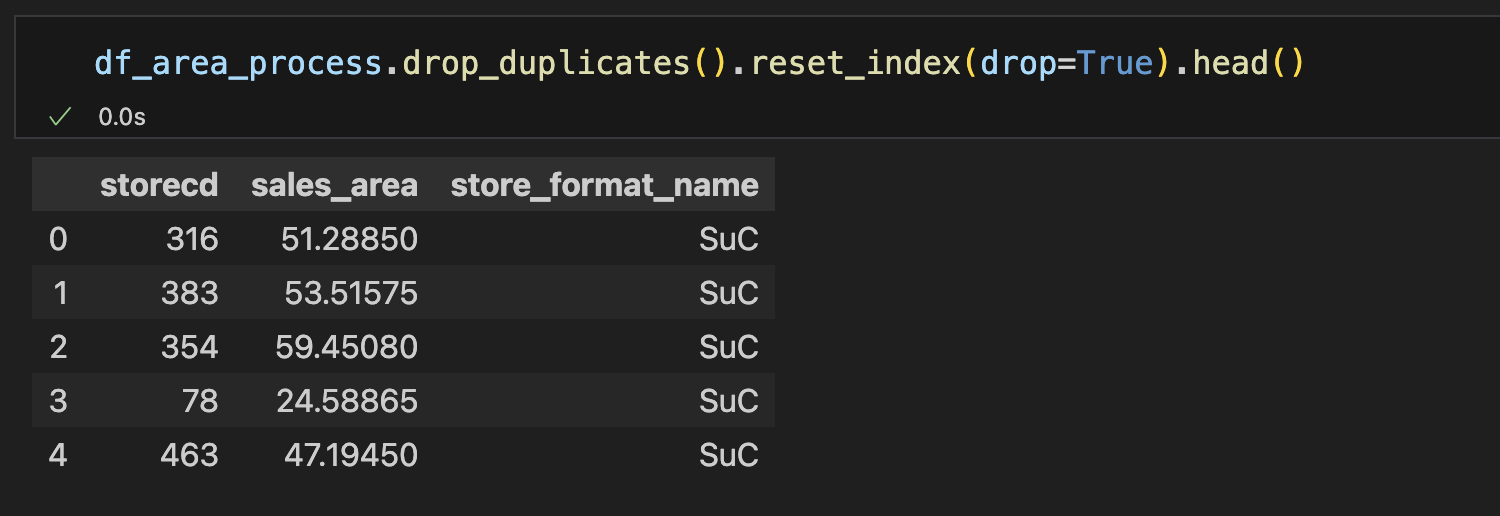
通用的
dropo()函数
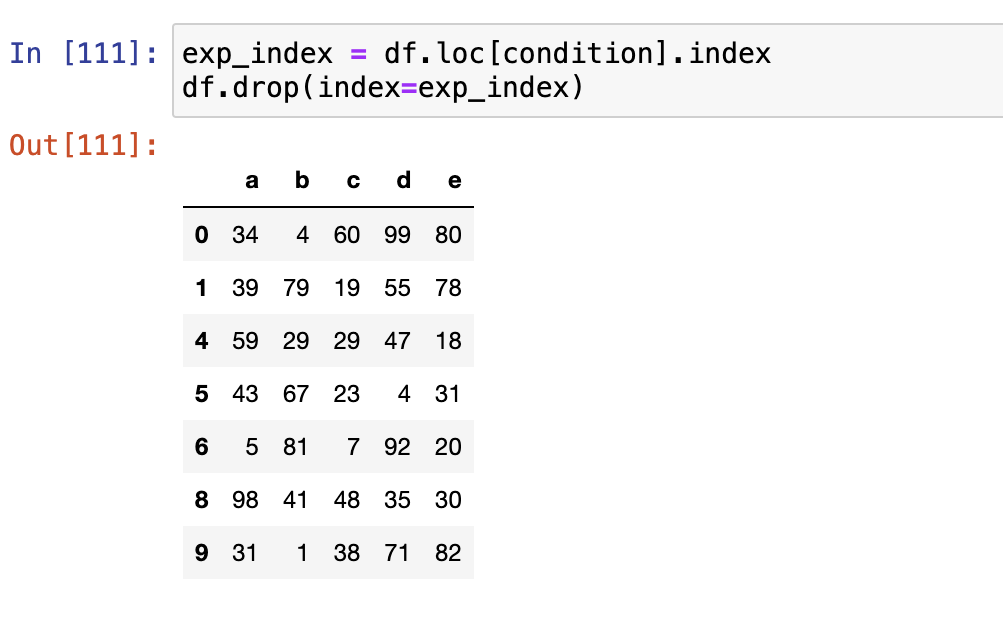
排序与随机抽样
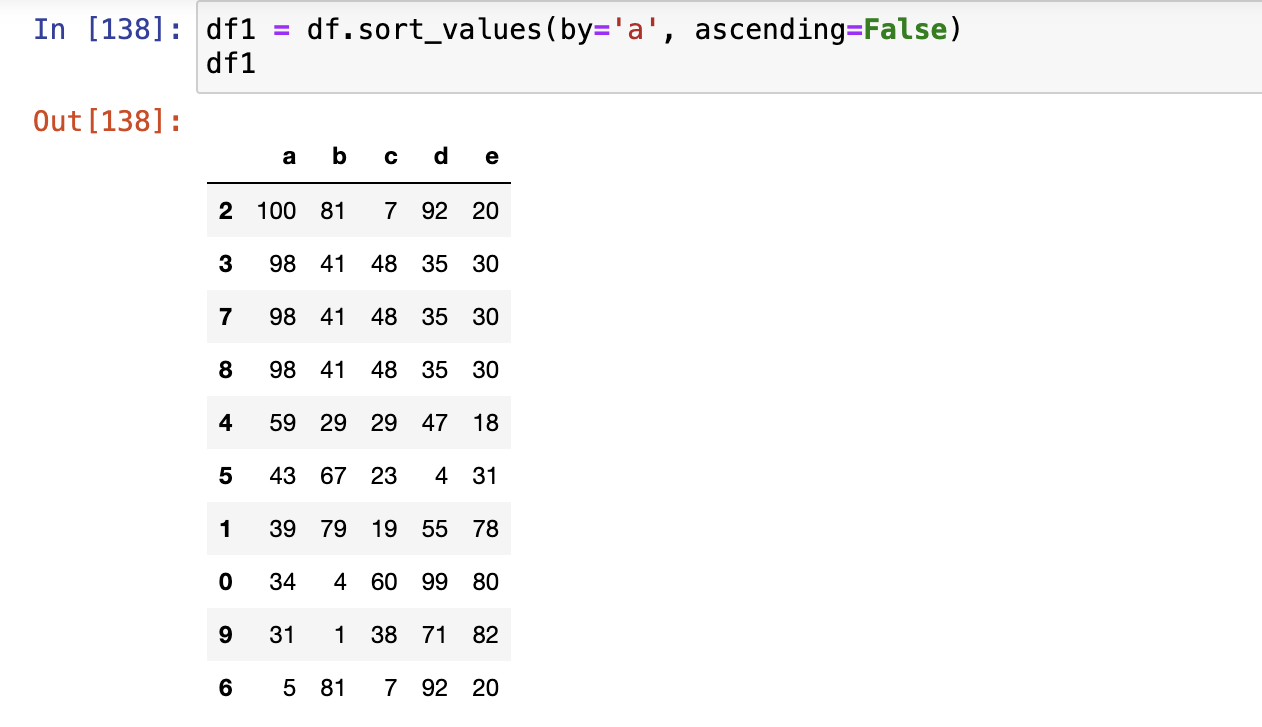
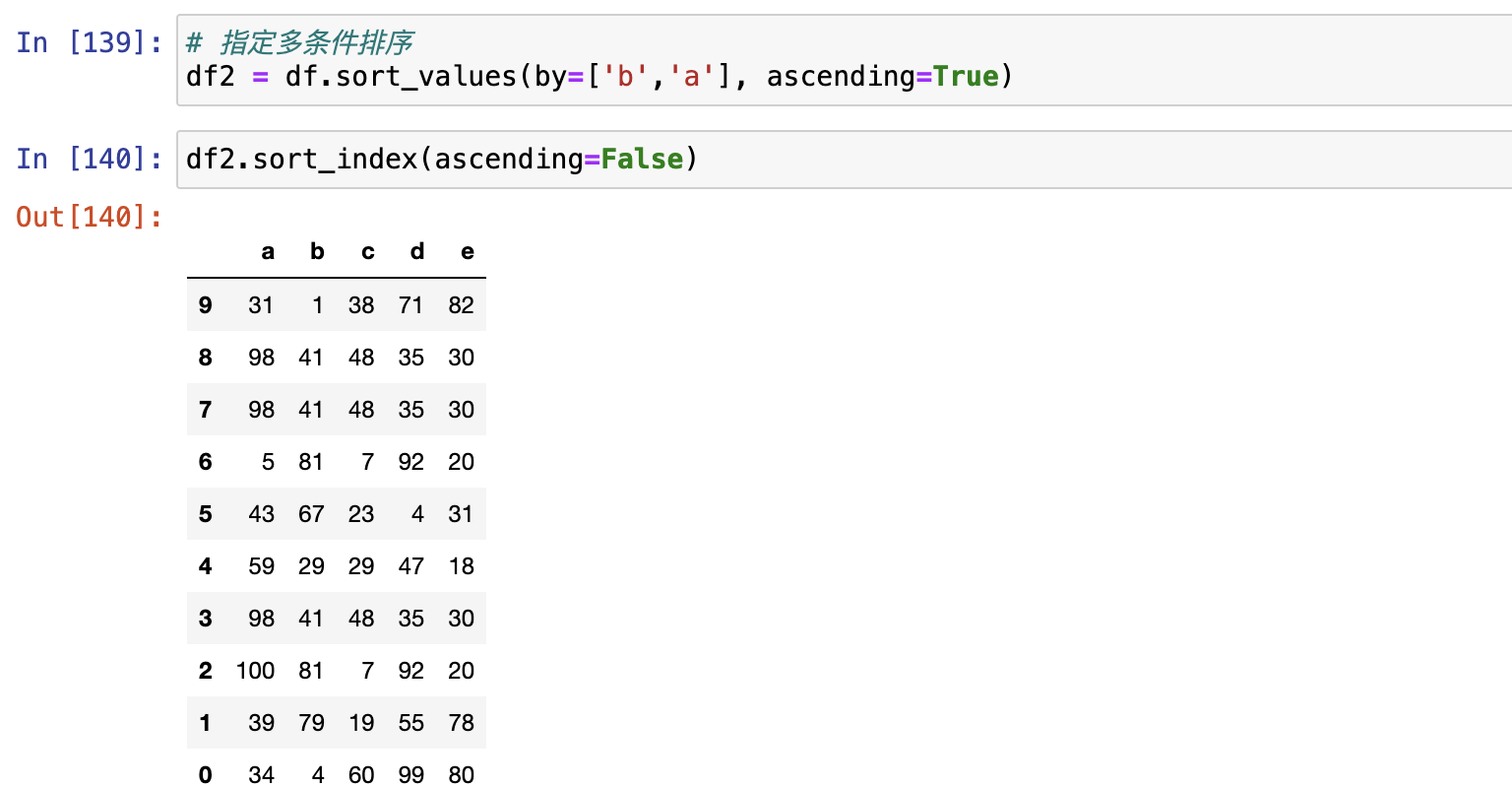
排序
sort_index()sort_values()
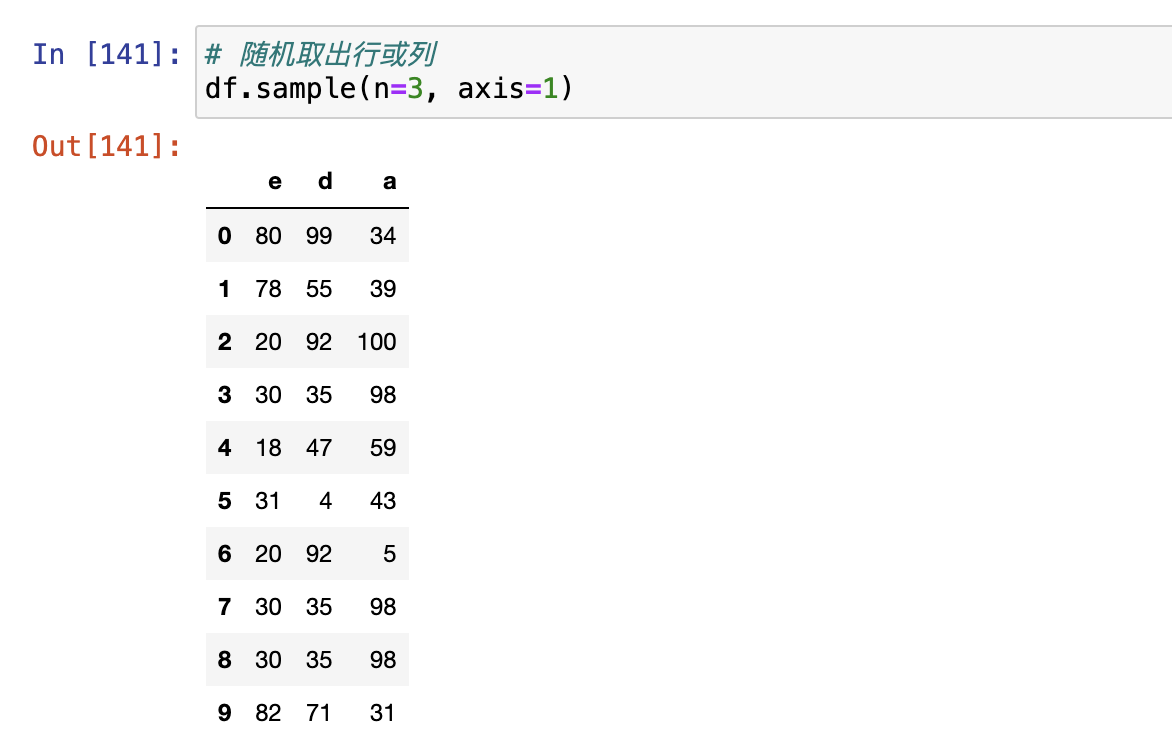
随机抽样
sample(),随机取n行或n列。take(),传人索引且只关注隐式索引。
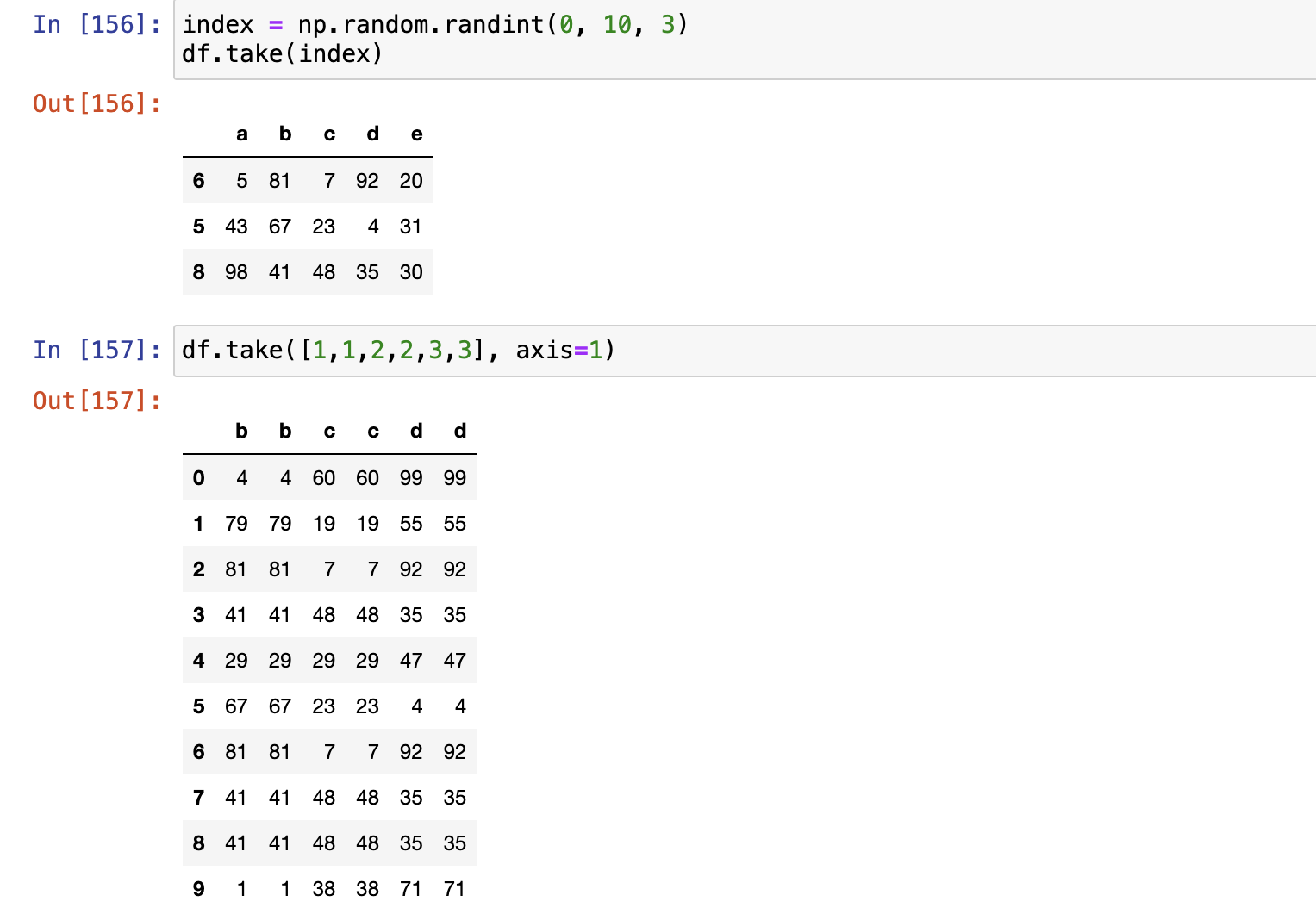
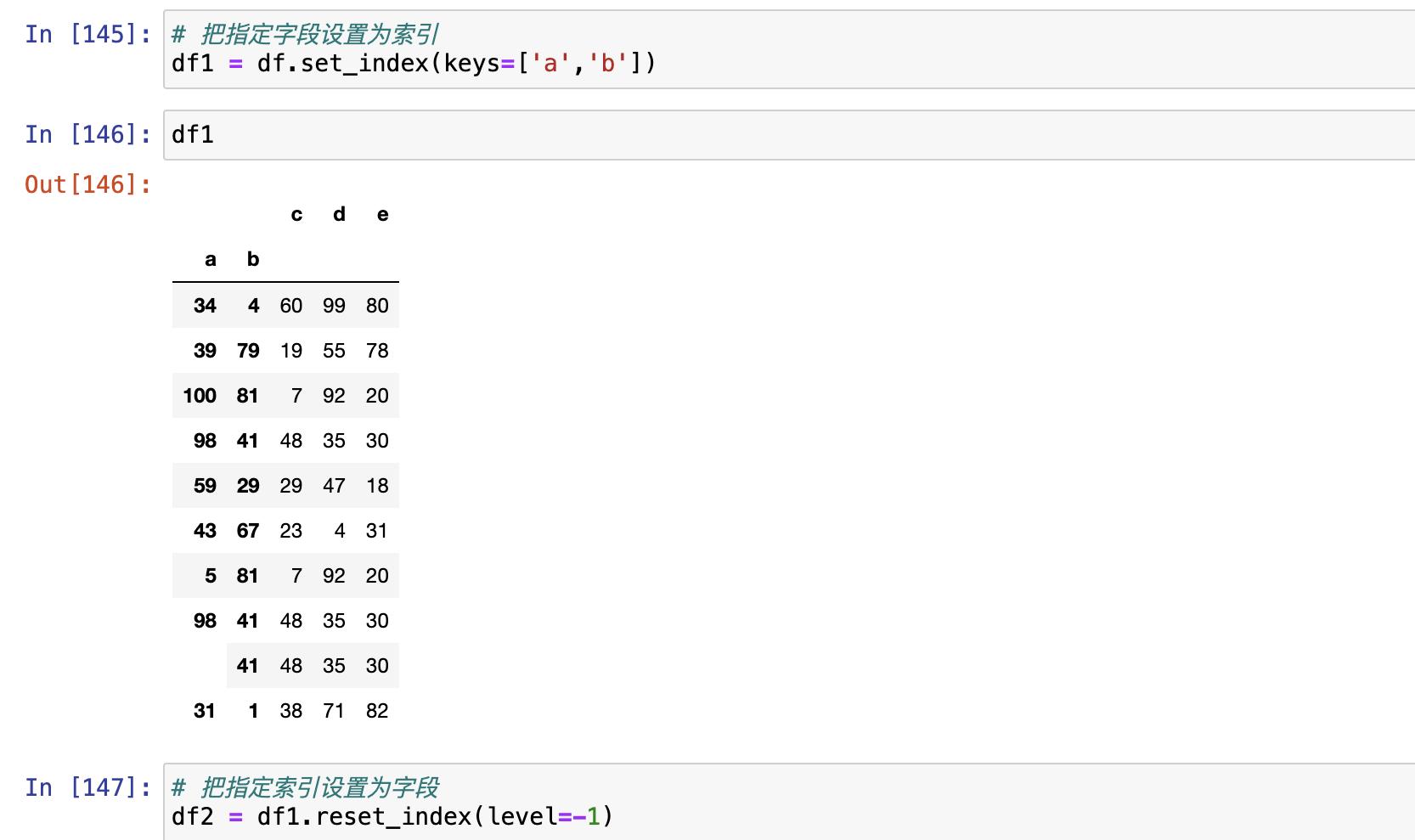
索引设置
