Numpy是线性代数库
为什么使用jupyter notebook
- 数据处理 (python 处理数据功能) coding
- 文字型的描述 富文本 word
- 可视化支持
逻辑性 业务逻辑
django flask application game 复杂编译器 scrapy
pycharm
jupyter notebook
需求 user interface UI界面都没有的一个轻量级的文本集编译器 借用我们pc里面自带的浏览器外壳 当前默认的浏览器外壳 chrome 逼格更高
启动
cmd执行以下命令:
jupyter notebook
[NotebookApp] Serving notebooks from local directory: /home/nanfengpo
[NotebookApp] 0 active kernels
[NotebookApp] The IPython Notebook is running at: http://localhost:8888/
[NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
注意以下几点:
打开地址为当前bash的目录,默认的根目录
浏览器地址为http://localhost:8888/
通过control -C终止jupyter程序单元格状态
- 状态:
- 选中状态 单元格左侧变成蓝色 此时可以对单元格本身进行操作
- 编辑状态 单元格左侧变成绿色 有光标在单元格内部闪动 对单元格内部文本进行操作
- 切换:
- 选中 --> 编辑 1.回车 2.鼠标点击单元格内部
- 编辑 --> 选中 1.ESC 2.鼠标点击单元格左侧外部
cell 是最基本的一个代码块单元
- Code 代码模式 写python代码
- Markdown 文本模式 支持Markdown语法