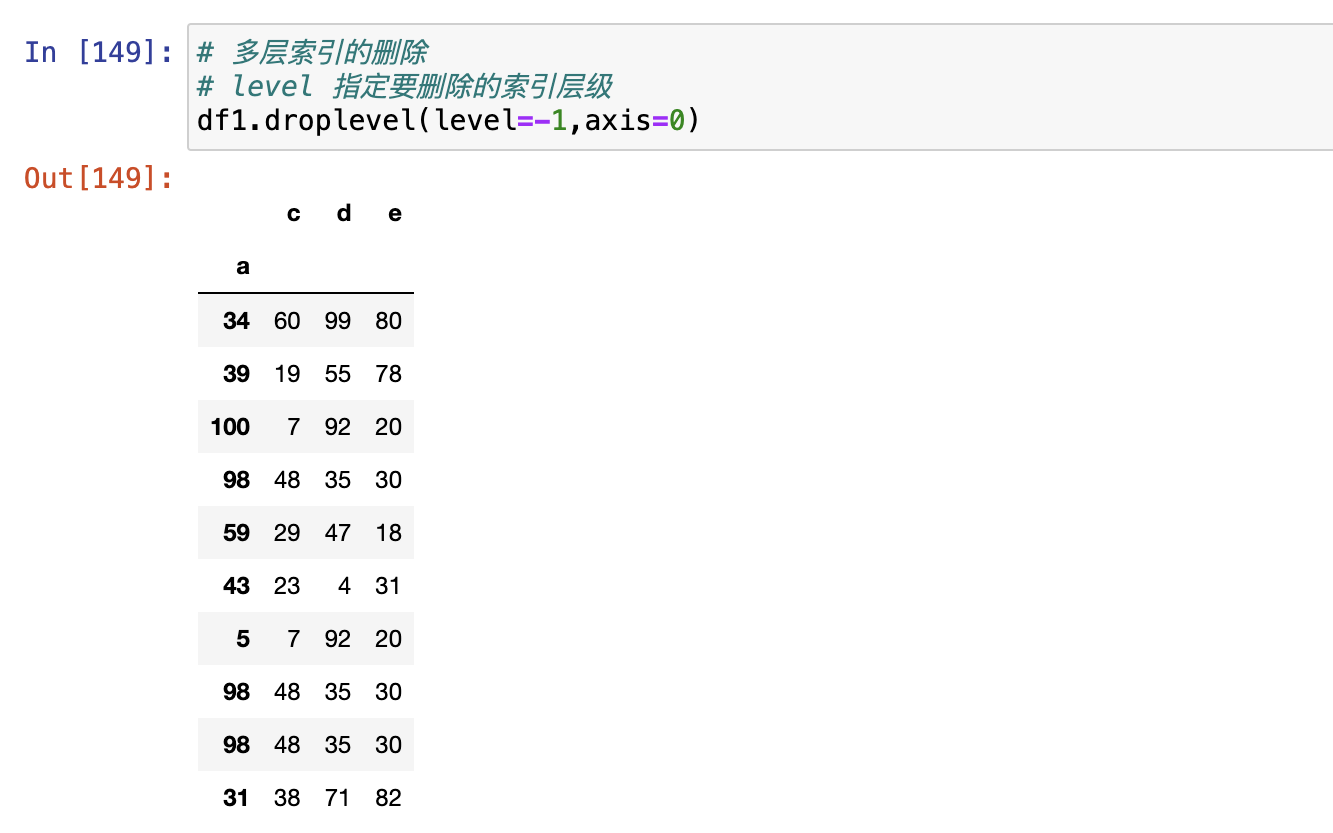
set_index(),把某一列数据设置为索引。reset_index(),把上面设置为索引的列恢复回去。reindex()droplevel()

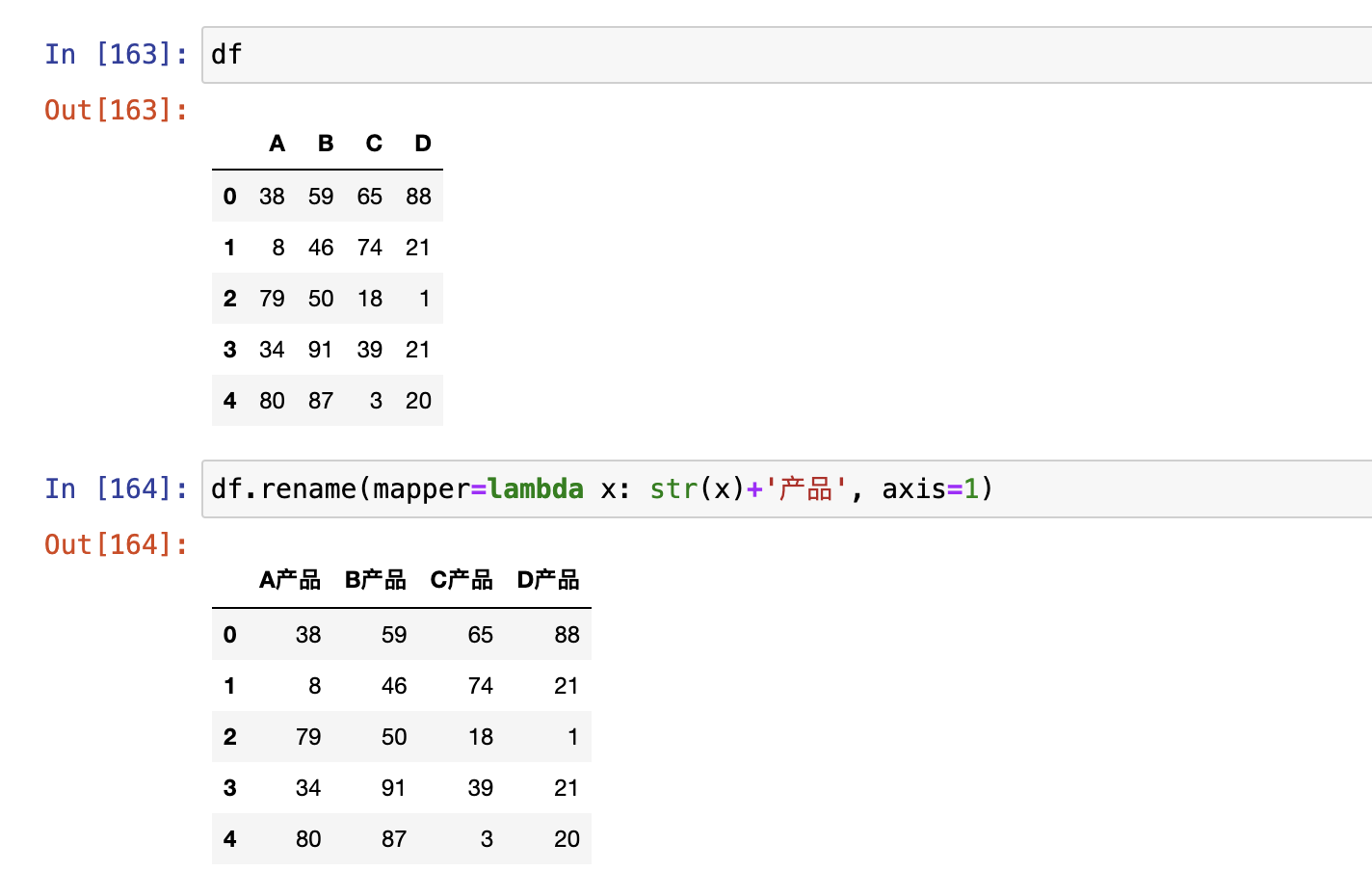
映射处理
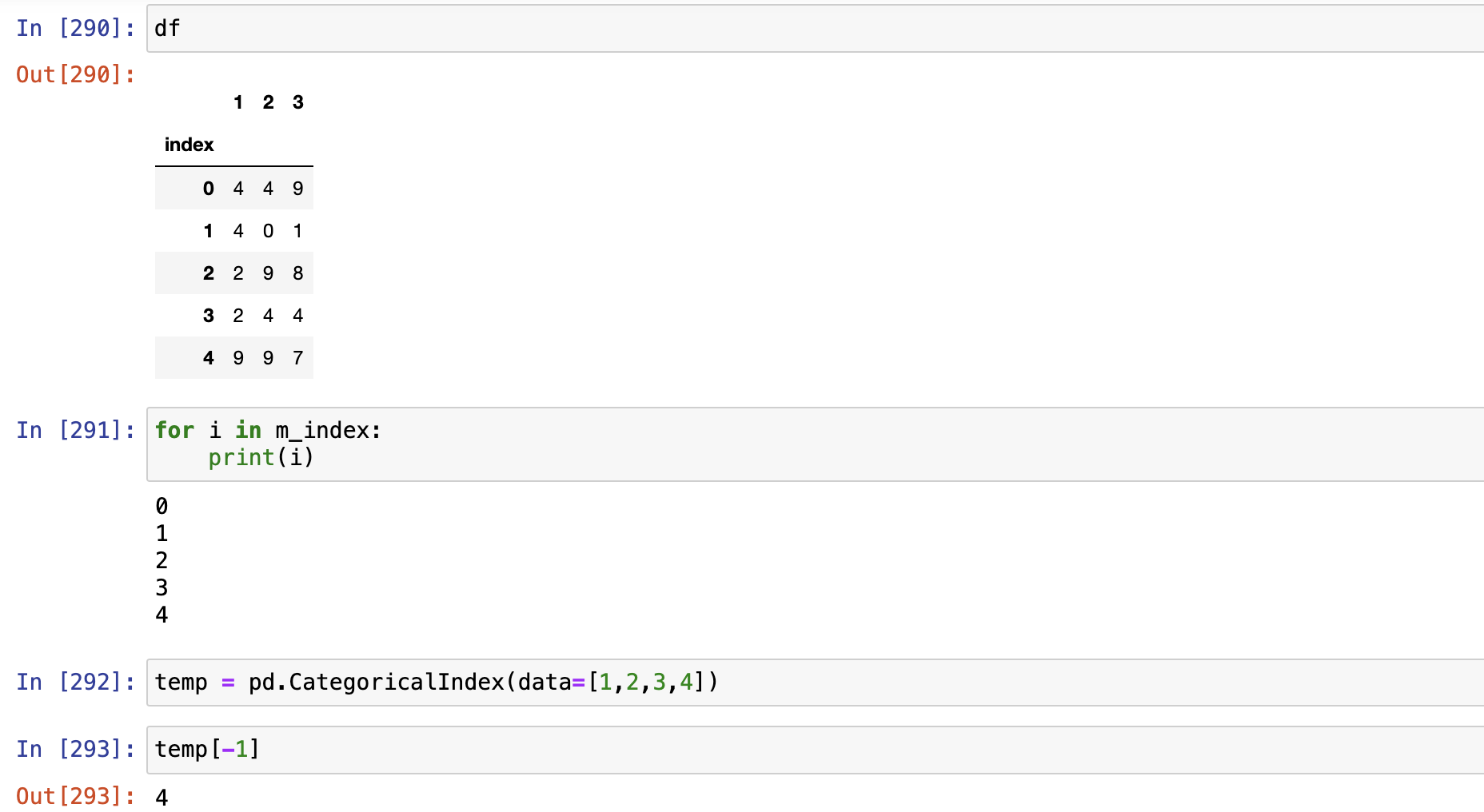
rename()replace()map()
rename()
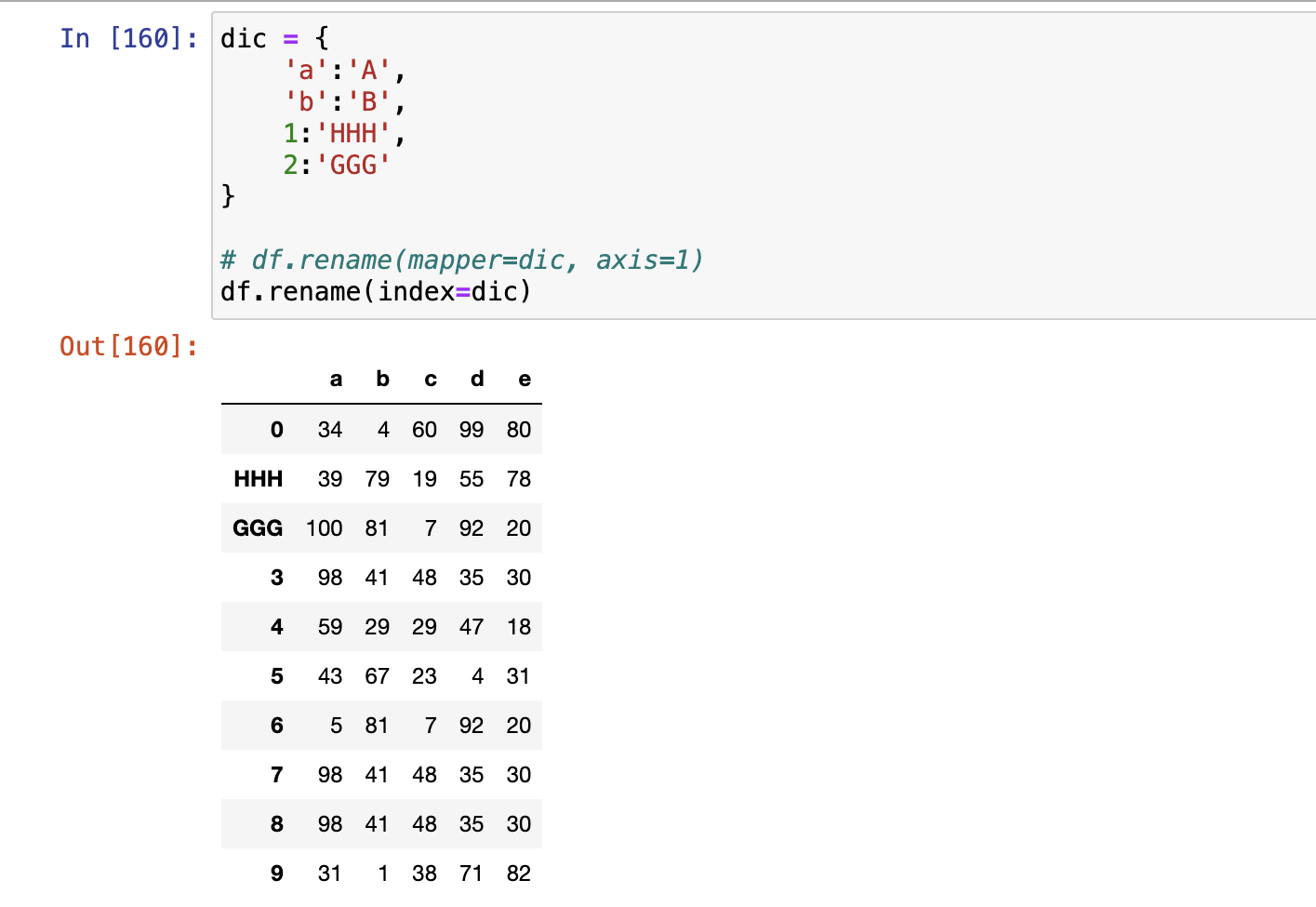
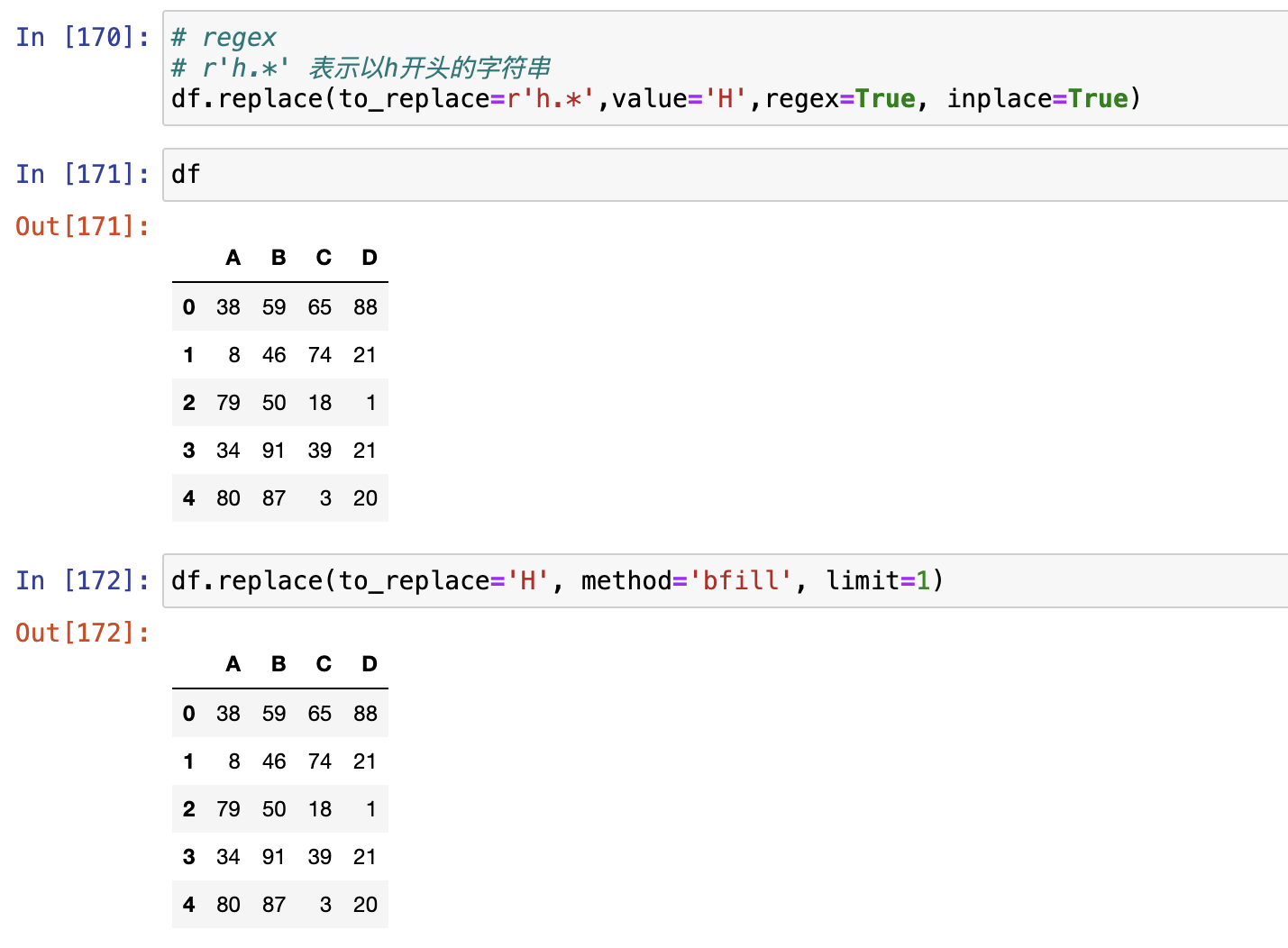
replace()
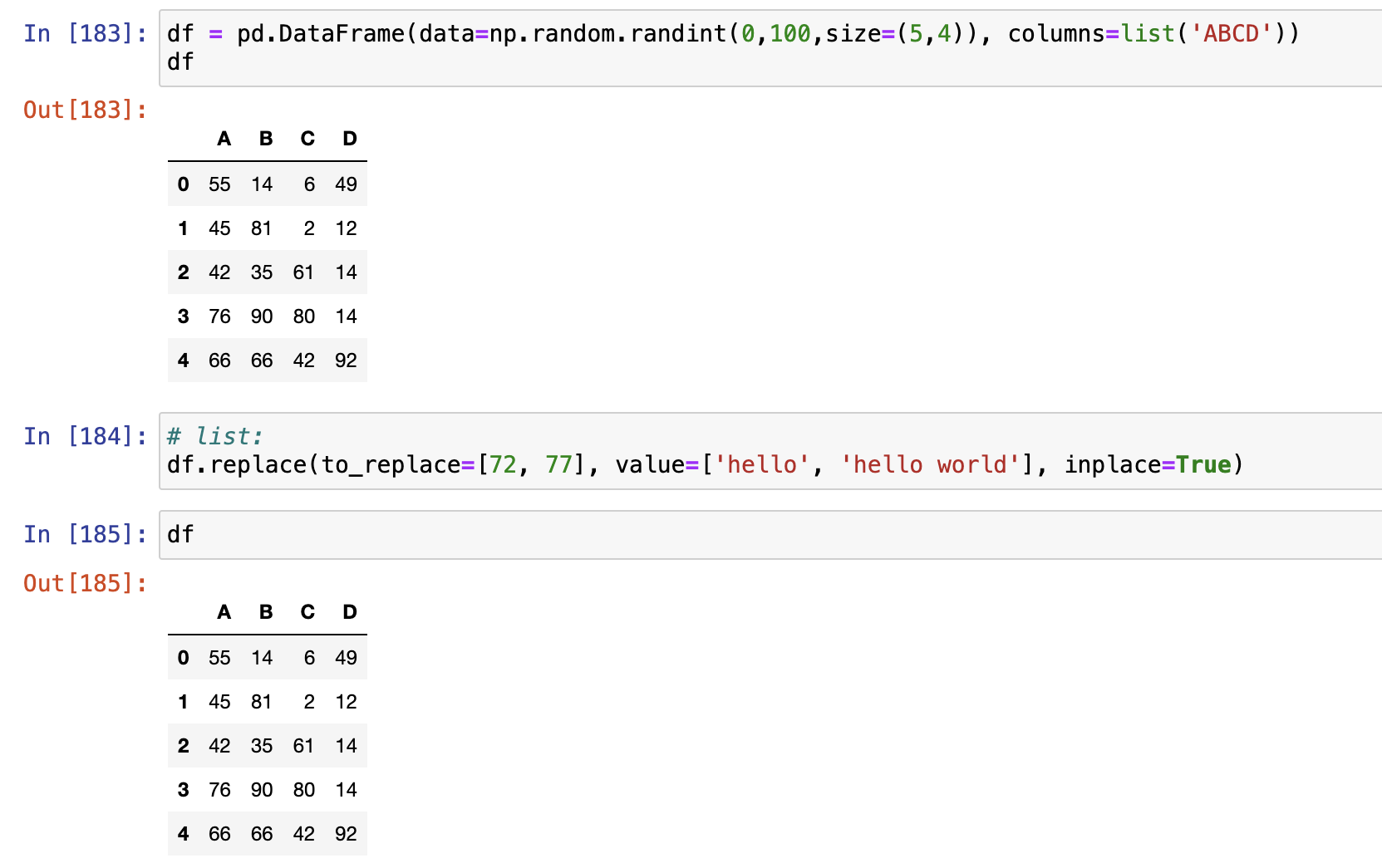