切换模式:
- 选中状态下才能切换模式: y切换到Code ,m切换到Markdown
- 鼠标在上方的下拉列表内手动选择
选中任意一个单元格,按中b,新增一个单元格,在单元格任意输入一段代码,Ctrl+Enter
单元格操作
前提: 单元格处于选中状态
1. 新增cell
a在选中单元格的上方插入一个新cell
b在选中单元格下方插入一个新cell
2. 删除cell
dd删除选中cell x剪切cell
3. 复制cell
c复制选中cell
4. 粘贴
v粘贴已复制的cell到选中cell的正下方
5. 撤销单元格操作
z撤销
6.剪切
按x剪切单元格单元格间资源共享,但独立运行
运行
- Markdown模式运行是进入预览状态
- Code模式运行是运行代码
- Raw NBConvert 是默认文本状态
运行的方式
- Ctrl + Enter 运行选中单元格,然后继续选中当前单元格
- Shift + Enter 运行选中单元格,并且在其下方选中(新增)一个单元格
- Alt + Enter 运行选中单元格, 并且在其下方新增一个单元格
帮助文档
- help(要查询的对象)
- 要查询的对象?
- Shift+tab
魔法指令
- %run
- %time 和 %%time
- %timeit 和 %%timeit
- %who 和 %whos
%run
运行py脚本的命令
%run hello.py #运行后会在jupyter book中加载脚本的变量,函数等,后续可以继续使用。可以将常用的功能封装成一个脚本,成为自己的工具库。
%time 和 %%time
- %time 记录一行的运行时间
- %%time 记录多行的运行时间
def func(num):
sum = 0
for i in range(num):
sum += i
return sum
%time func(100000)%%time
func(100000)
func(100000)
# 注意%%time需要在单独的单元格中使用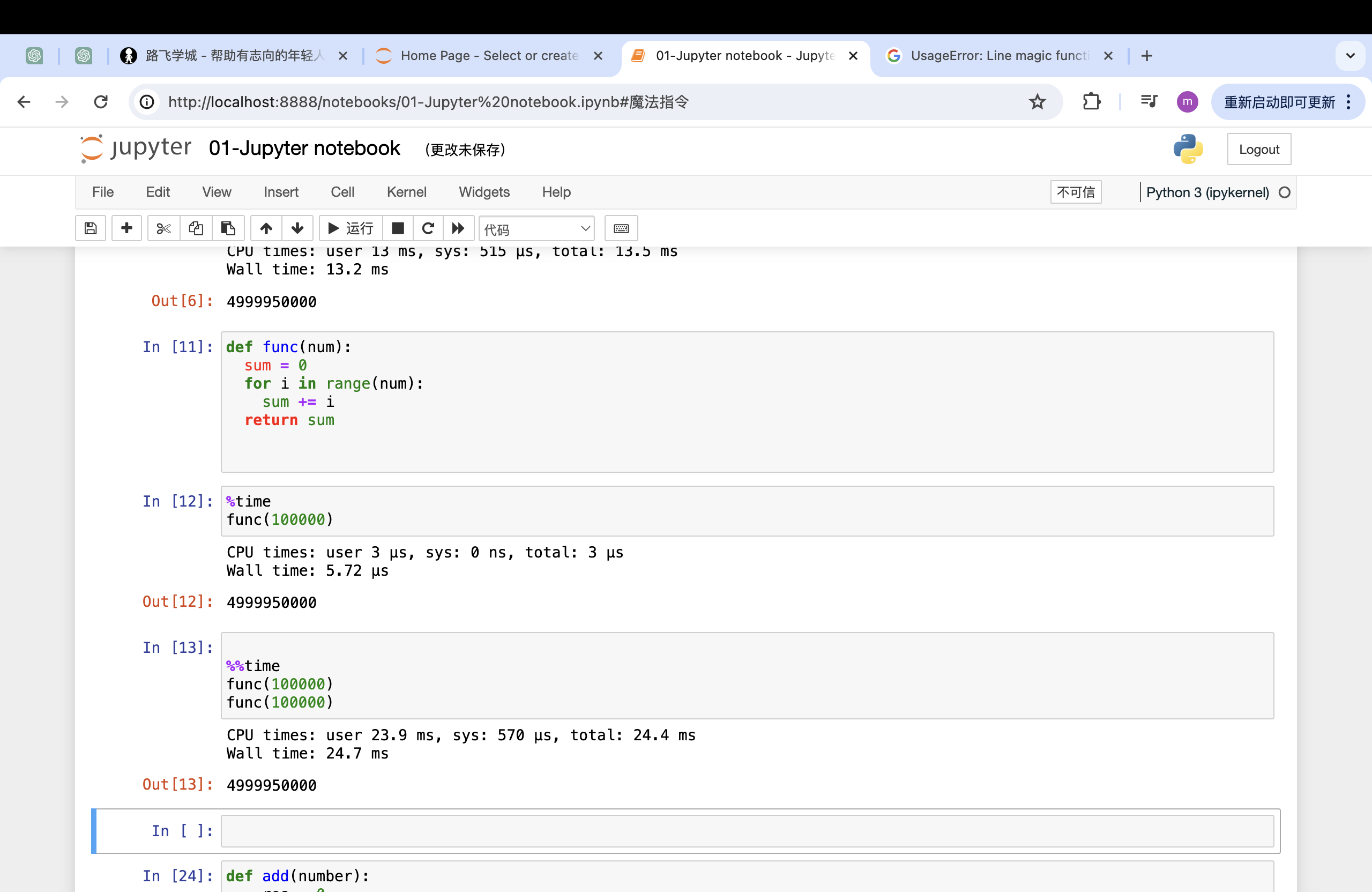
%timeit 和 %%timeit
%timeit和%%timeit 多次运行取平均值,用法和上面一样
- %timeit 记录一行的运行时间
- %%timeit 记录多行的运行时间
%who %whos
显示当前会话中定义的所有变量、函数和导入的模块。
%who #简略显示
a add add_function b say_hello url
%whos #详细显示
Variable Type Data/Info
------------------------------------
a int 9
add function <function add at 0x00000214F05EF6A8>
add_function function <function add_function at 0x00000214F0430AE8>
b int 10
say_hello function <function say_hello at 0x00000214F05FEEA0>
url str https://www.luffycity.com/IPython输入输出历史
可使用In/Out调用输入输出历史
Numpy简介
一个基于python的扩展库
提供高维数组对象ndarray,运算速度碾压python List
提供了各种高级数据编程工具,如矩阵运算、向量运算、快速筛选、IO操作、傅里叶变换、线性代数、随机数等
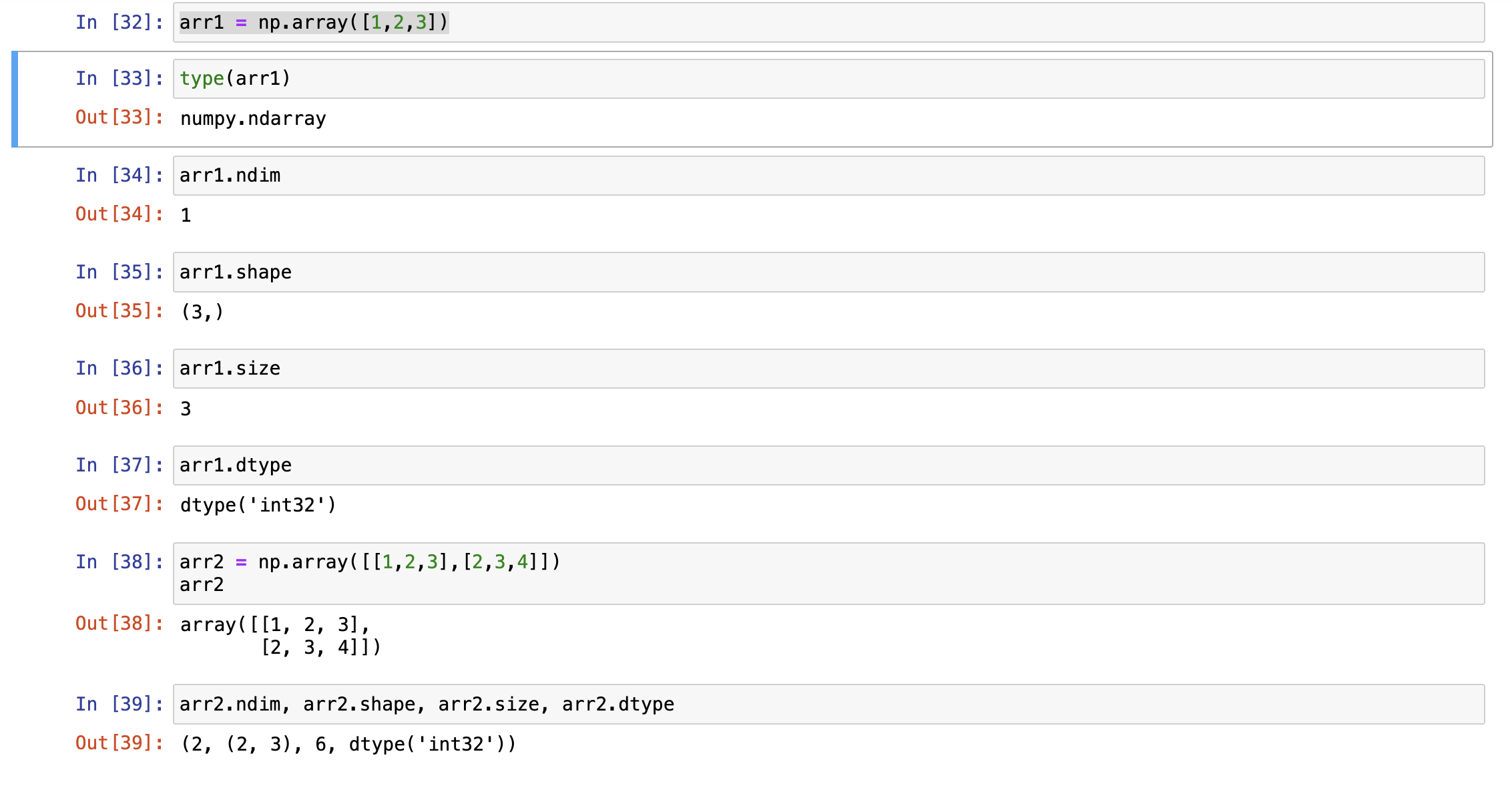
ndarray属性
- ndim:维度