replace()支持Series对象和DataFrame对象
- list
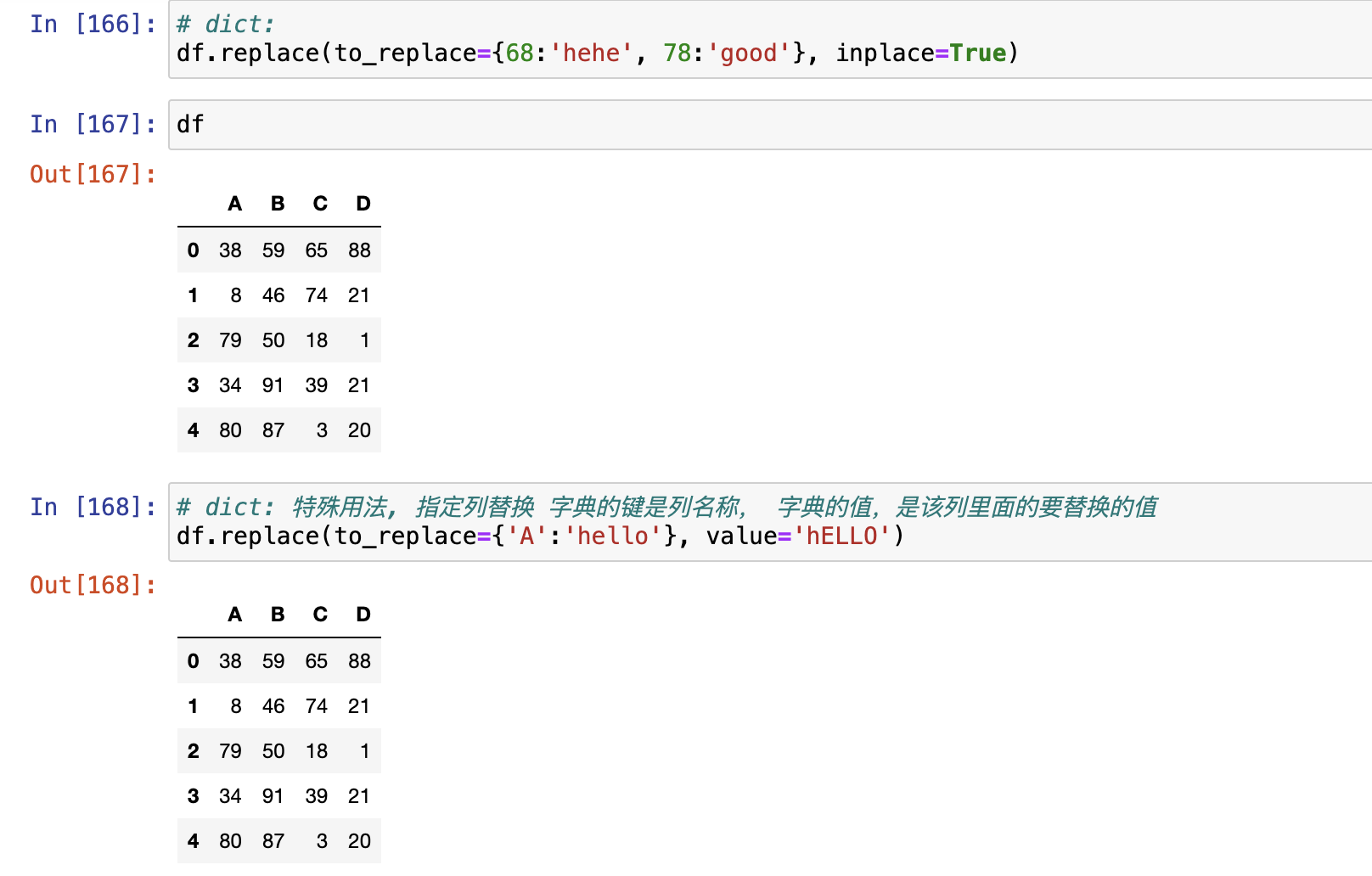
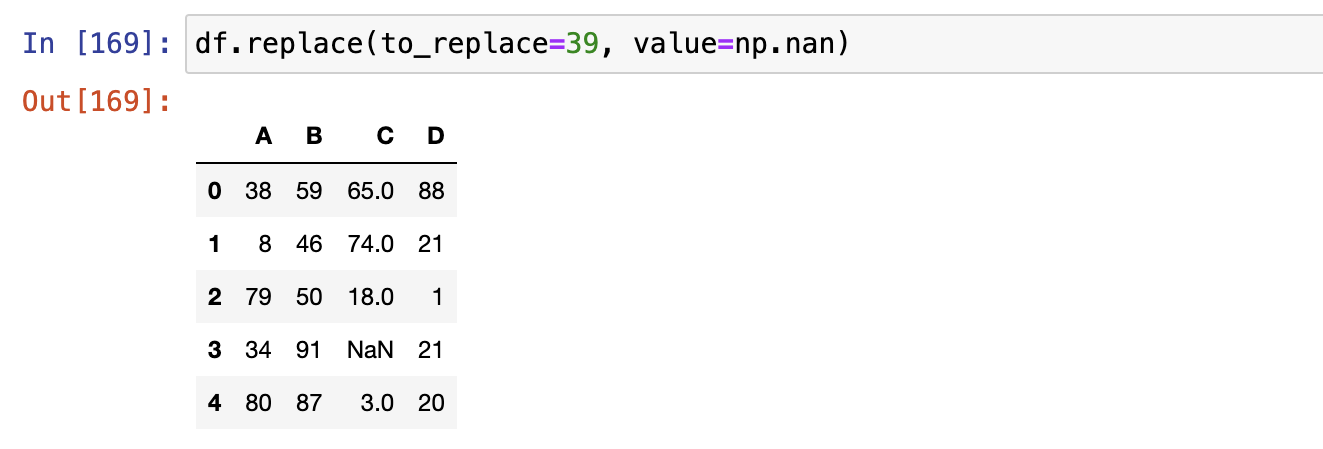
- dict
- regex
map()
map()只支持Seires对象,和replace()不同
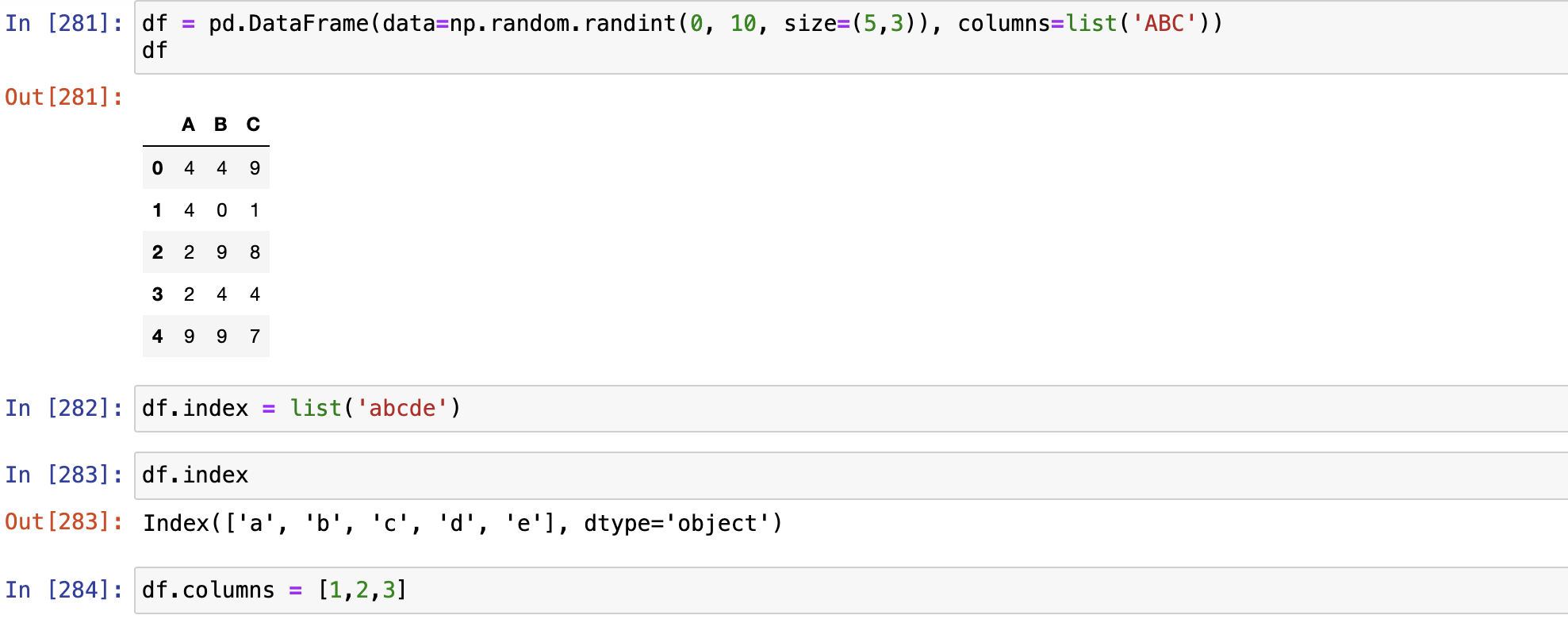
- 模糊匹配

- 精确匹配
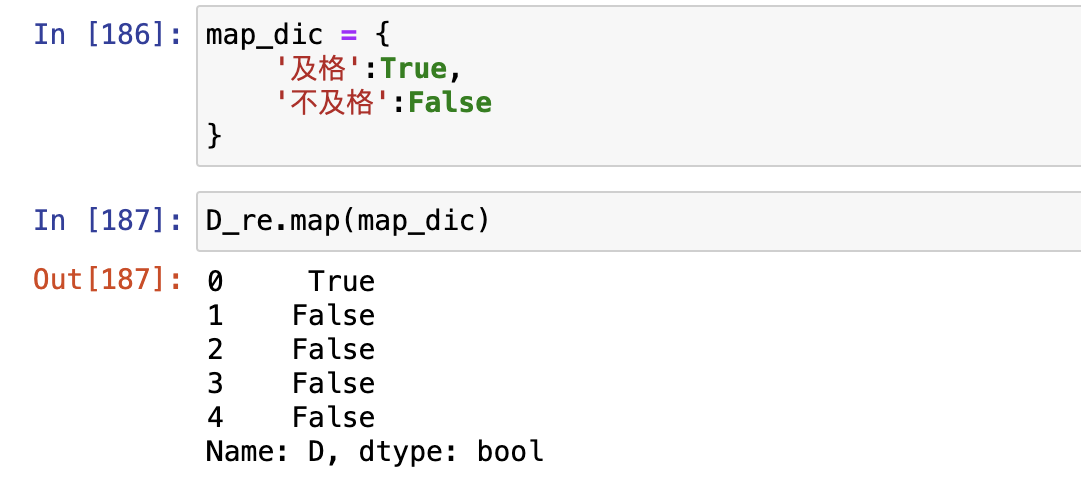
map()函数可以同时结合字典和函数使用,达到更精确的匹配
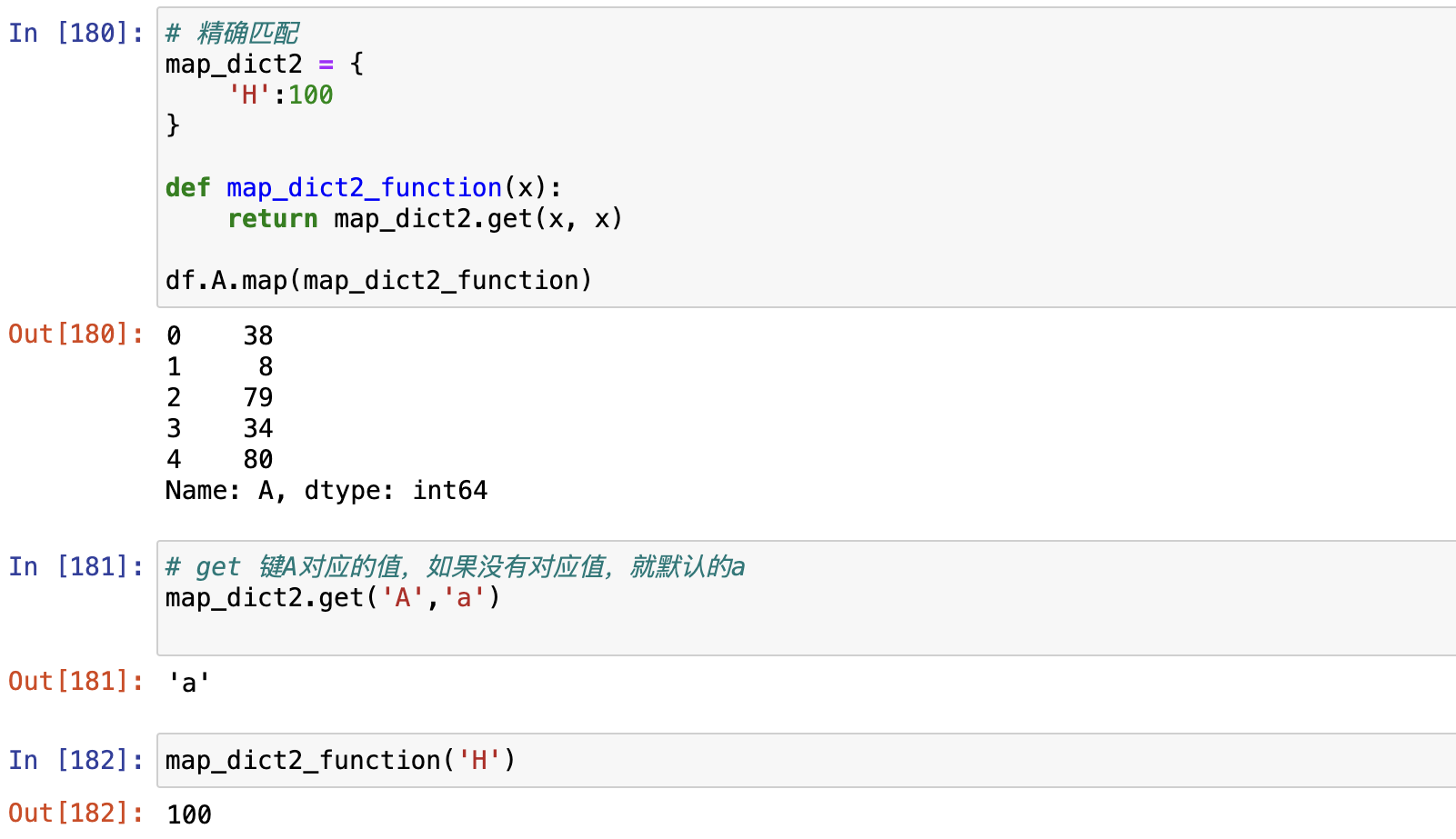
# 字典里有H就匹配H,
# 没有H就通过get()匹配默认值aPandas级联
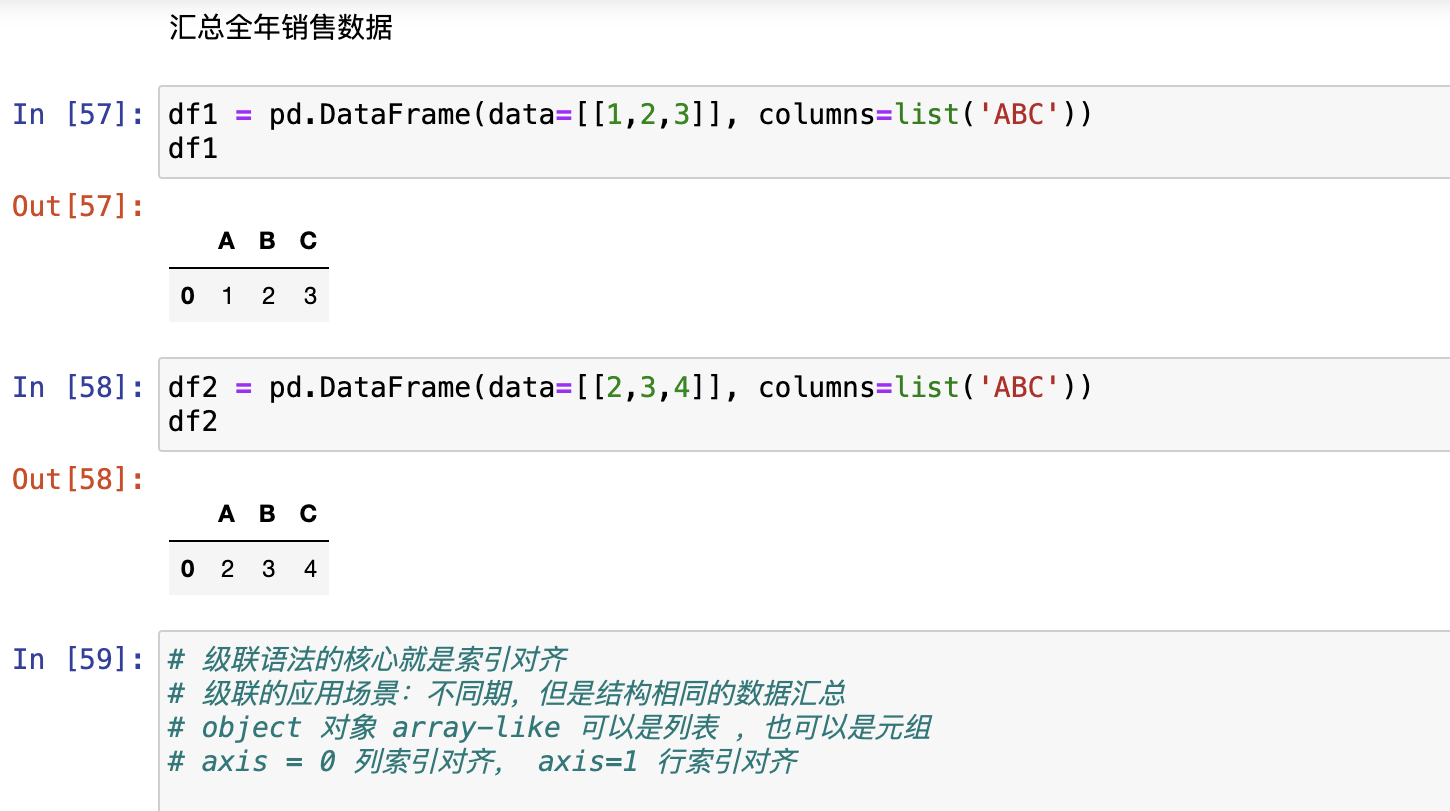