- shape:形状(各维度的长度)
- size:总长度
- dtype:元素类型
创建ndarray
使用np.array()创建ndarray
np.array()里传入列表
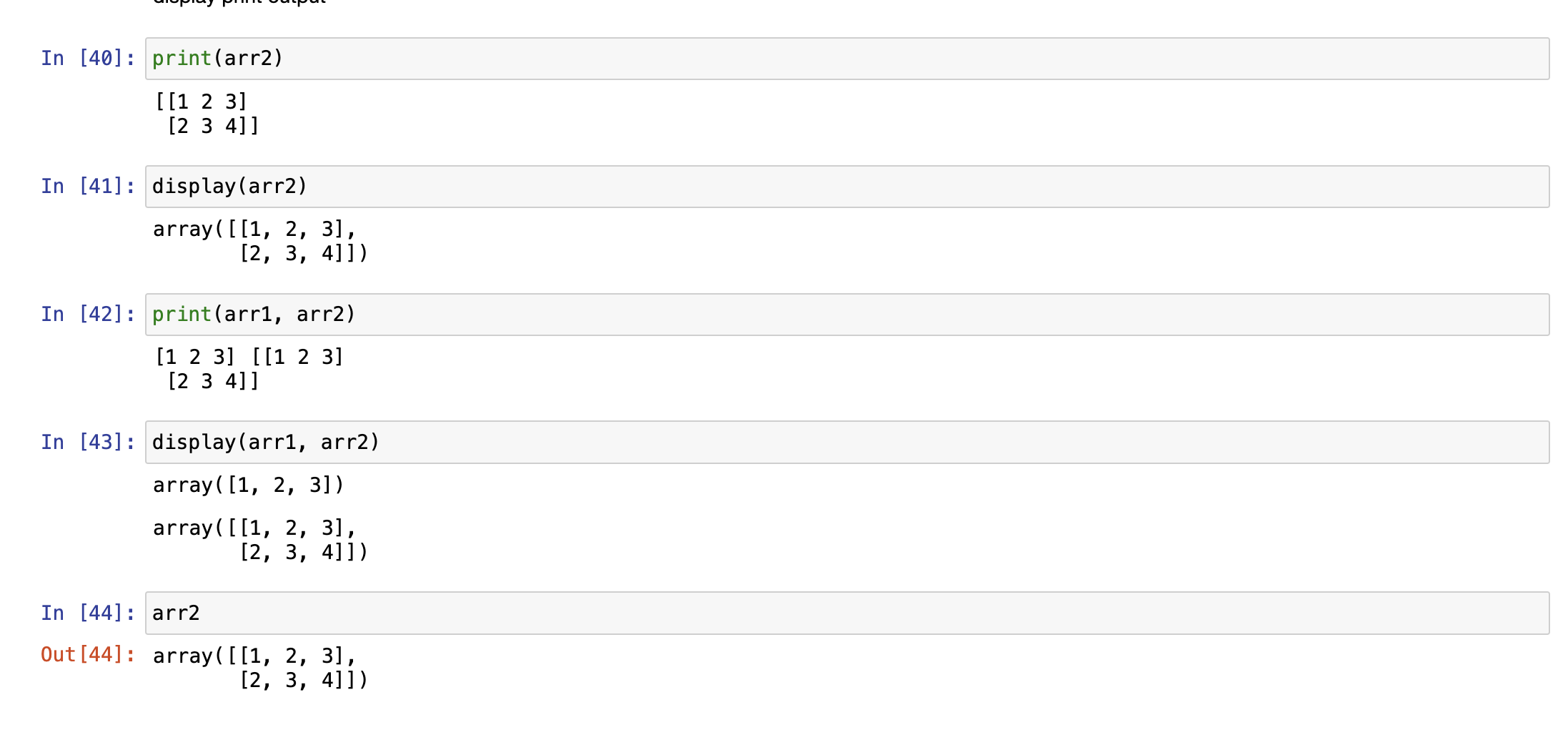
打印数组,3种方式
- output
- display(),推荐这个,好看不乱
- print()
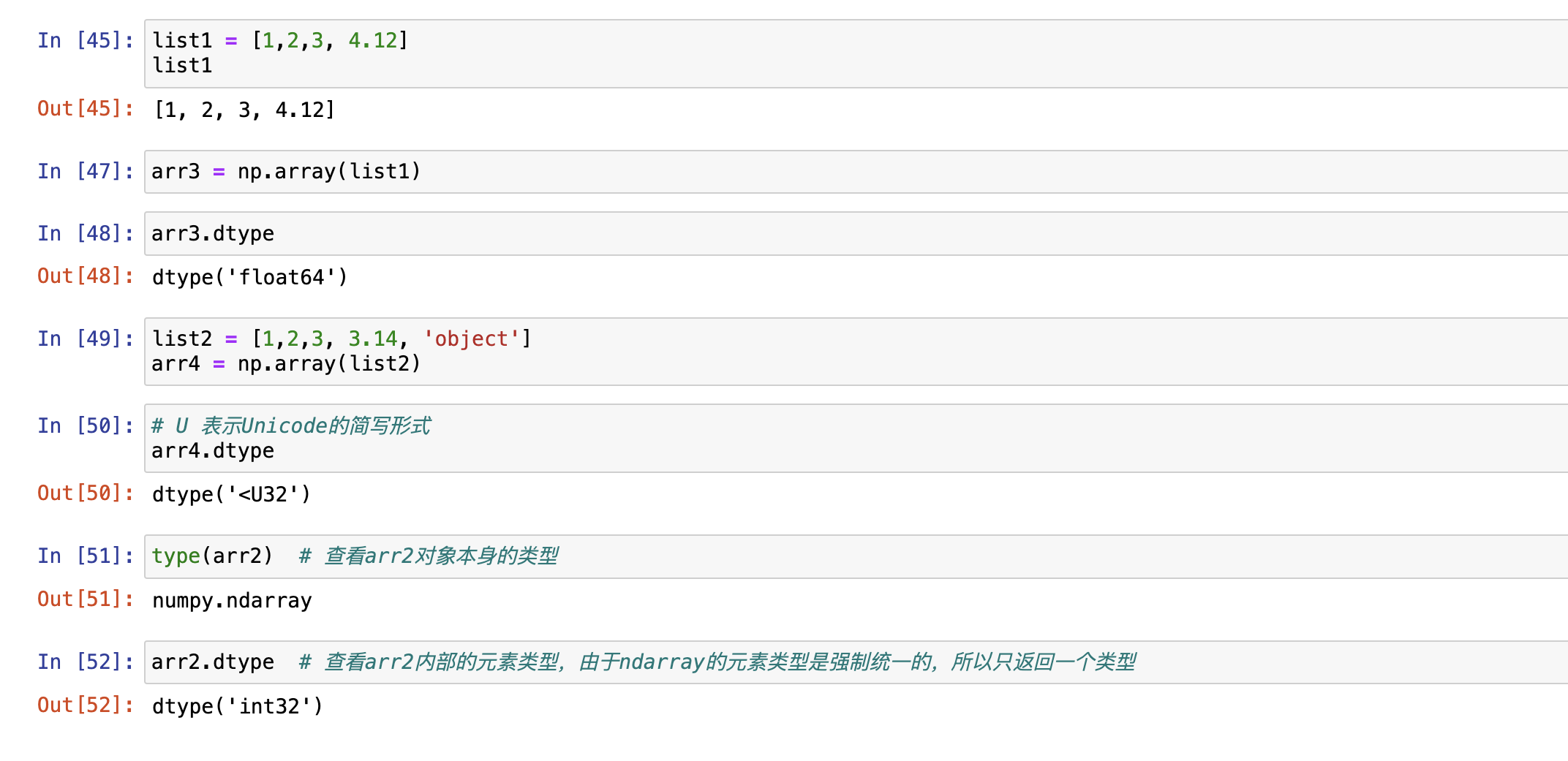
强制类型统一
- numpy设计初衷是用于运算的,所以对数据类型进行统一优化。
ndarray和list的区别!!!
- 数组和列表的最主要区别就是运算速度。
- 数组统一精度,每个数据的内存大小一致,并且数组的存储是内存中的一个连续块,所以节省存储,提高速度。
- 列表本质存储的是指针,而非数据,导致保存list很麻烦,比如lis=[1,2,3,4]就需要存储四个指针和四个数据,增加了存储和cpu。
- 具体看这里https://blog.csdn.net/weixin_45928096/article/details/122567892
注意:
- numpy默认ndarray的所有元素的类型是相同的
- 如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
Numpy的数据类型
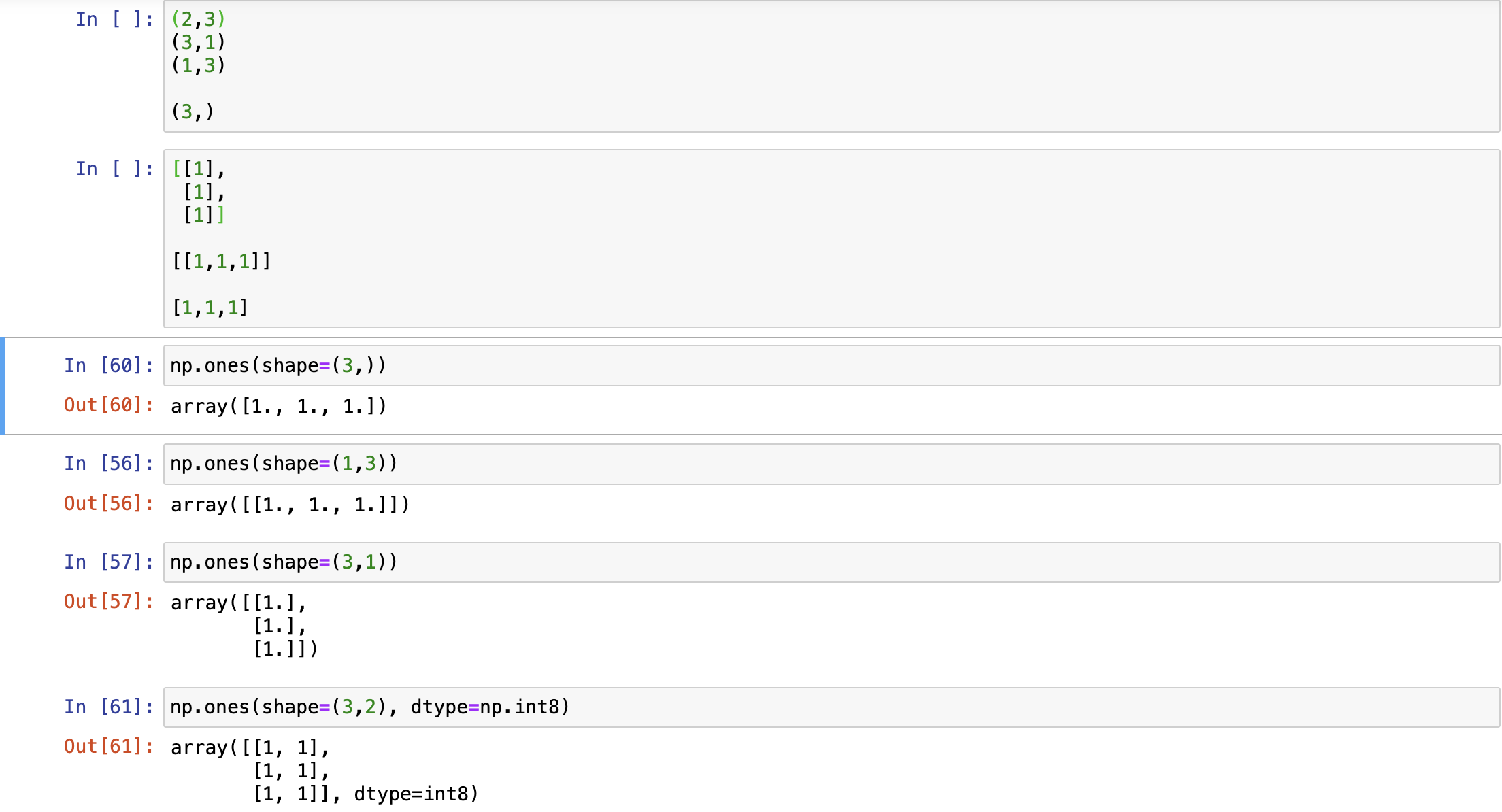
使用np的routines函数创建
- np.ones(shape, dtype=None, order='C')
shape: 形状,使用元组表示
np.zeros(shape, dtype=float, order='C')

np.full(shape, fill_value, dtype=None, order='C')

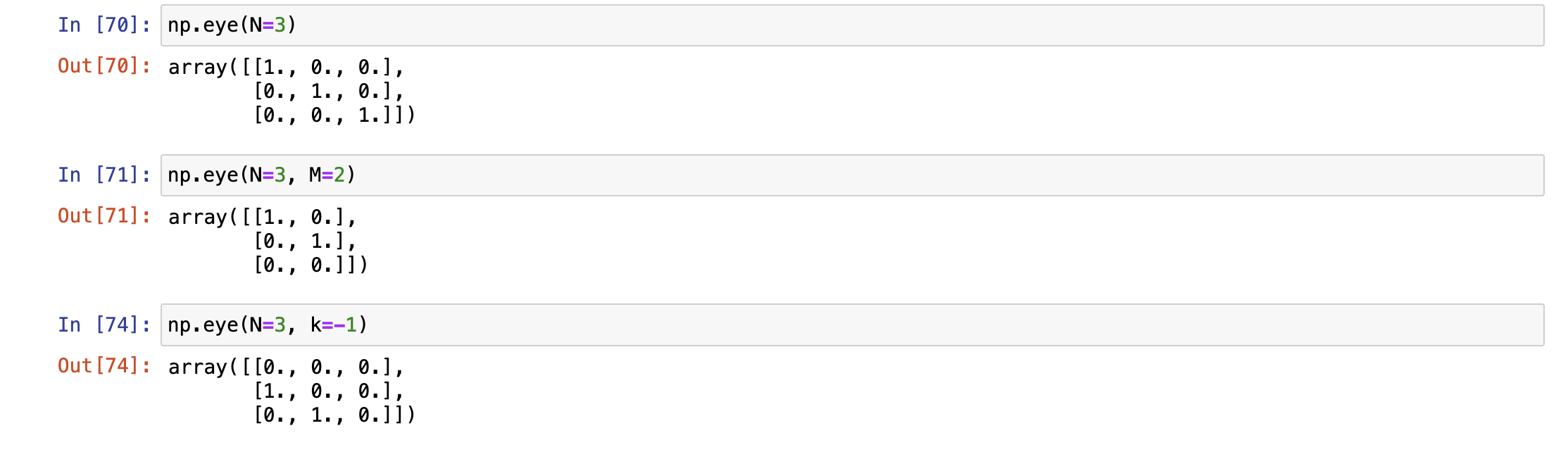
np.eye(N, M=None, k=0, dtype=float)
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)

np.arange([start, ]stop, [step, ]dtype=None)

np.random.randint(low, high=None, size=None, dtype='l')

正态分布函数
- np.random.randn(d0, d1, ..., dn) 标准正态分布,loc=0,scale=1.0,dn表示维度,给个形状就行
- np.random.normal(loc=,scale=,size=) 普通正态分布,loc:平均数,scale:方差
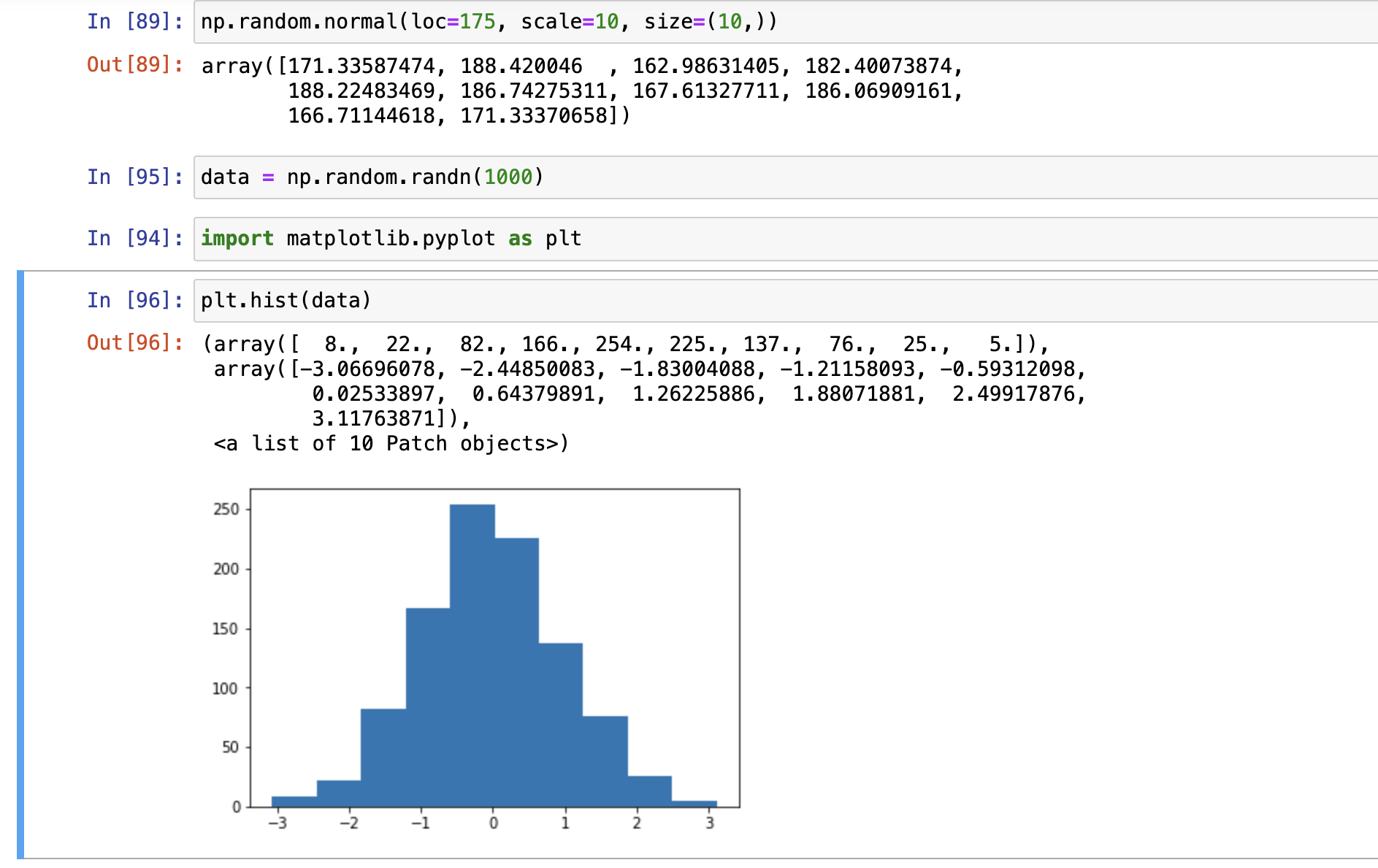
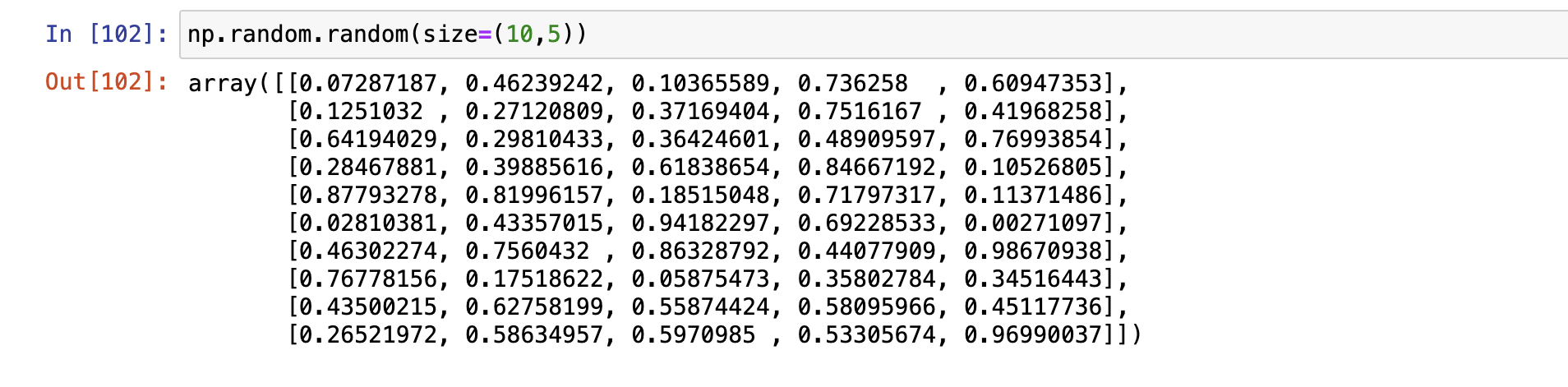
- np.random.random(size=None)
生成0到1的随机数,左闭右开
np.random.permutation(10) 生成随机索引

随机种子

习题
1. 创建一组形状为(3,4)的二维数组,取值范围为(-5,5)
2. 创建一组等差数列,步长为3, 数组长度为5
3. 构造一个3维取值范围为0-1的随机数组,数据类型为np.float64,形状为(100,100,3)
4. 已知Π在numpy中是一个预制的常量,可以使用np.pi访问。计算出将一个圆等分成8份的弧度的代码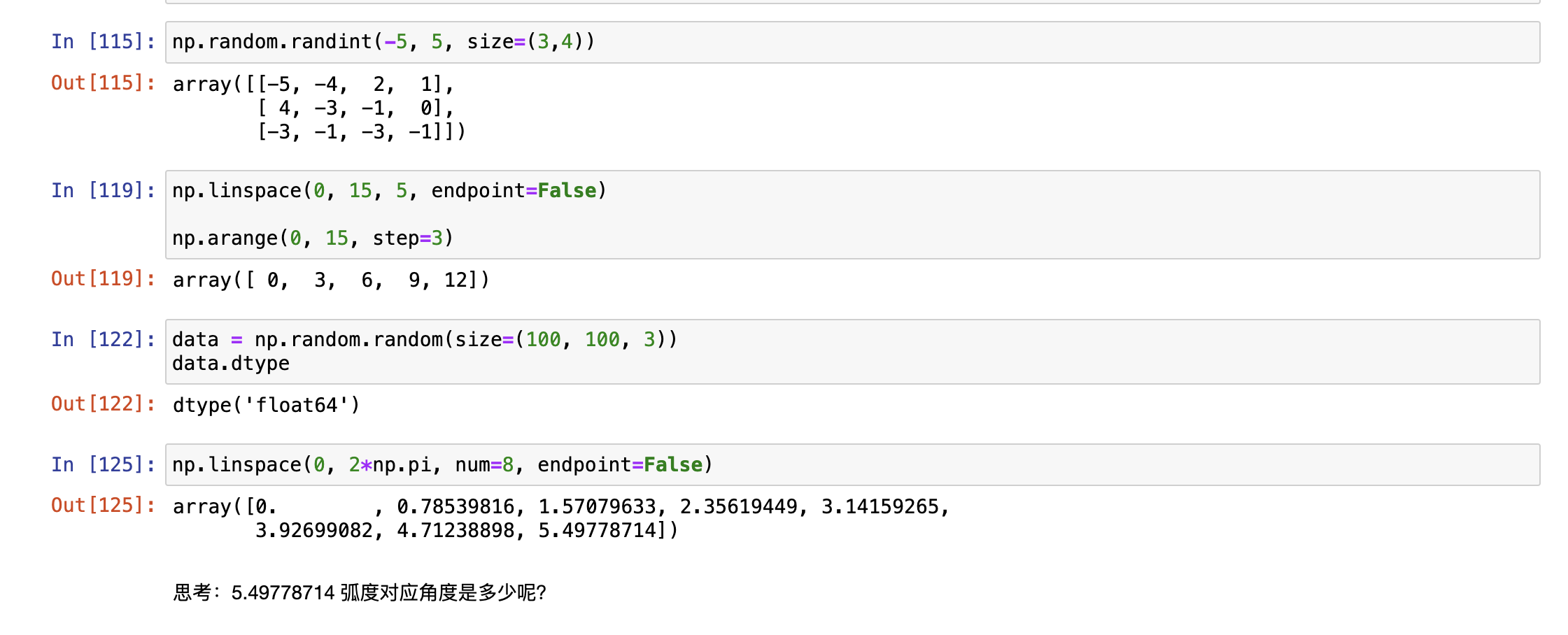
ndarray的读写操作
重点:ndarray支持的访问形式:
- 索引访问:ndarray[dim1_index, dim2_index,...dimn_index]
- 列表访问
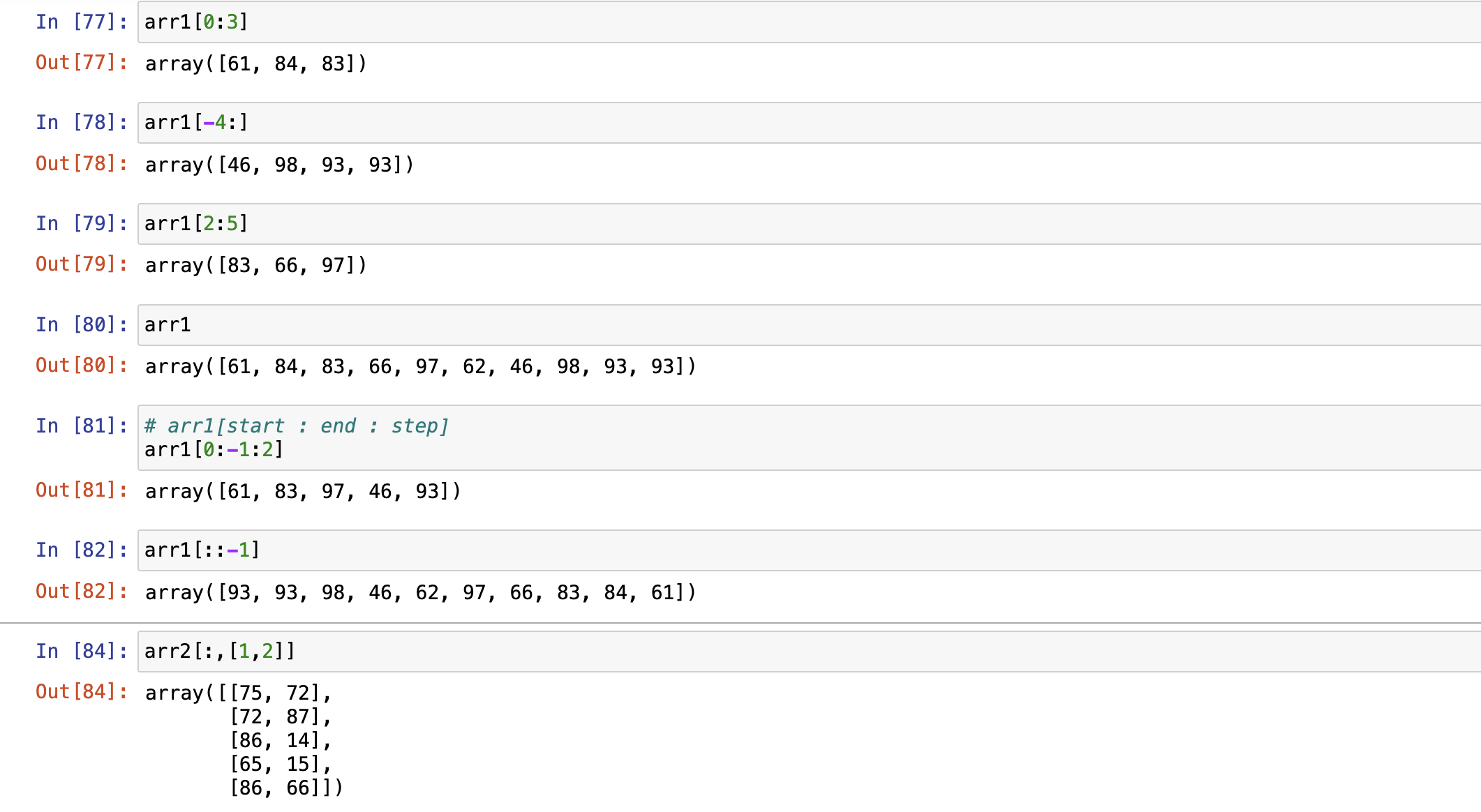
- 切片访问
索引访问

为避免间接访问造成的安全隐患,和性能损失,使用直接访问,如下
【重点1】ndarray的高维数组直接访问,使用[dim1_index, dim2_index...]

列表访问
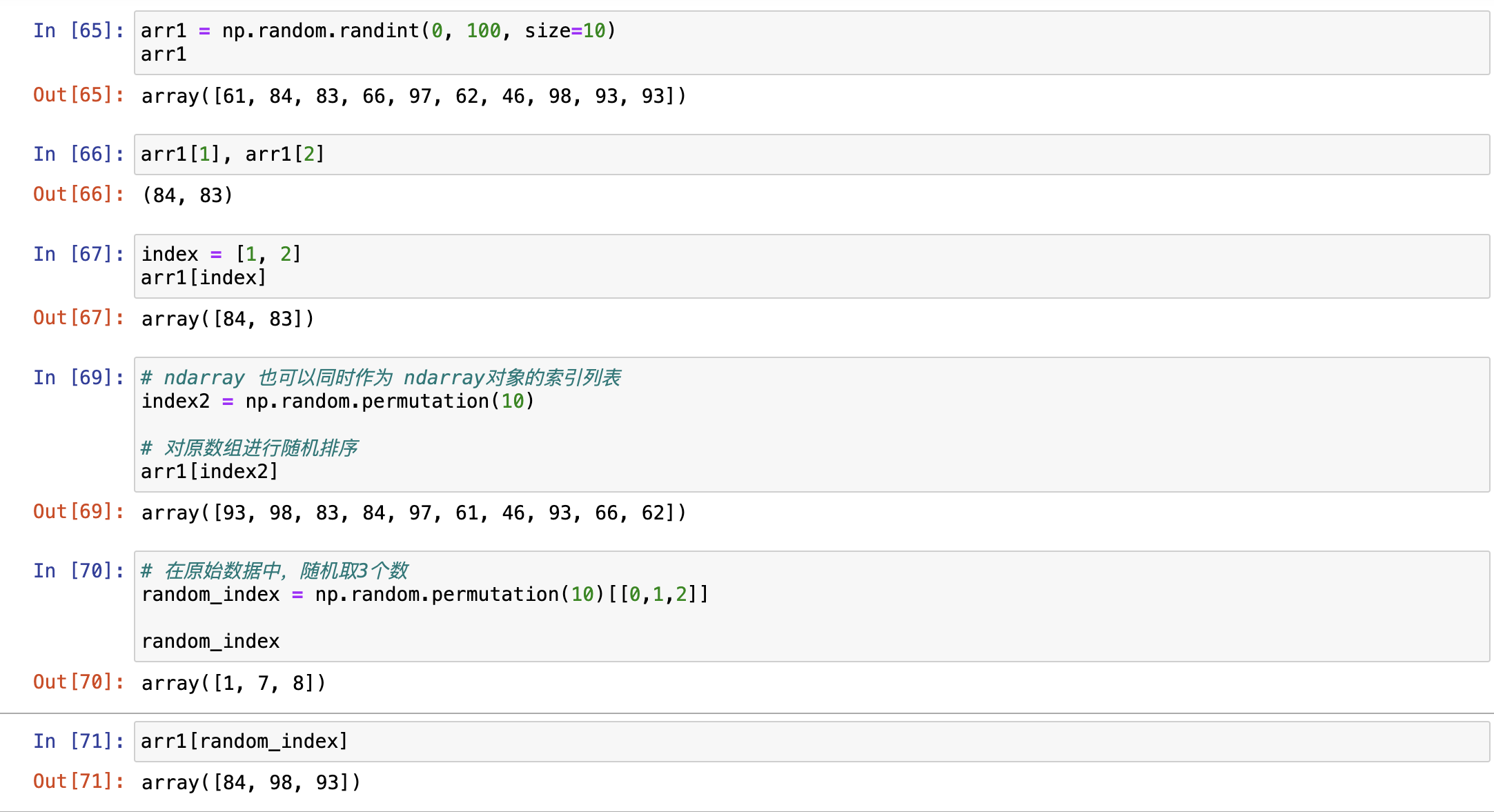
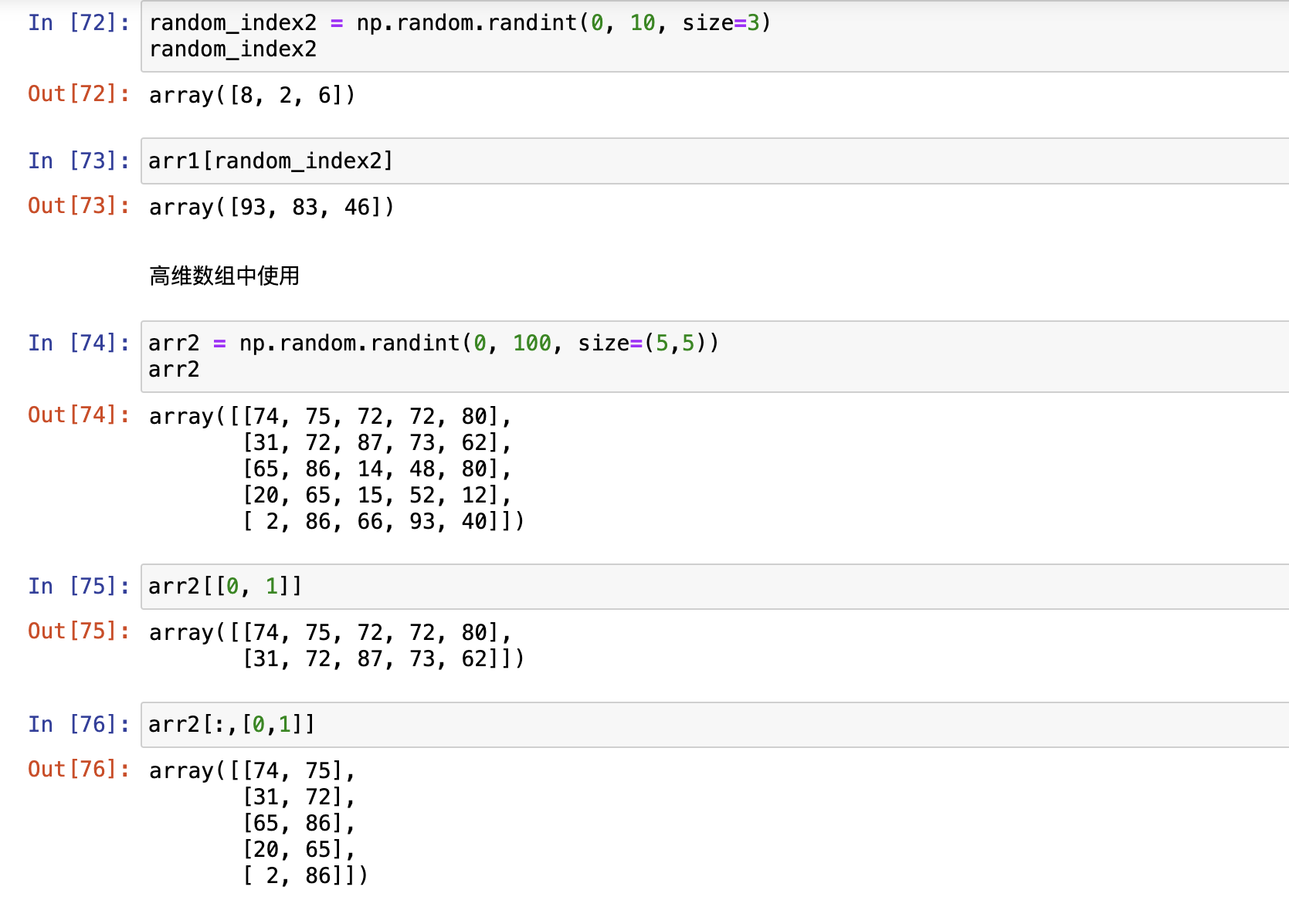
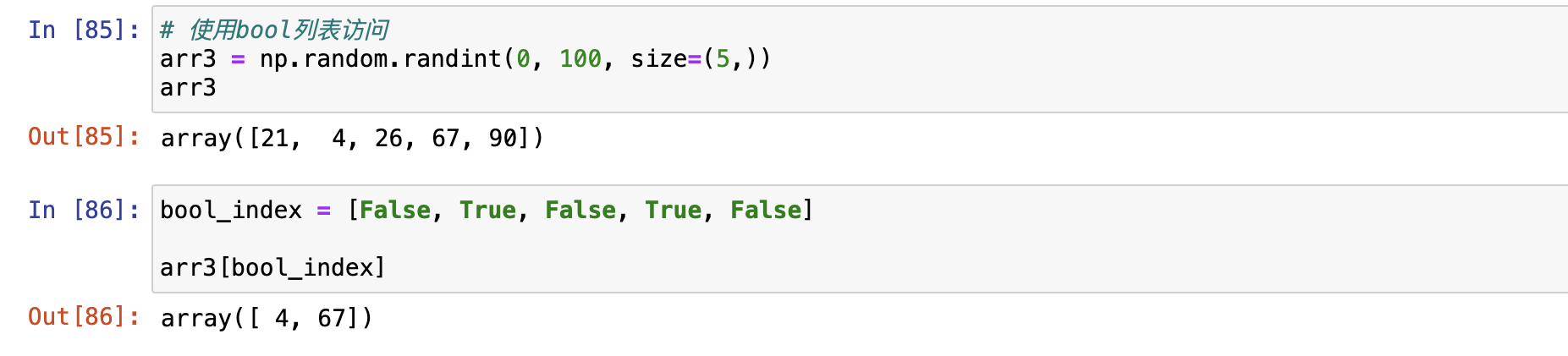
列表访问也支持布尔列表
切片访问
习题
1. 构建一个长度为10的随机数组,进行逆序输出
2. 构造一个形状为(5,4)的二维数组,提取最后两列,使用3种方法
3. 构建一个6行5列的数组,对数组进行行方向的随机排序


ndarray的级联和切分
级联
级联的注意事项:
级联的参数是列表:一定要加中括号或小括号
维度必须相同
形状相符
级联的方向默认是shape这个tuple的第一个值所代表的维度方向
可通过axis参数改变级联的方向
np.concatenate()
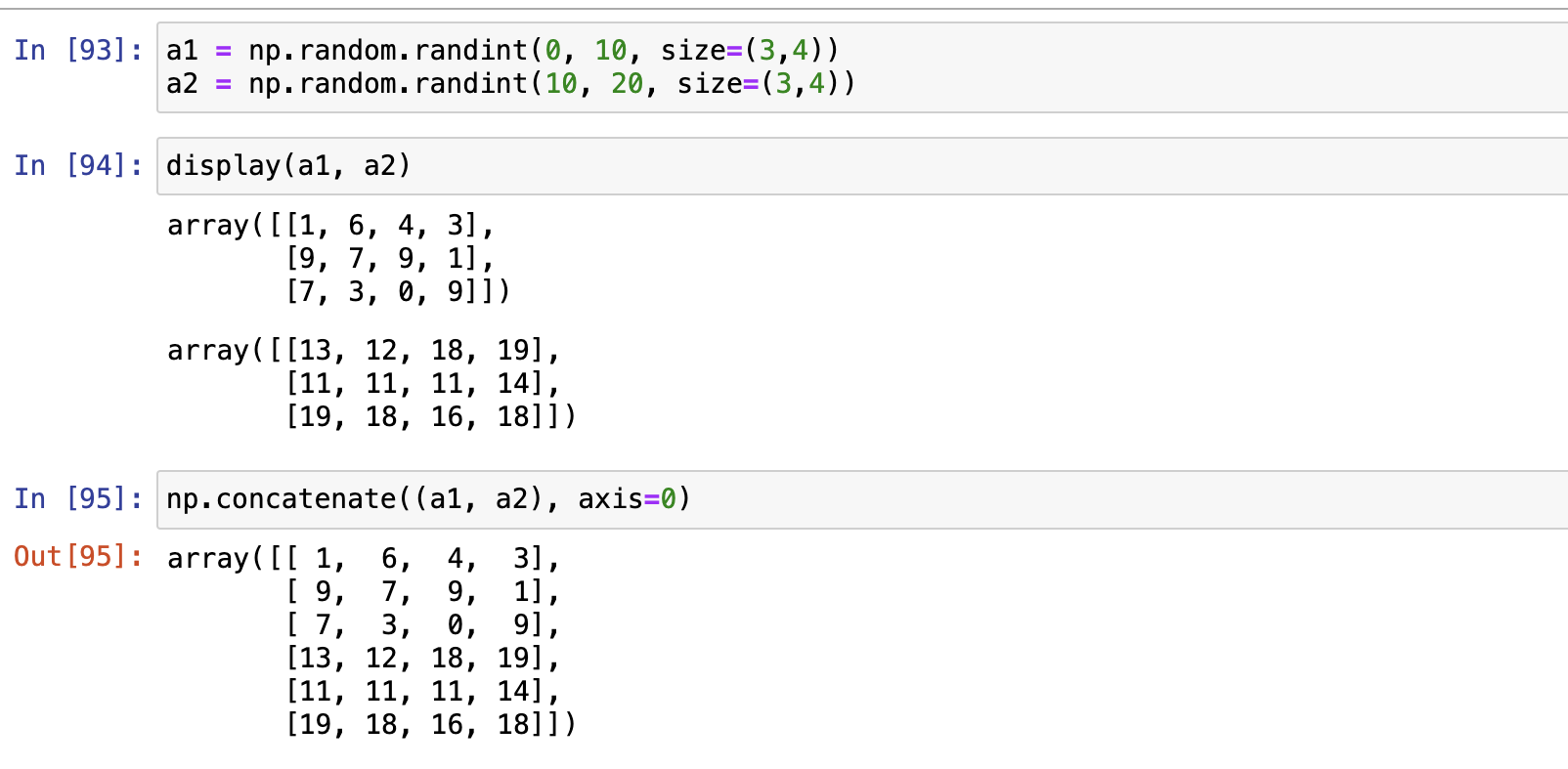
参与级联的数组维度必须一致
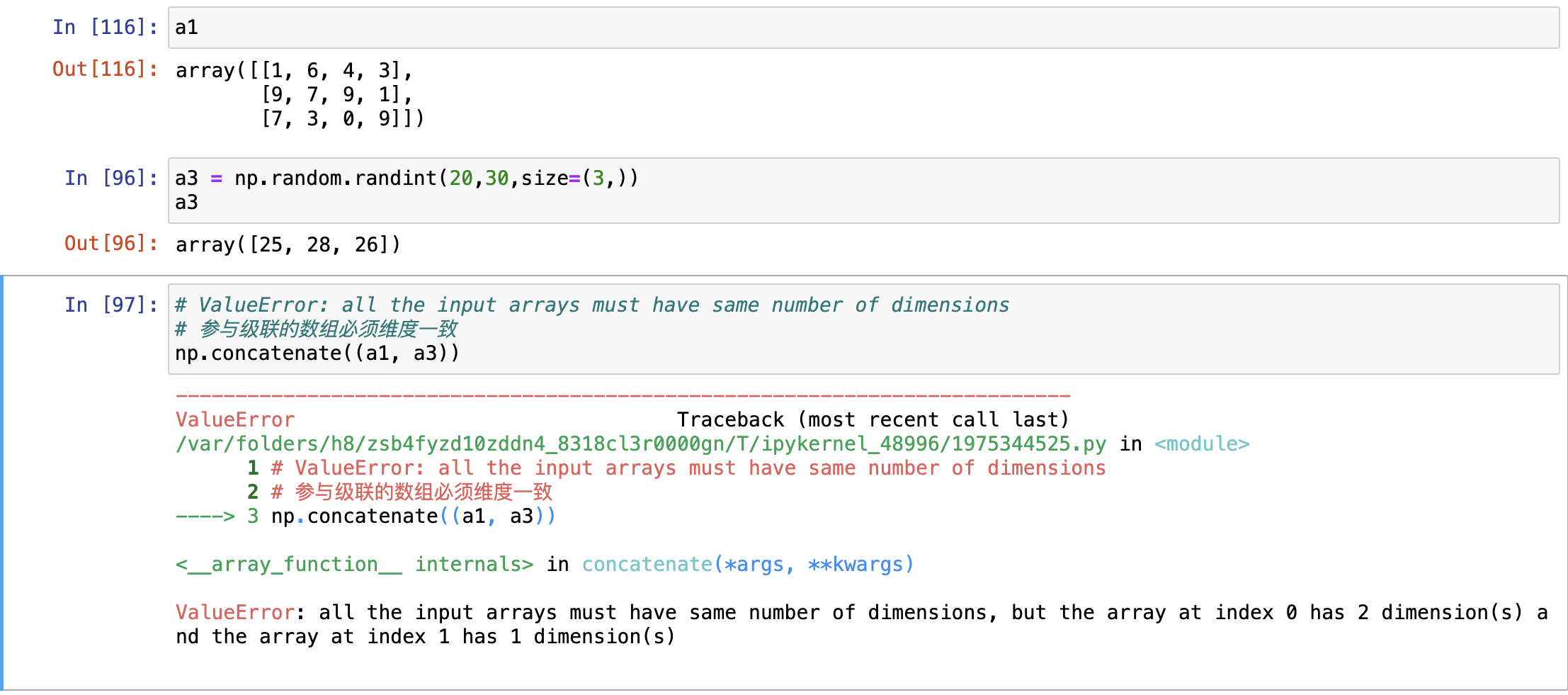
在级联的维度上,必须长度一致
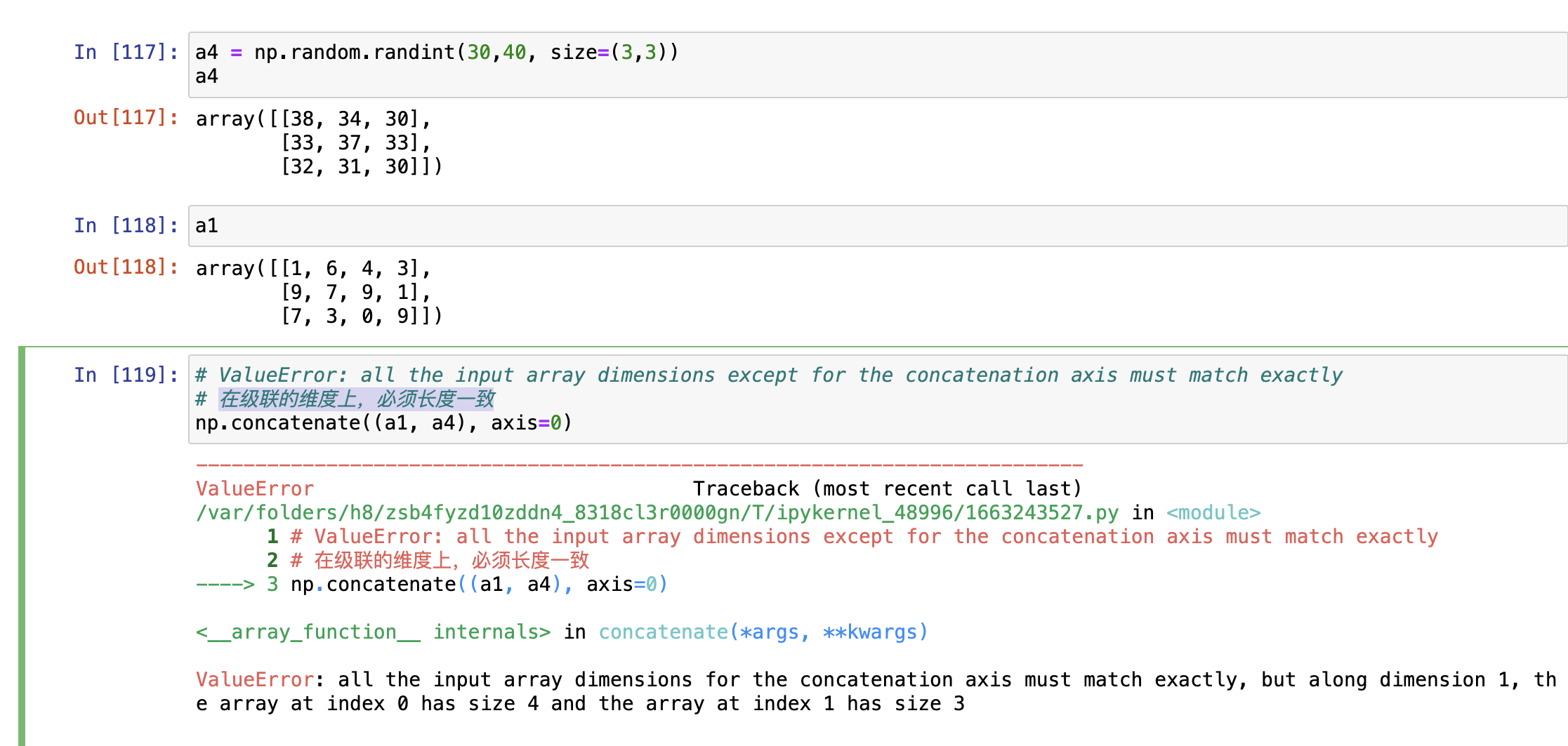
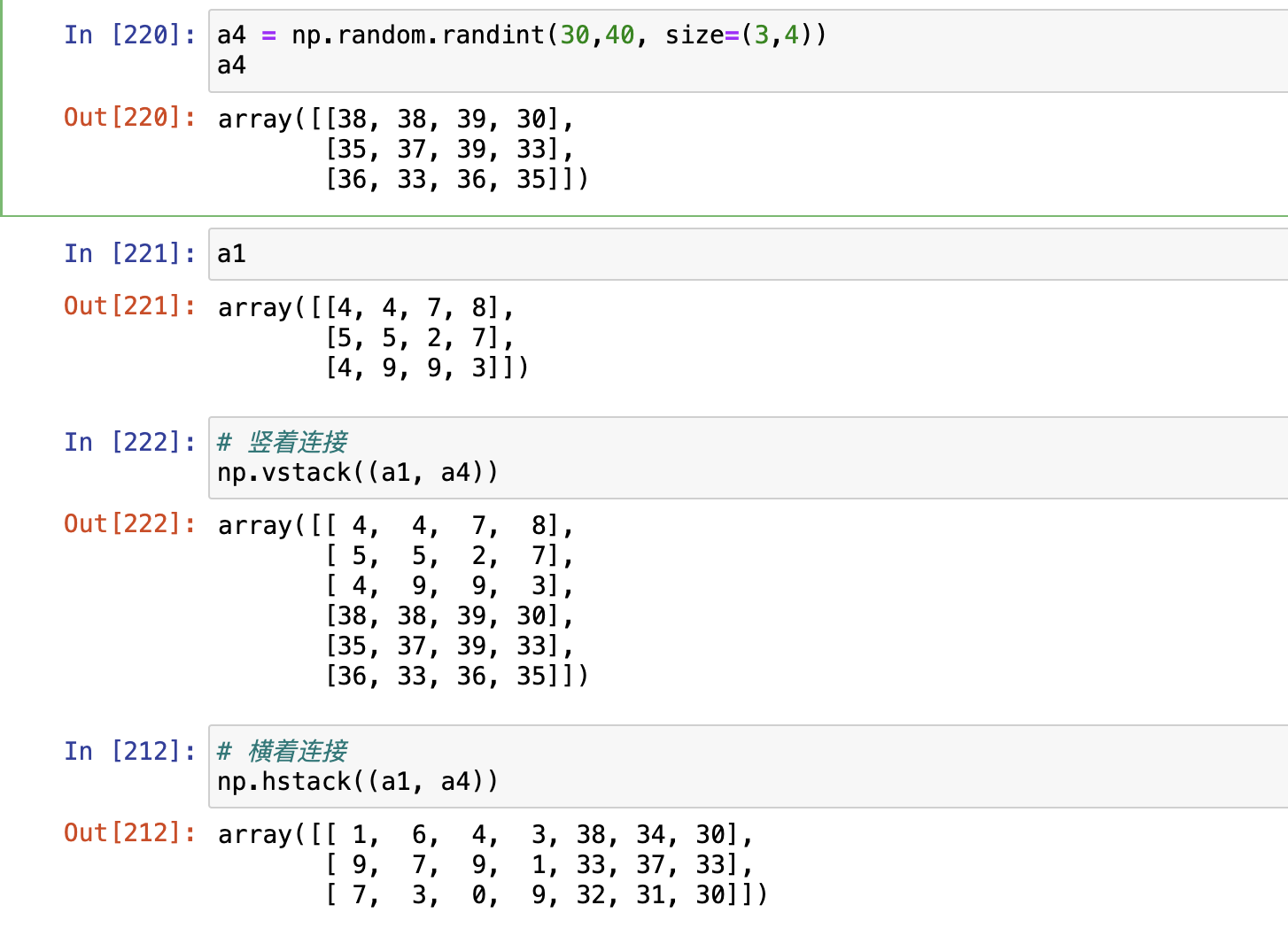
np.hstack与np.vstack
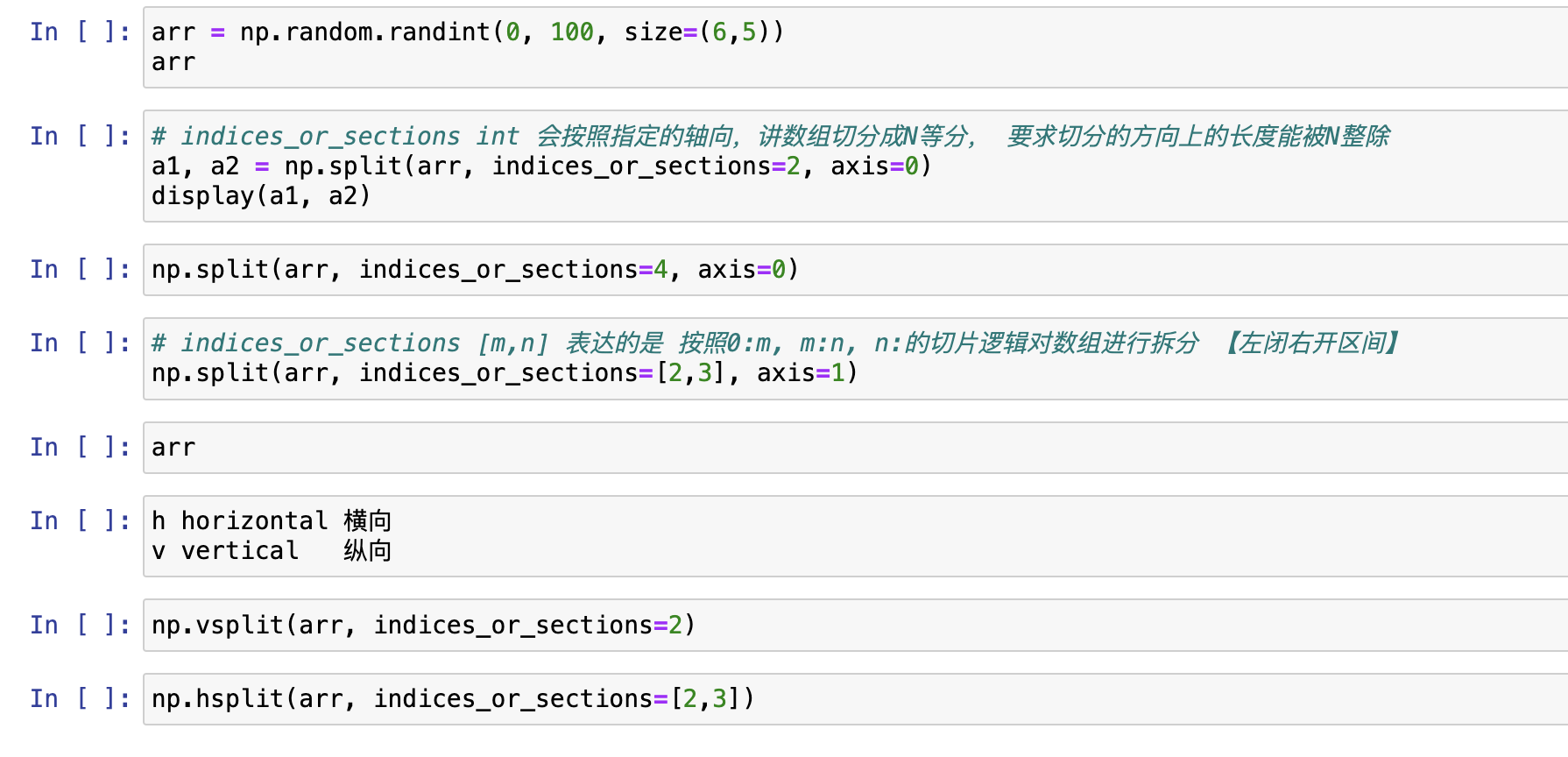