级联
核心是索引对齐原则
要求数据结构一致
校验级联后是否有重复索引用参数
veriy_integrity = True,使用后如果有重复索引会报错解决重复索引2种方式:
- 使用多层索引解决,使用参数keys
- 忽略索引的方式解决,使用
ignore_index = True参数
join = inner,join = outer两个参数决定级联后取交集还是并集- 不建议使用
join = inner,容易丢失数据
- 不建议使用
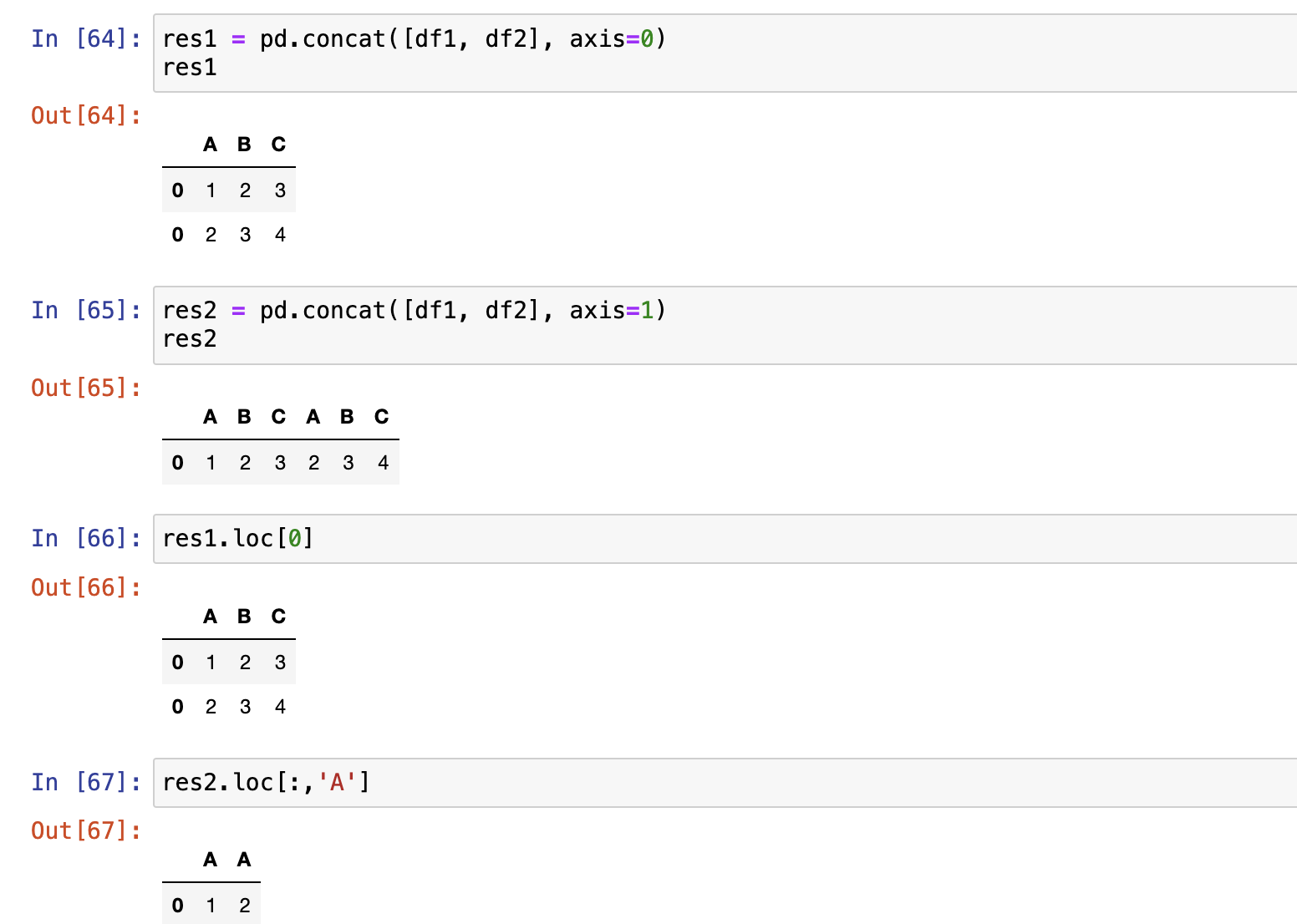
- 校验级联后是否有重复索引用参数
veriy_integrity = True,使用后如果有重复索引会报错
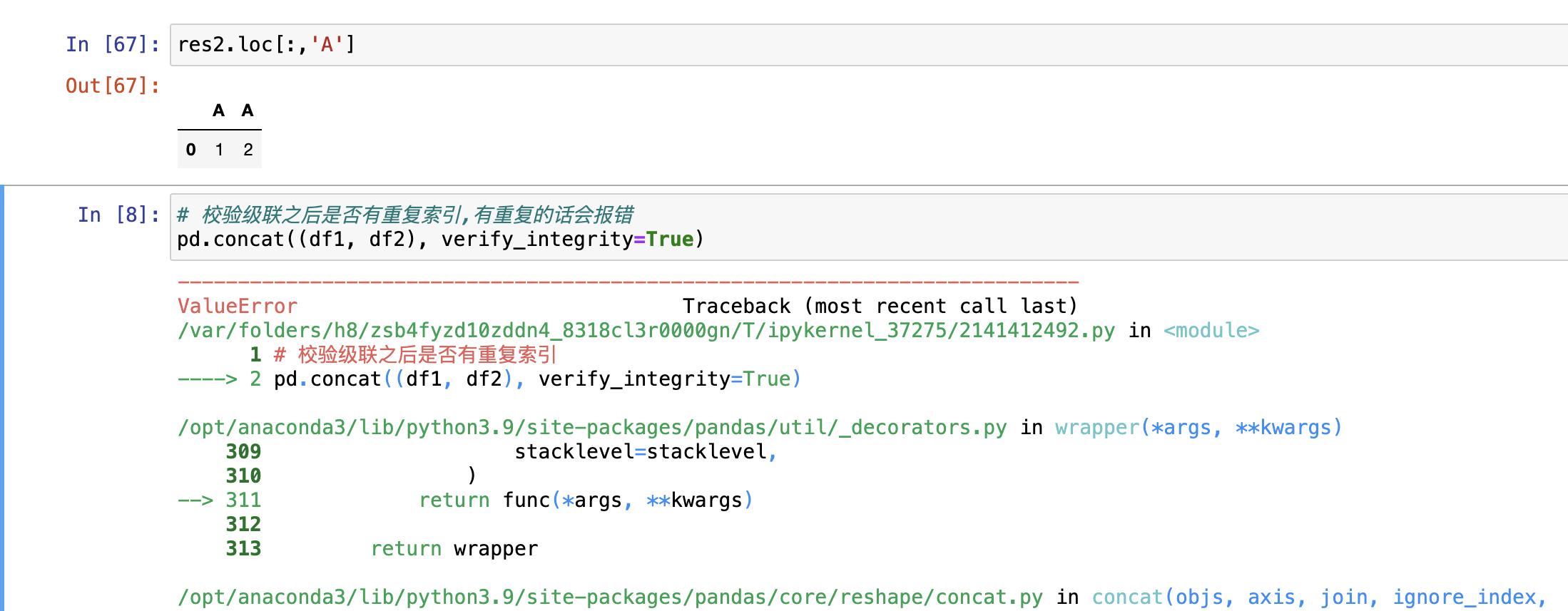