切分
与级联类似,三个函数完成切分工作:
- np.split
- np.vsplit
- np.hsplit
习题
1. 生成两个形状分别为(4,4)和(8,4)的二维整型数组,尝试级联
2. 使用两种方法将上题级联的结果保存并拆分成3等份
3. 生成一个长度为5的一维整型数组,将类型修改为float32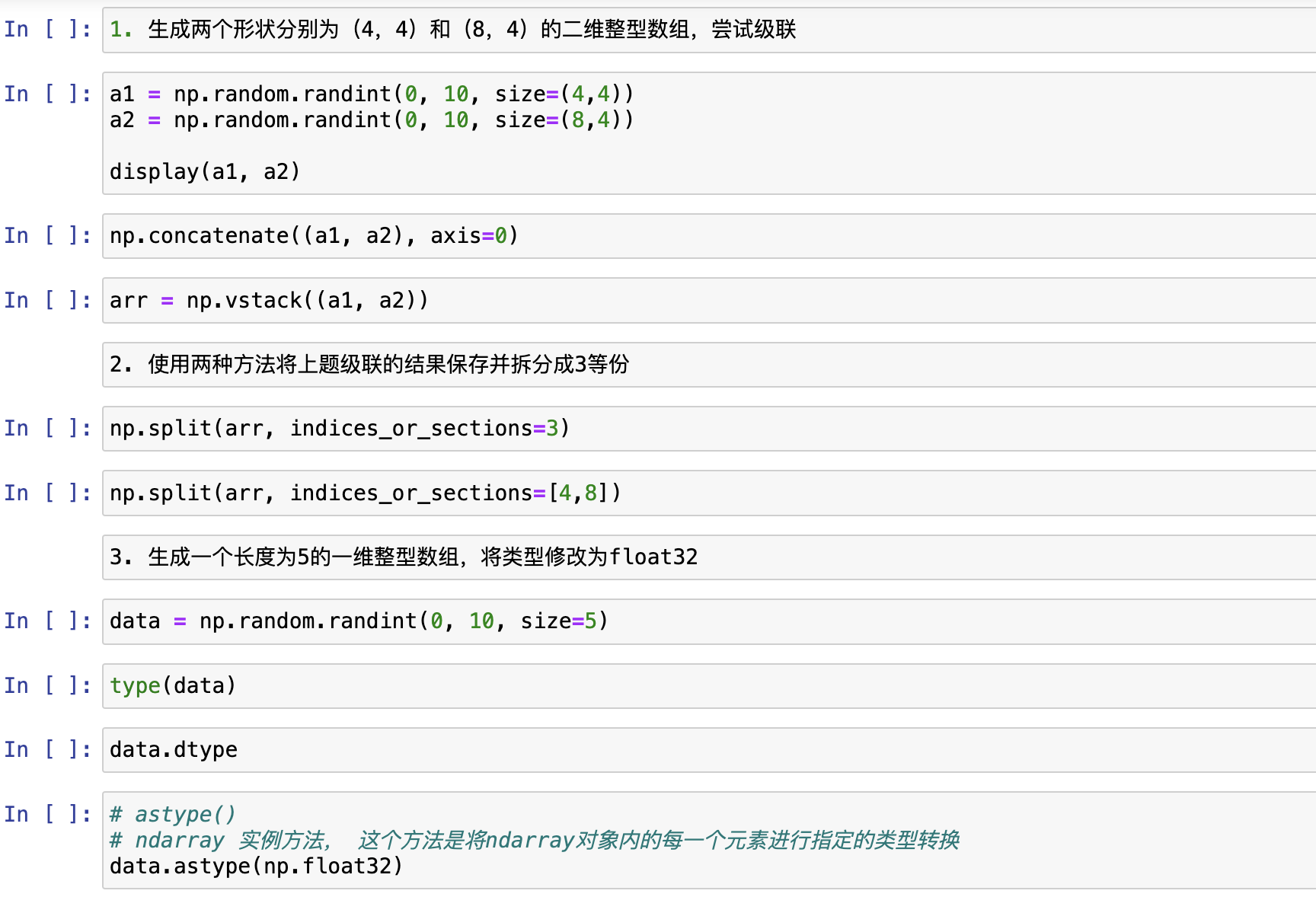
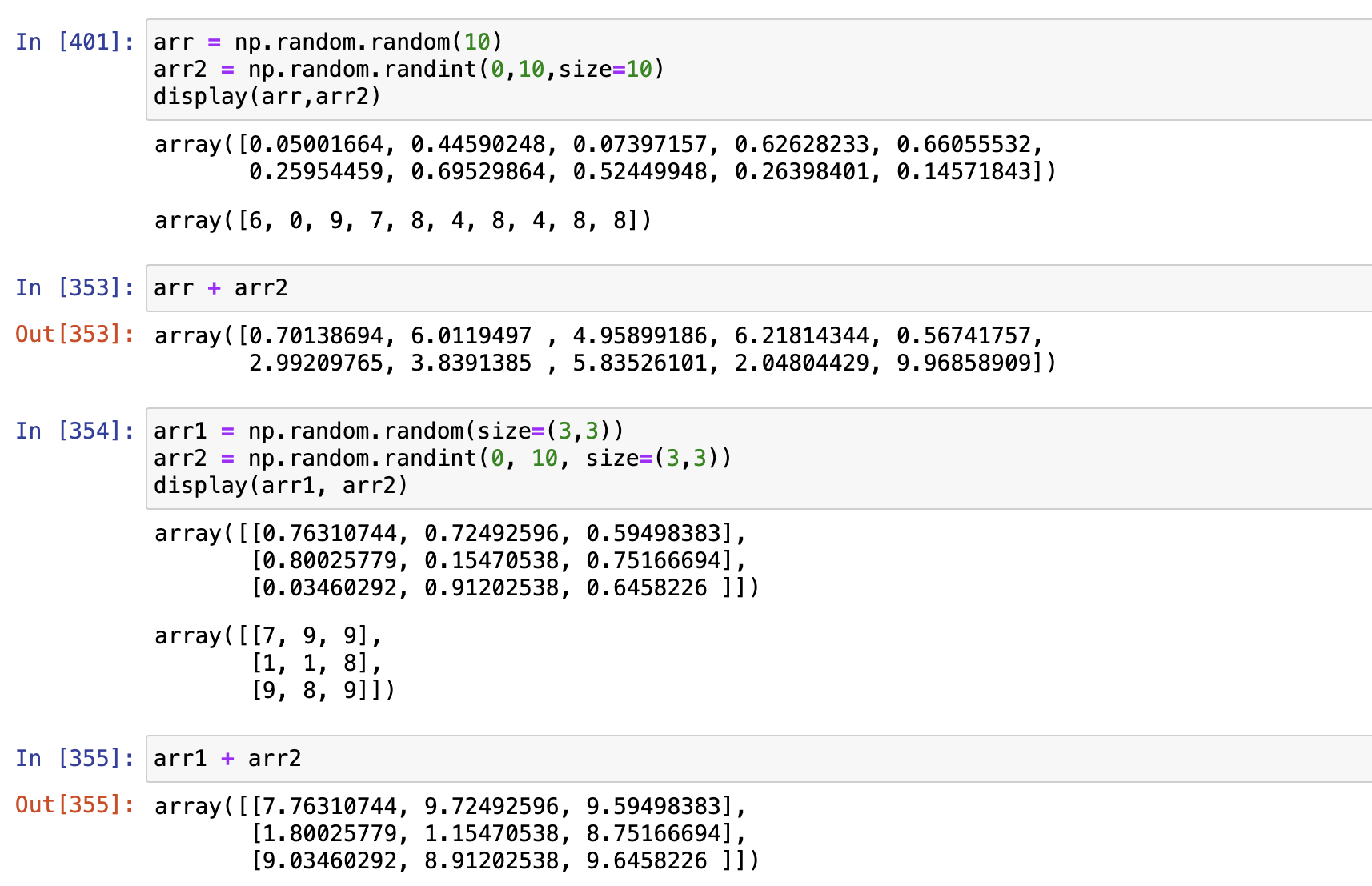
ndarray的运算
基本运算原则
两个矩阵运算,就是对应位置的数据的运算

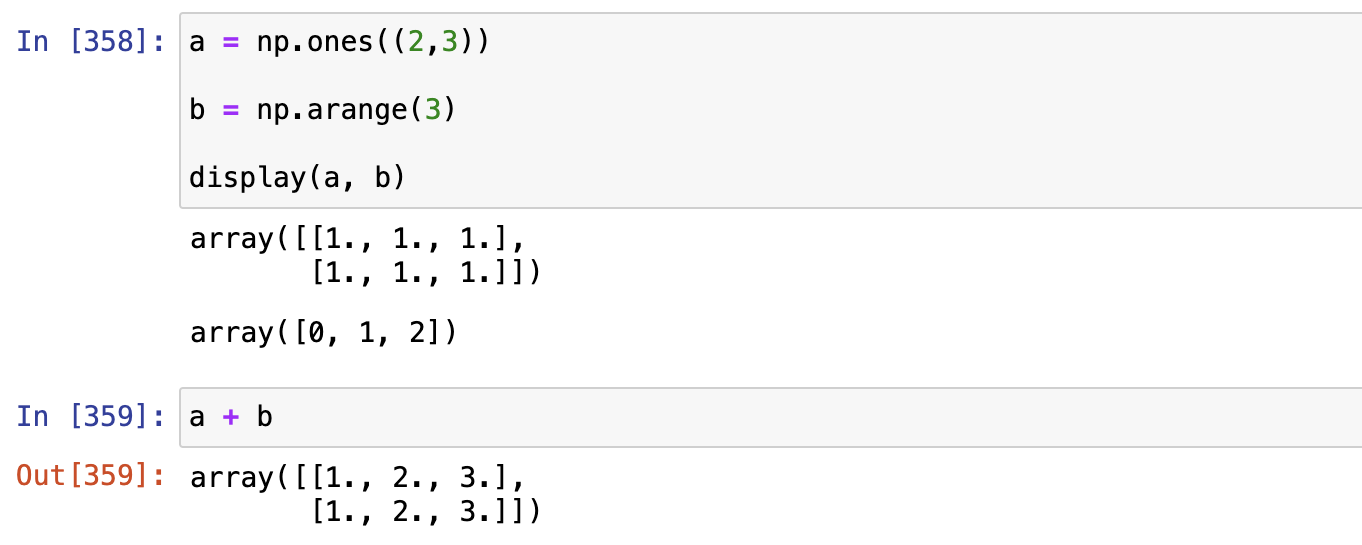
广播 Broadcast
核心思想:变形
ndarray广播机制的两条规则
如果
- 两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符
- 或其中的一方的长度为1
则认为它们是广播兼容的。 广播会在缺失和(或)长度为1的维度上进行。
- 例1: a = np.ones((2, 3)) b = np.arange(3) 求a + b
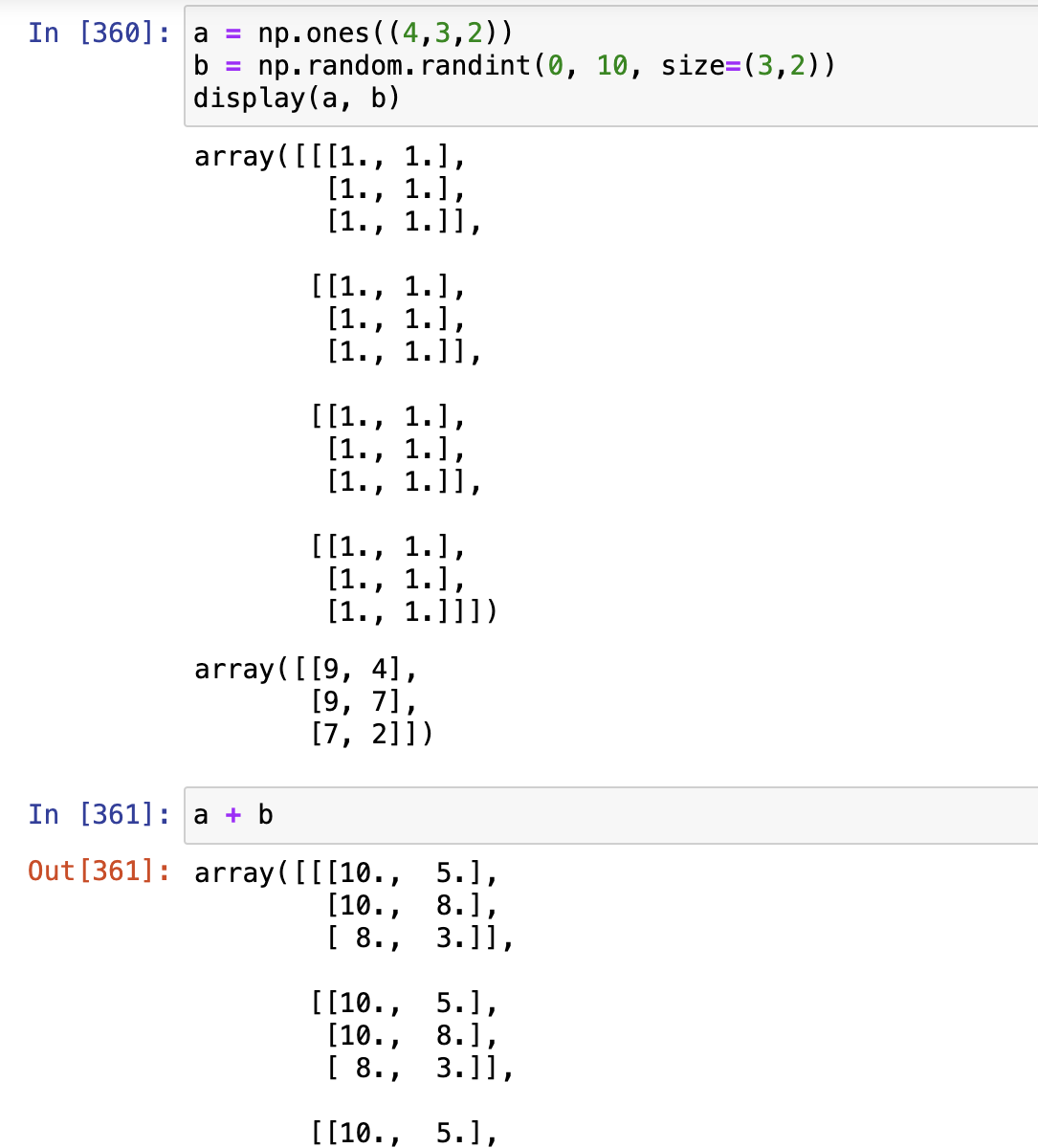
例2: a = np.ones((4,3,2)), b = np.random.randint(0,10,size=(3,2)), 求a+b
例3:a = np.arange(3).reshape((3, 1)), b = np.arange(3), 求a+b

习题
1. a = np.ones((4, 1)), b = np.arange(4), 求a+b
2. 假设我们有100个员工考勤需要处理,由于上个月统一调休,所以需要将所有人的总考勤天数-1,如何操作?