# 报错信息如下
# ValueError: Indexes have overlapping values: Int64Index([0], dtype='int64')- 解决重复索引2种方式:
- 使用多层索引解决,使用参数keys
- 忽略索引的方式解决,使用
ignore_index = True参数
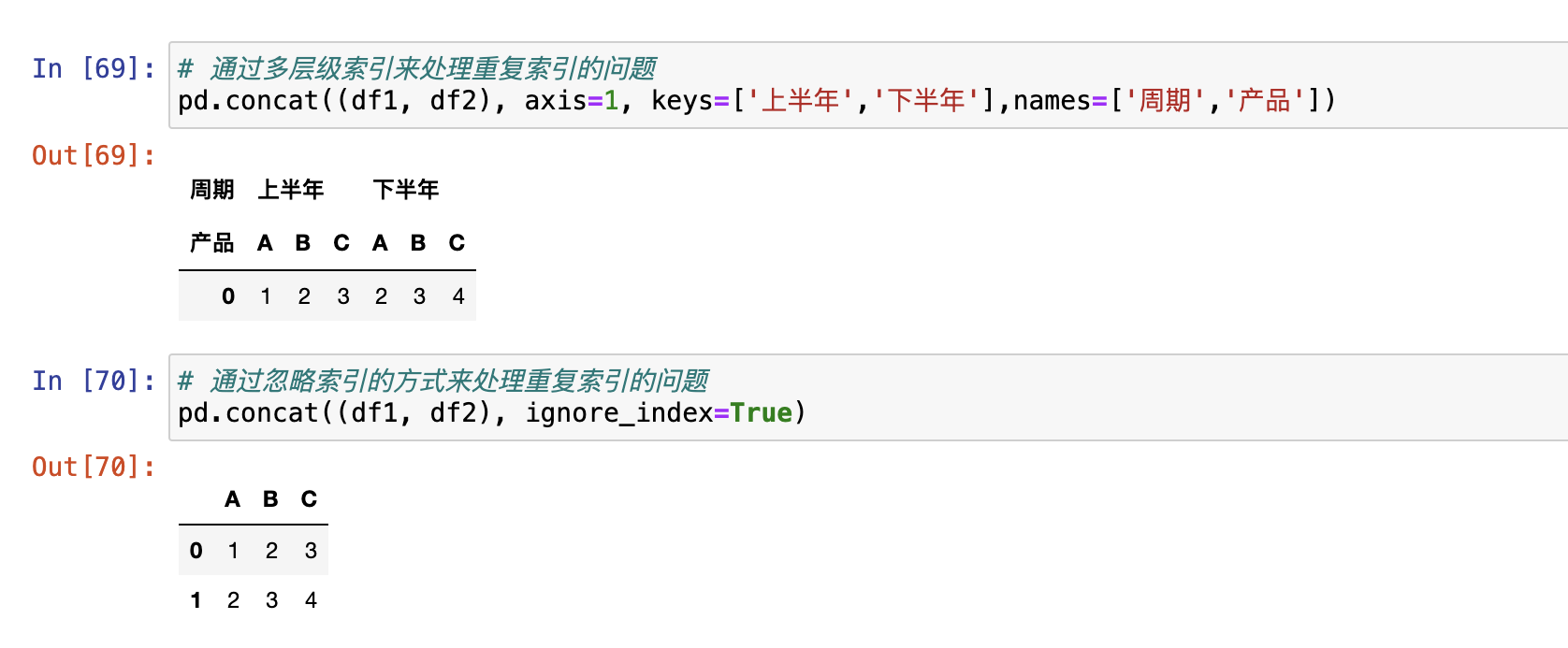
- 核心是索引对齐原则
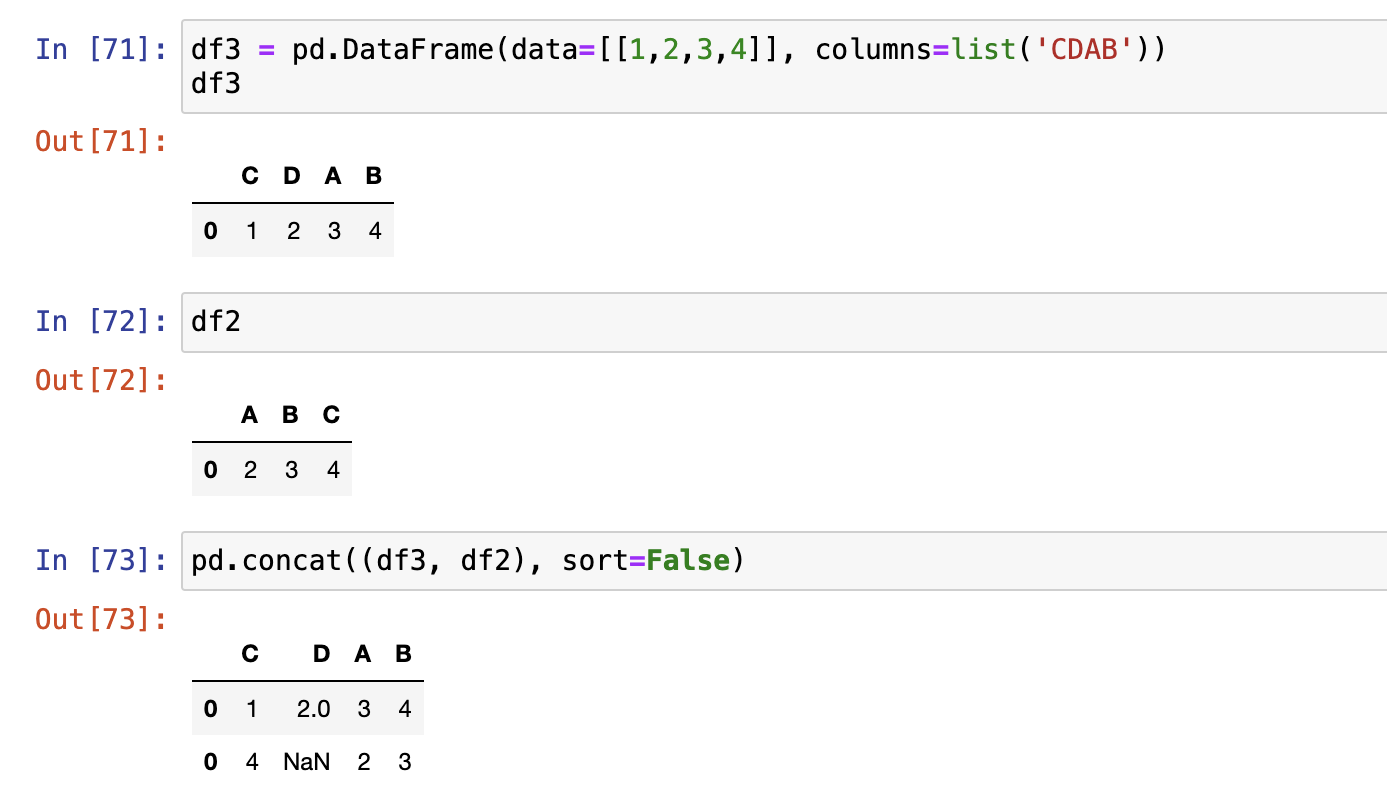
join = inner,join = outer两个参数决定级联后取交集还是并集- 不建议使用
join = inner,容易丢失数据
- 不建议使用
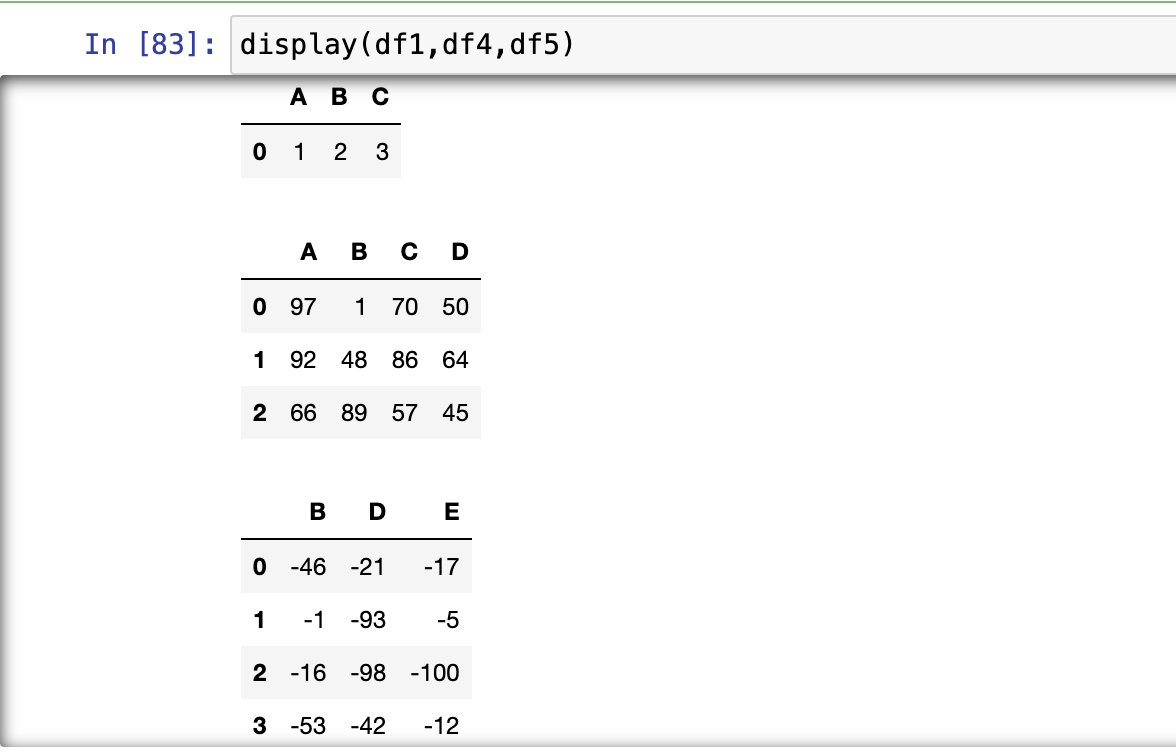
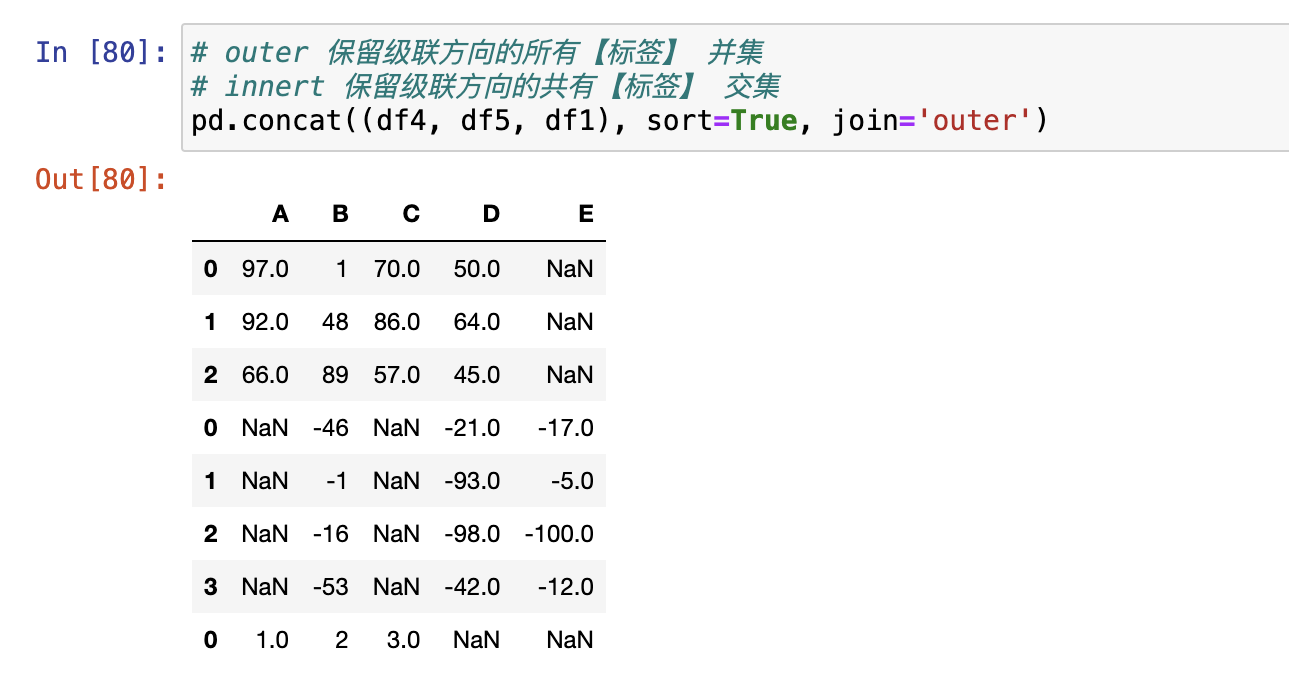
合并
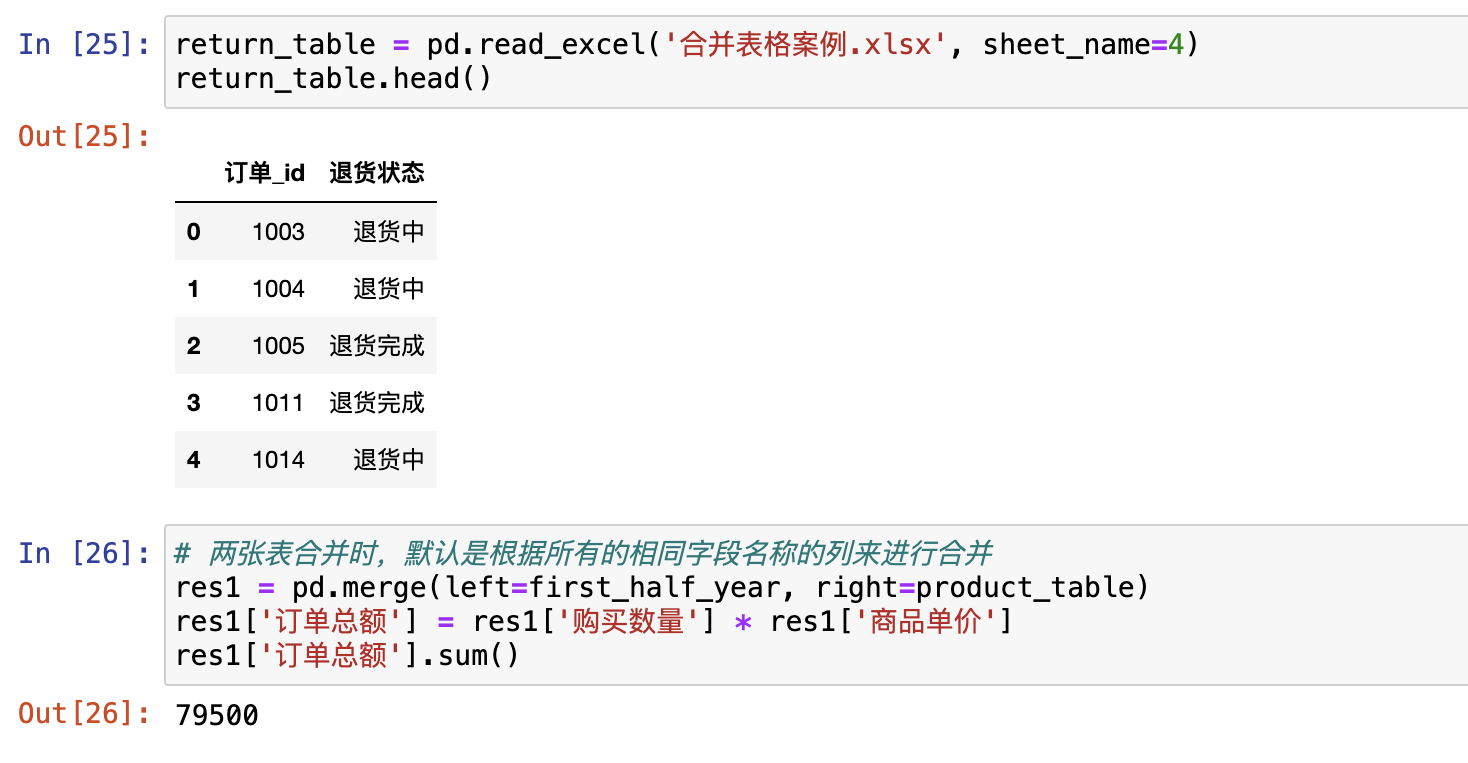
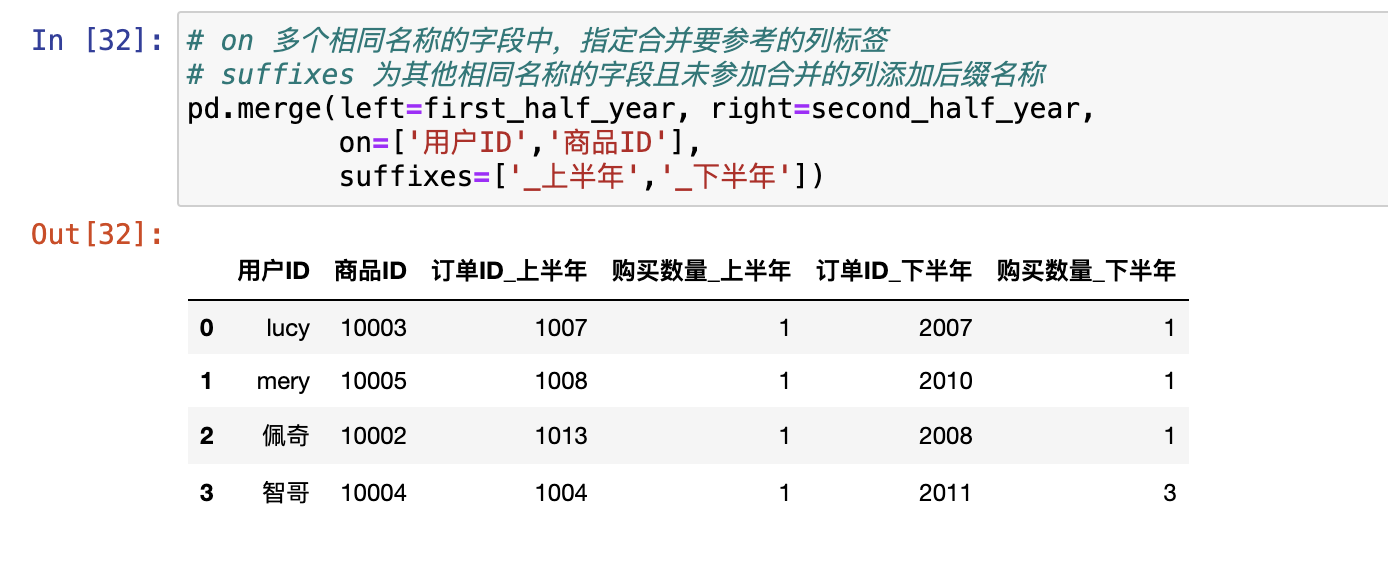
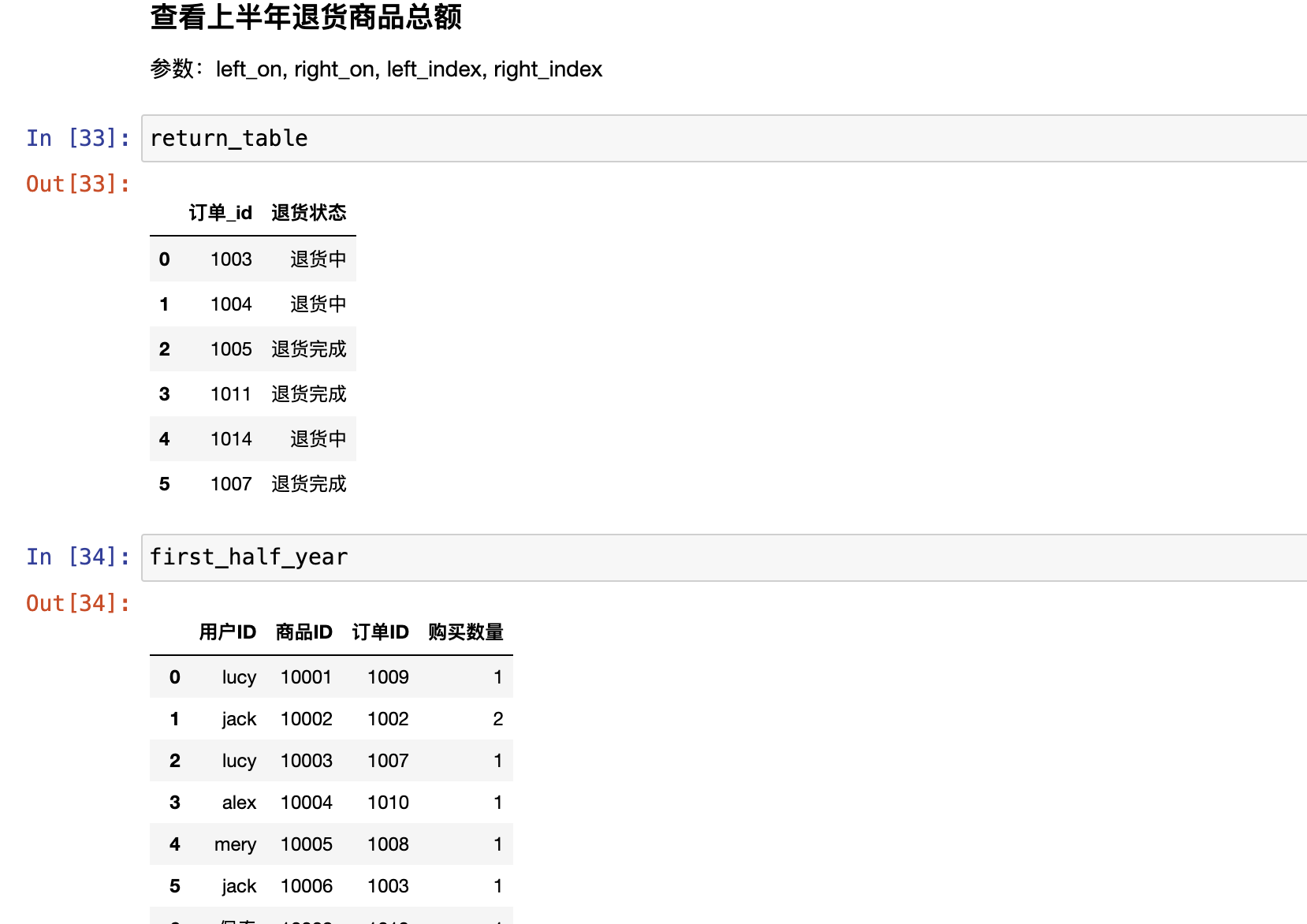
pd.merge()
合并就是根据两张表的公共信息,把两张表的数据汇总的方法。
合并以列的内容为参考标准,不存在行合并,都是列合并
合并的列通常是离散型数据。可以是数值型
合并的列之间存在一对一、一对多、多对多关系,否则合并结果为空
参数:
left/right:左右表名字
Left_on/right_on:按左右表的那一列合并
how:inner/outer,合并后取交集还是并集
on:按那一列合并
suffixes:合并后给列索引加名字后缀,用来区分两张表
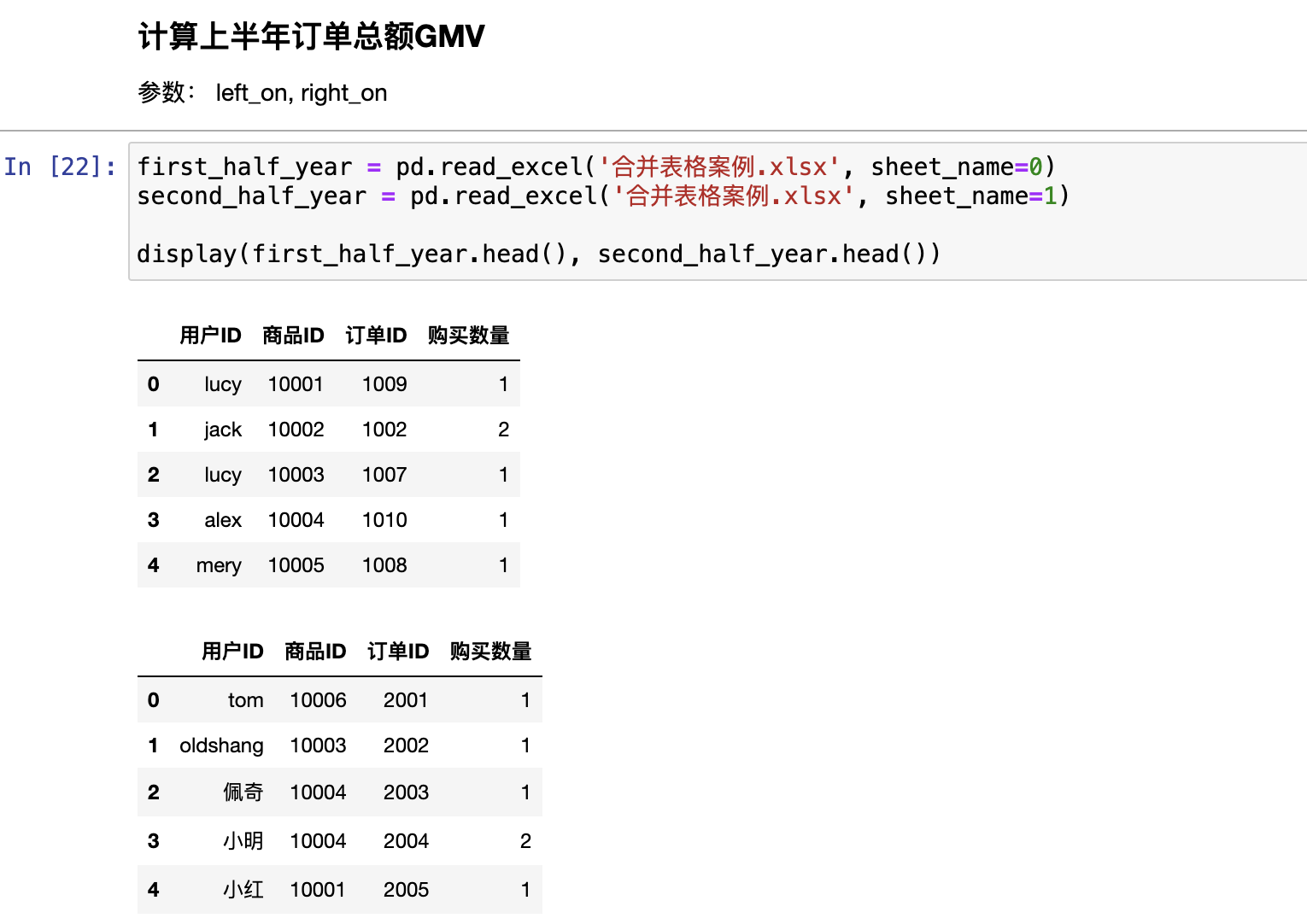

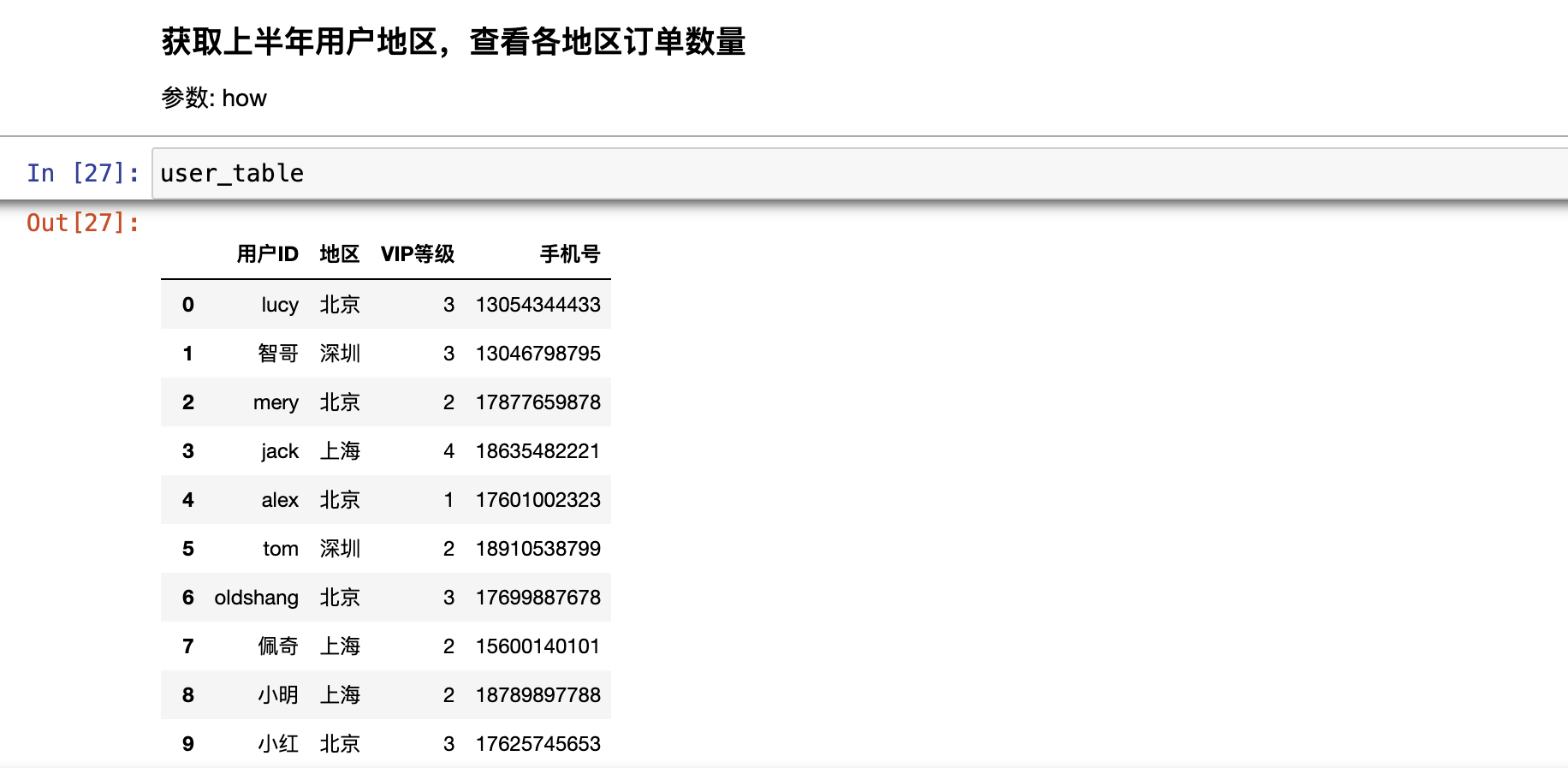
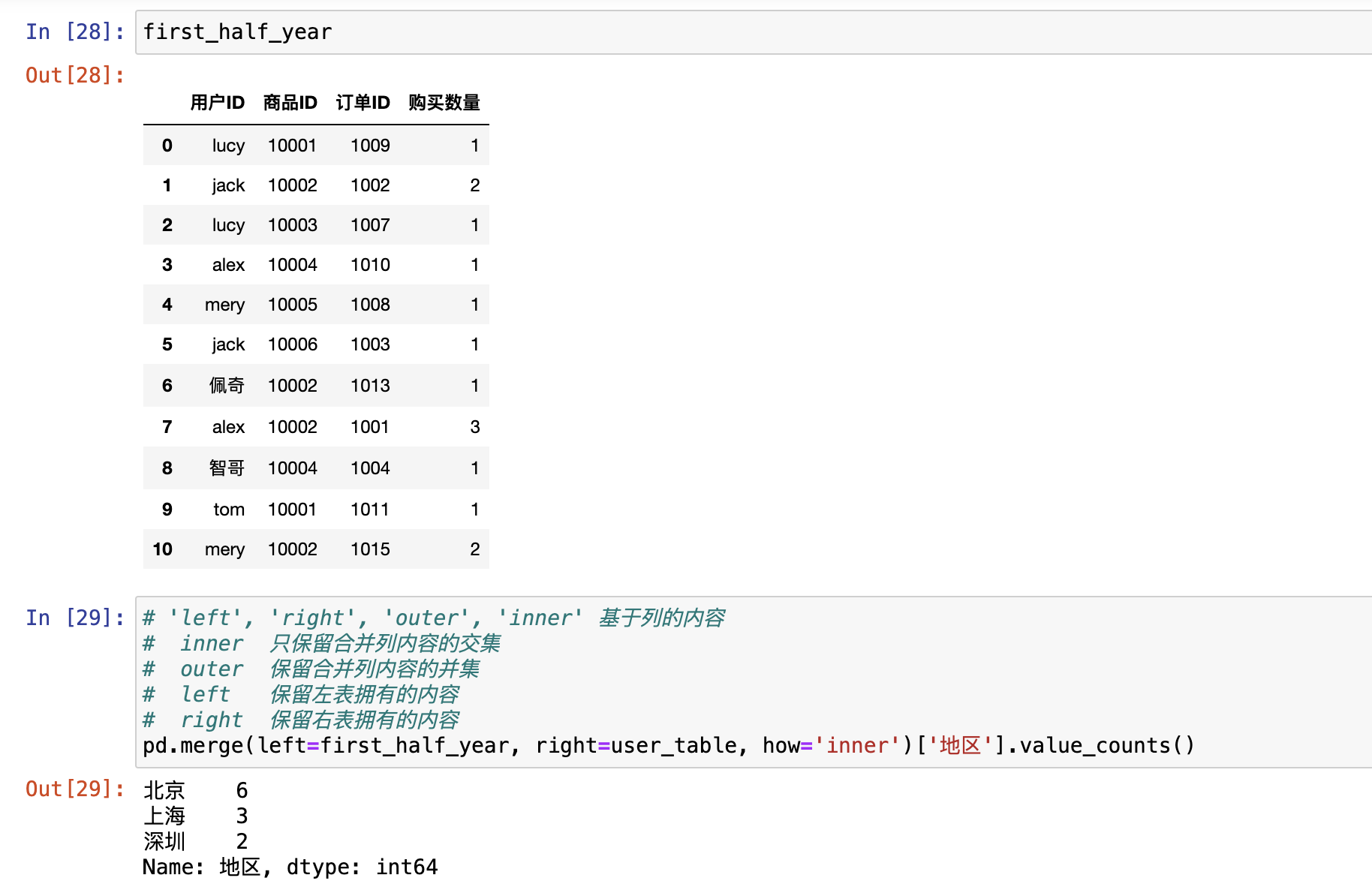
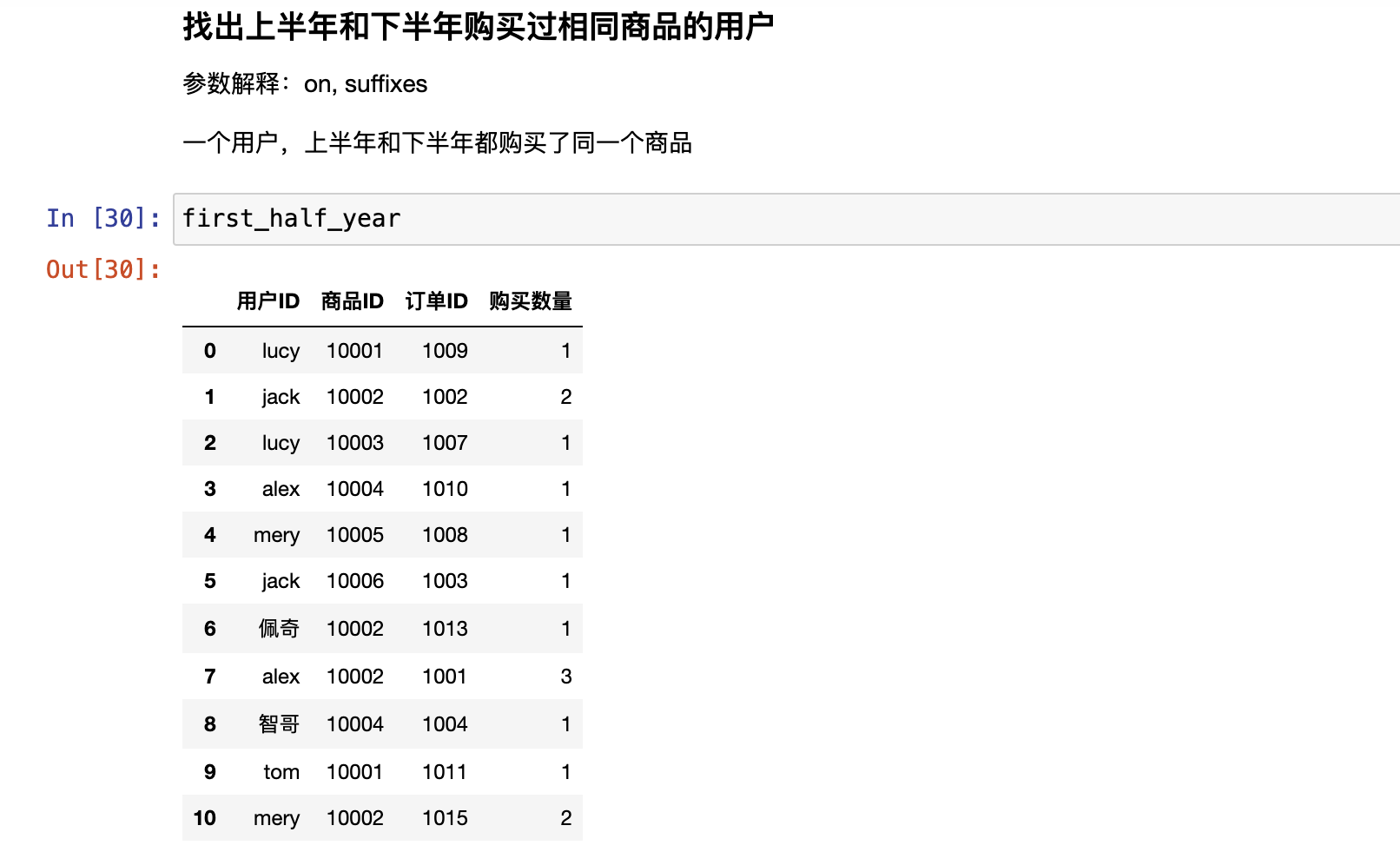
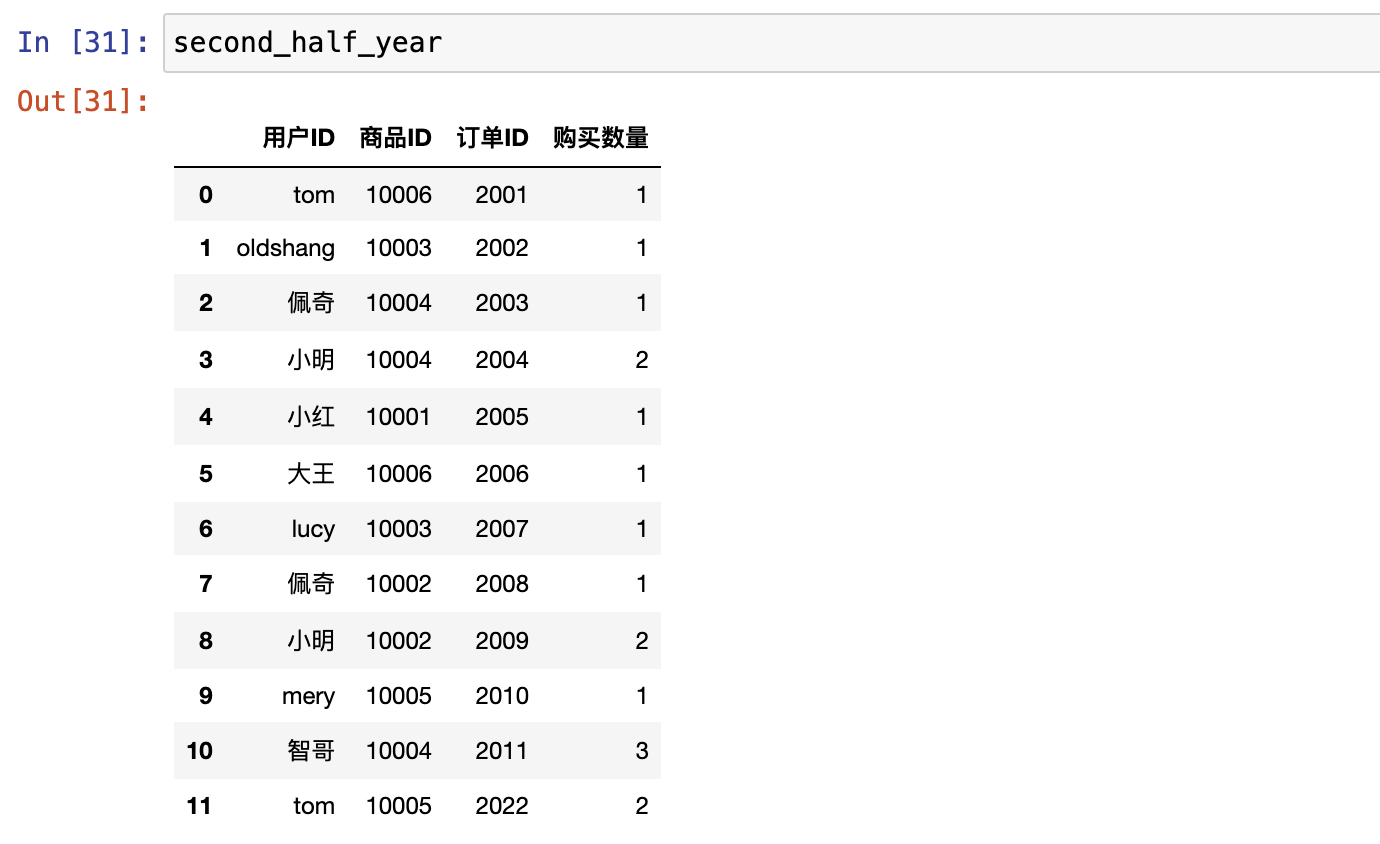

分组
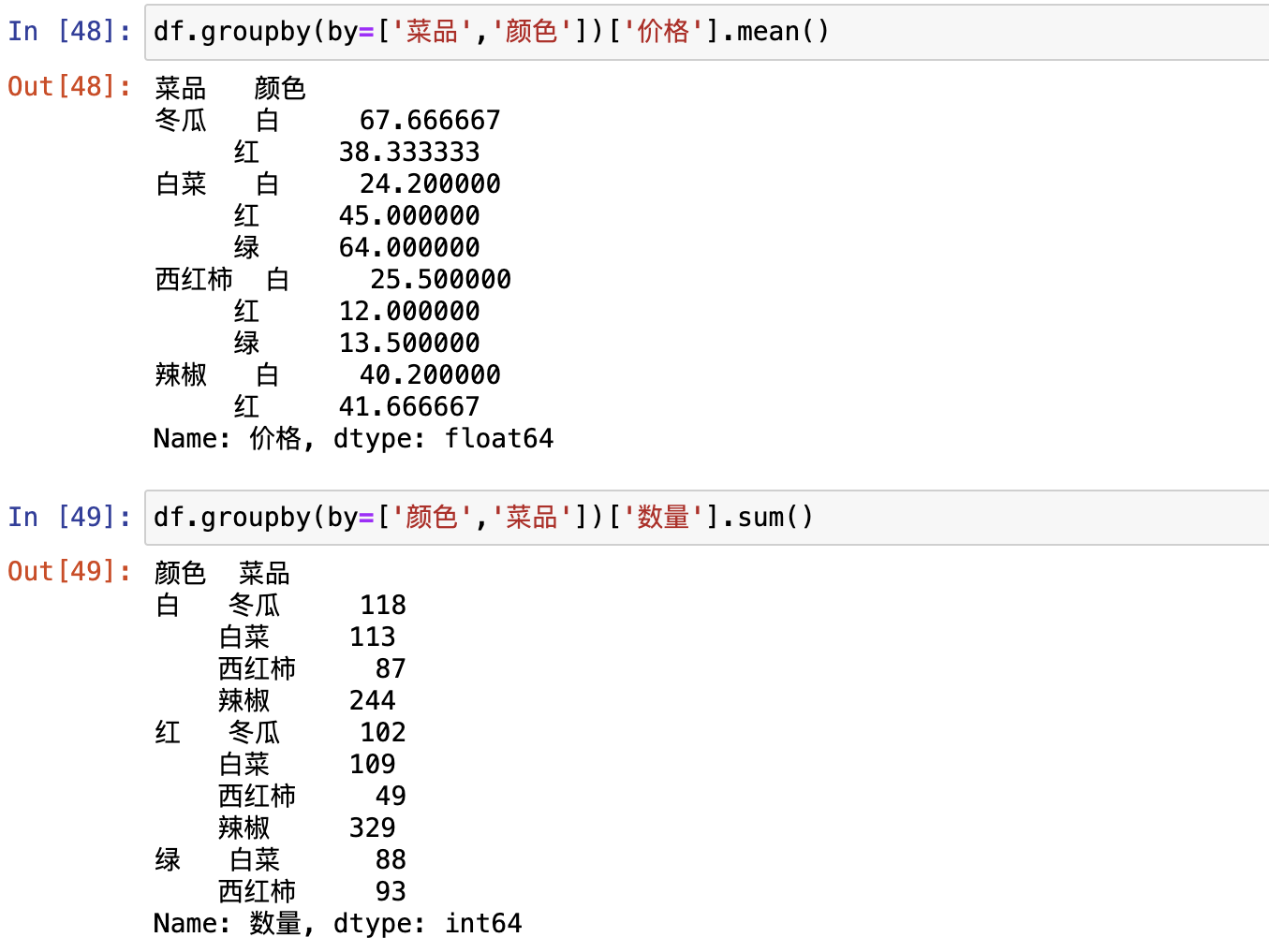
groupby()- 单分组
- 多分组
df.groupby(by=['分组字段']).groups,查看具体的分组情况分组必聚合
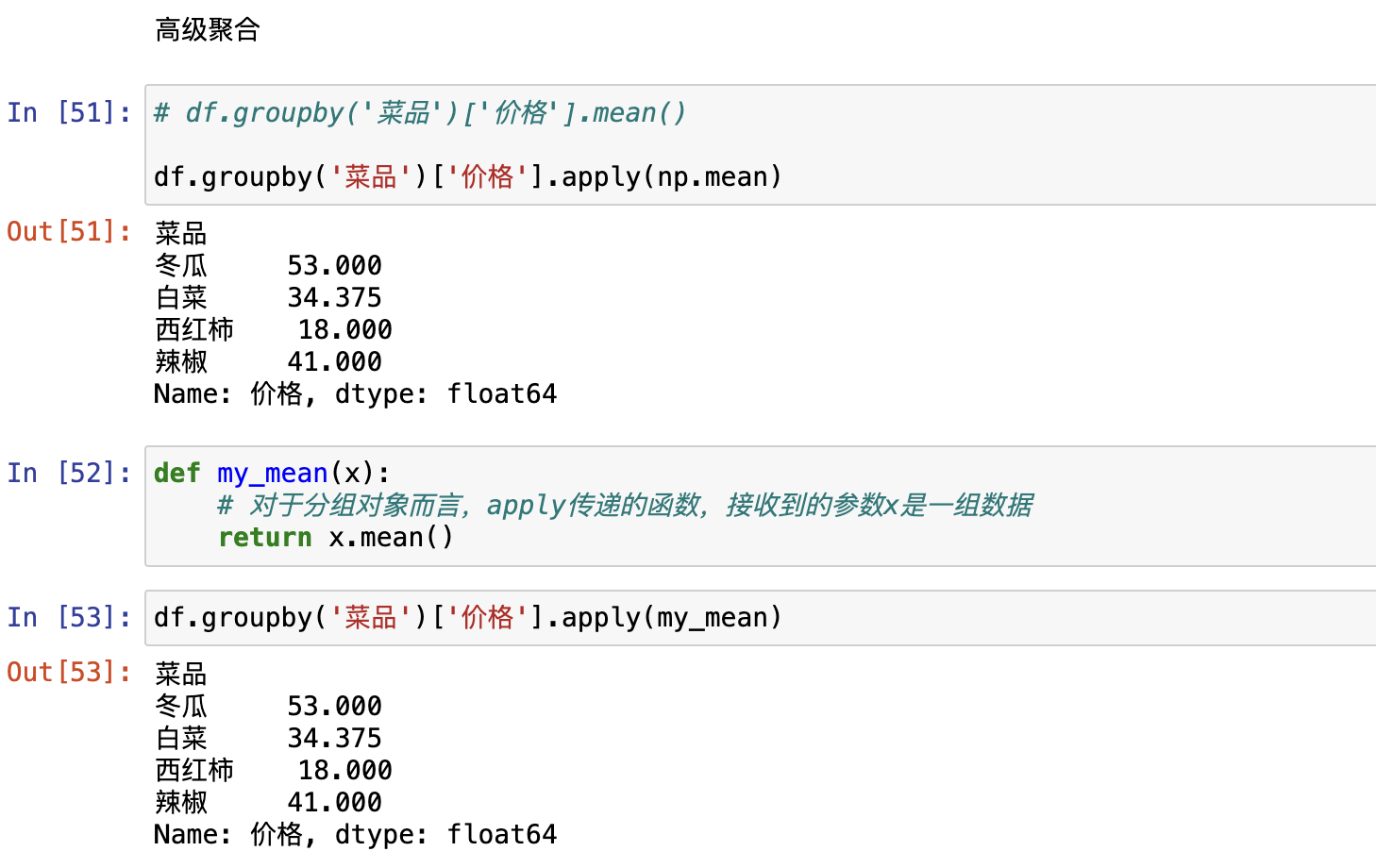
df.groupby(by=['分组字段']).agg(),定制多种聚合指标apply(),自定义聚合方式

groupby()
单分组
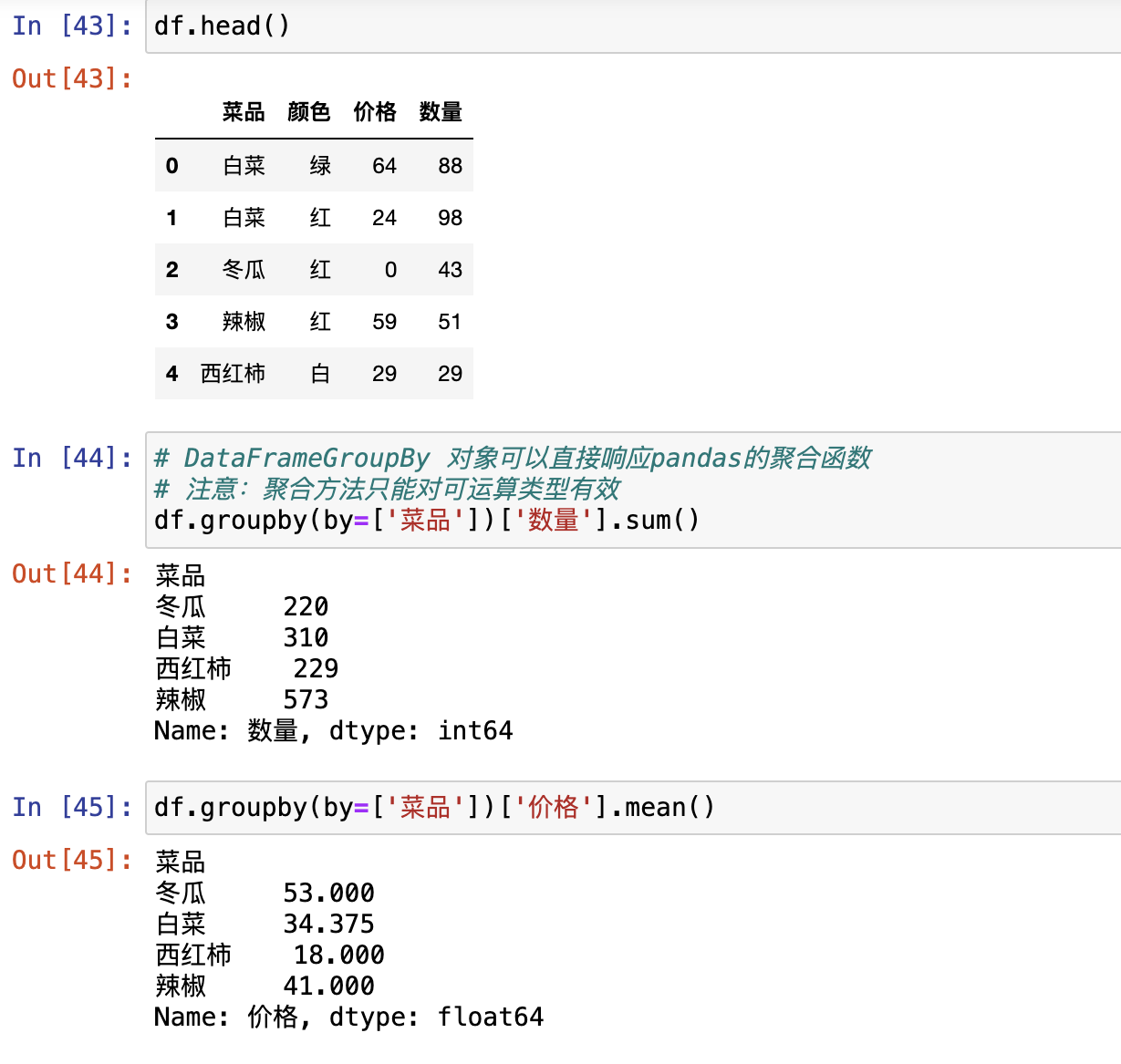
多分组
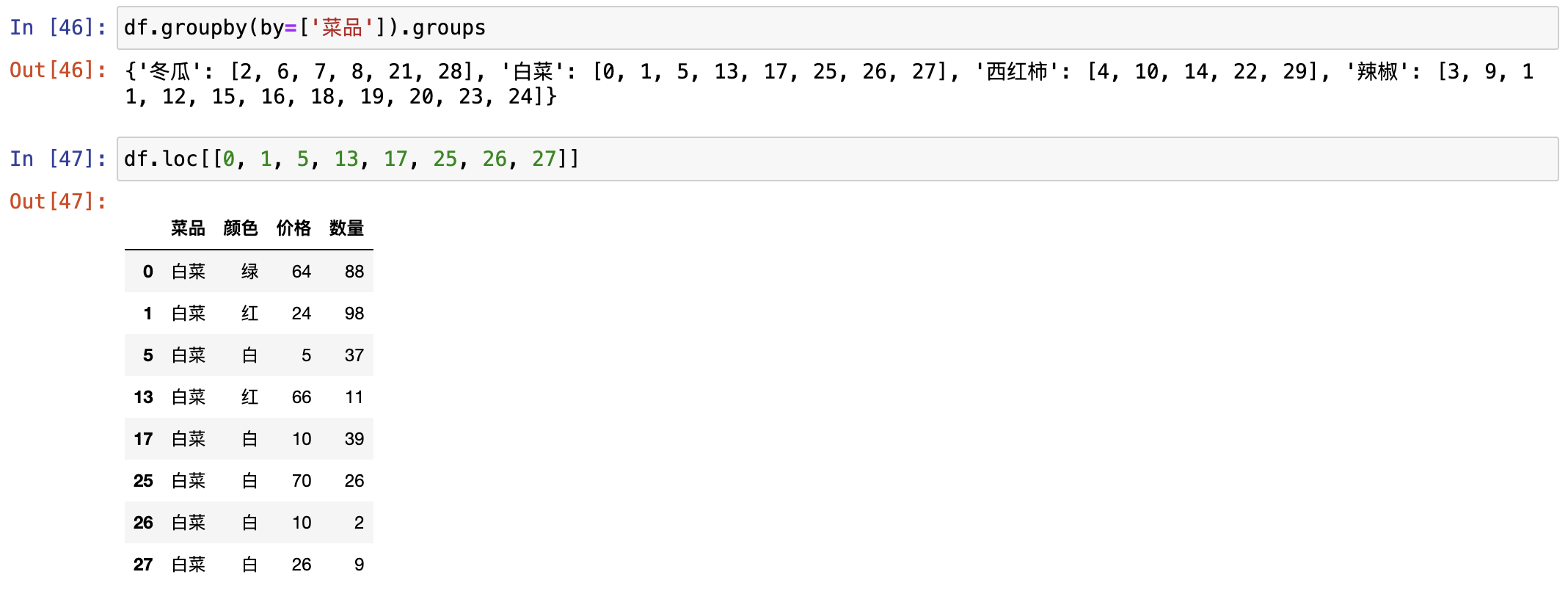
groups
可以用于查看DataFrameGroupBy所表达的分组情况
agg(),定制多种聚合指标

apply(),自定义聚合方式
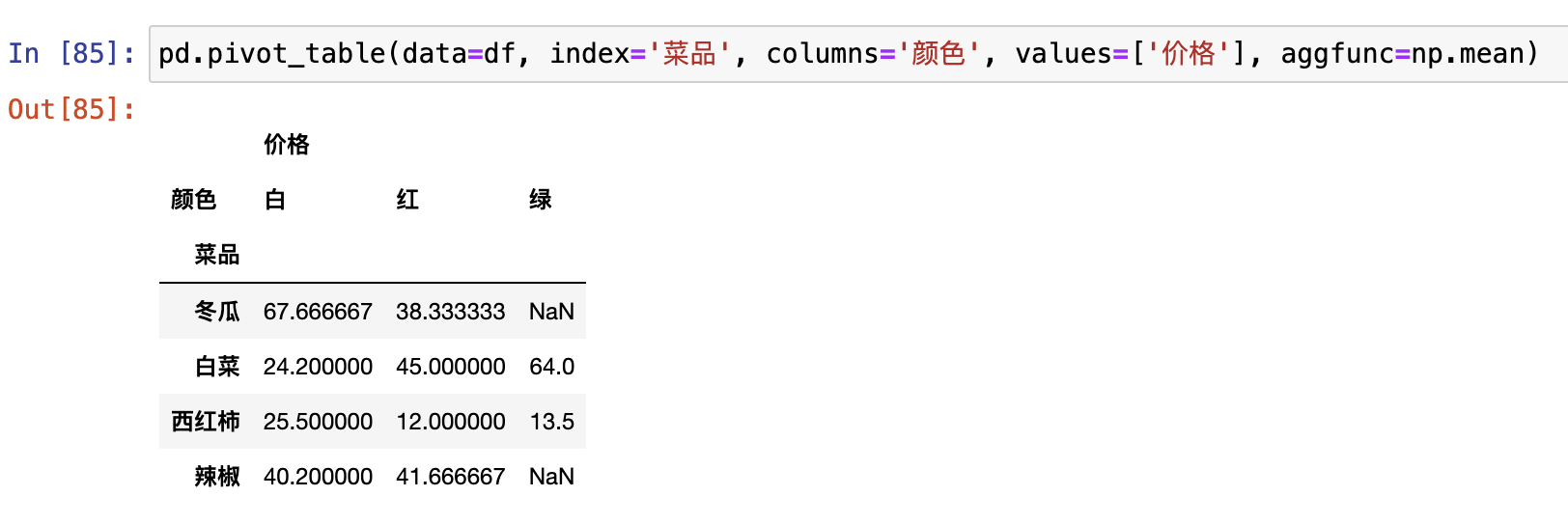
交叉表和透视表
交叉表
- 交叉表只统计数量count

透视表
交叉表想统计什么都可以。
data 数据源 就是要进行透视的DataFrame对象
index\columns 透视表的行列是从数据源的哪列提取的
values 是要统计的数据源中的字段
aggfunc 是聚合方法,传递的是函数名字