3. 假设员工上班时间表通过np.random.randint(7,10,100)获取,如何快速找到上班时间不足8小时的员工?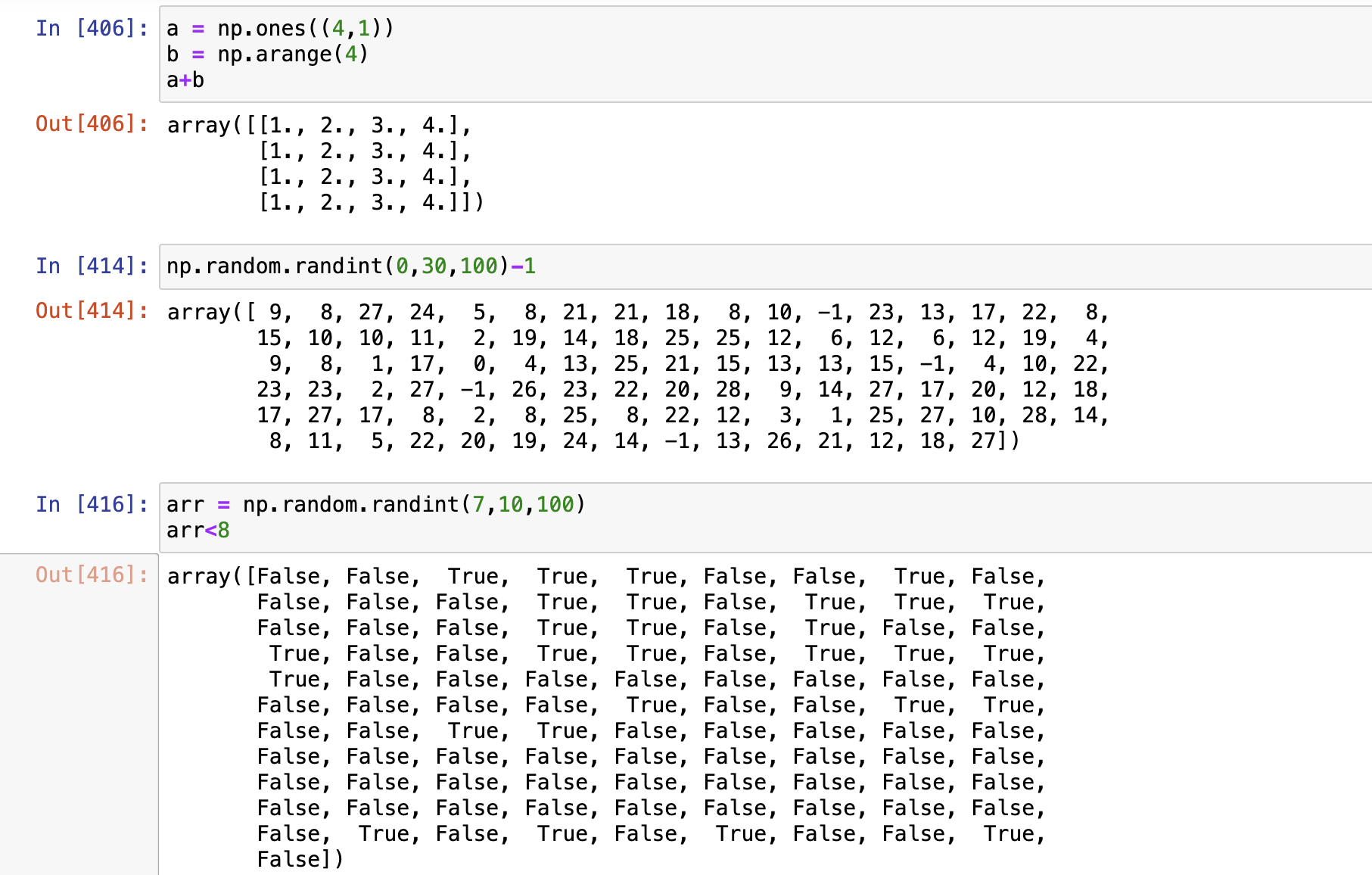
ndarray的聚合操作
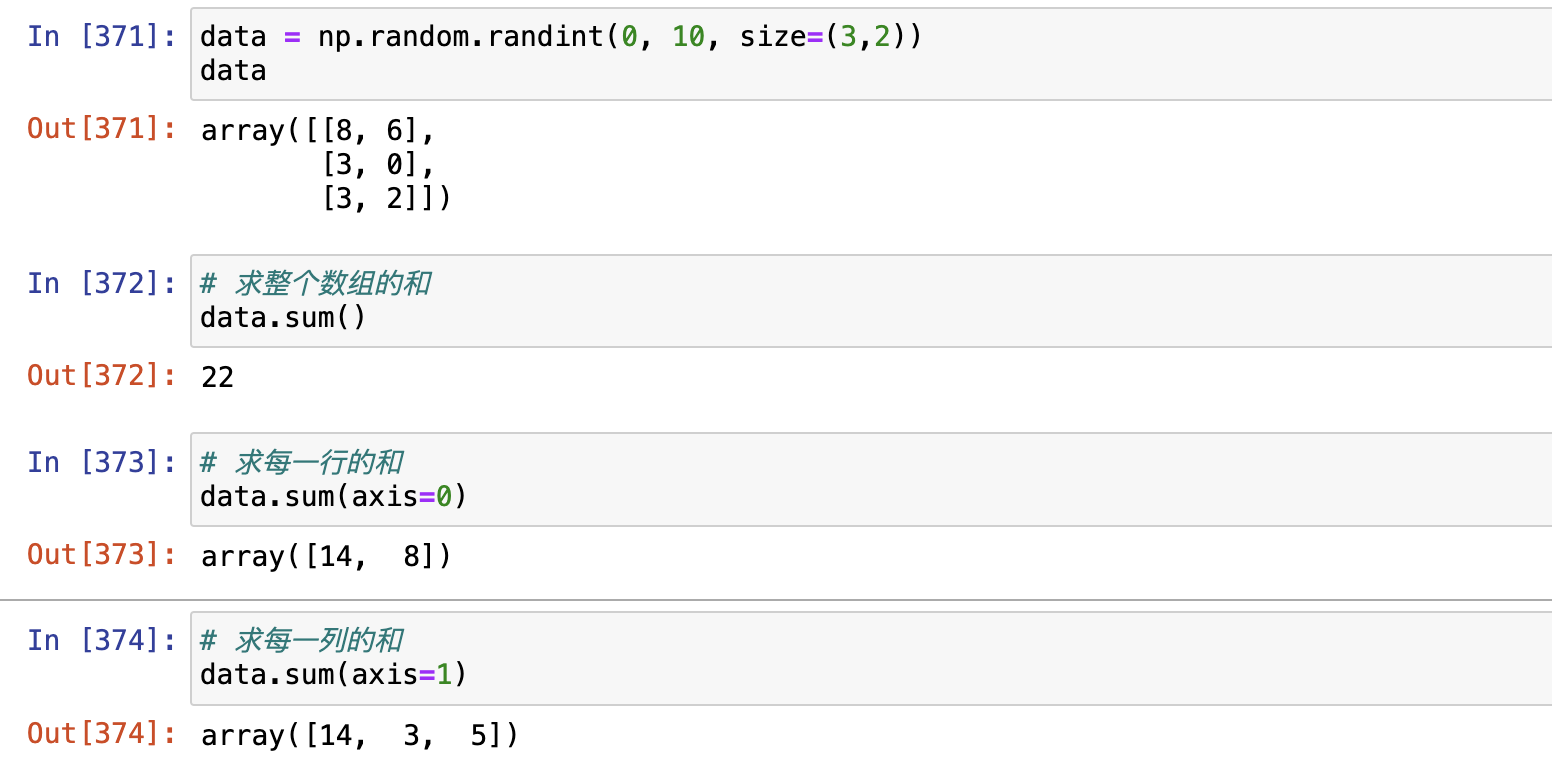
求和
- np.sum
- np.nansum
空值
- np.nan
- np.nan和None的区别:None是NoneType对象类型,np.nan是float类型,float的运算效率比None高。
- 和np.nan做的任何运算,结果都是np.nan
- 所以出现了np.nansum

最大最小值np.max/ np.min

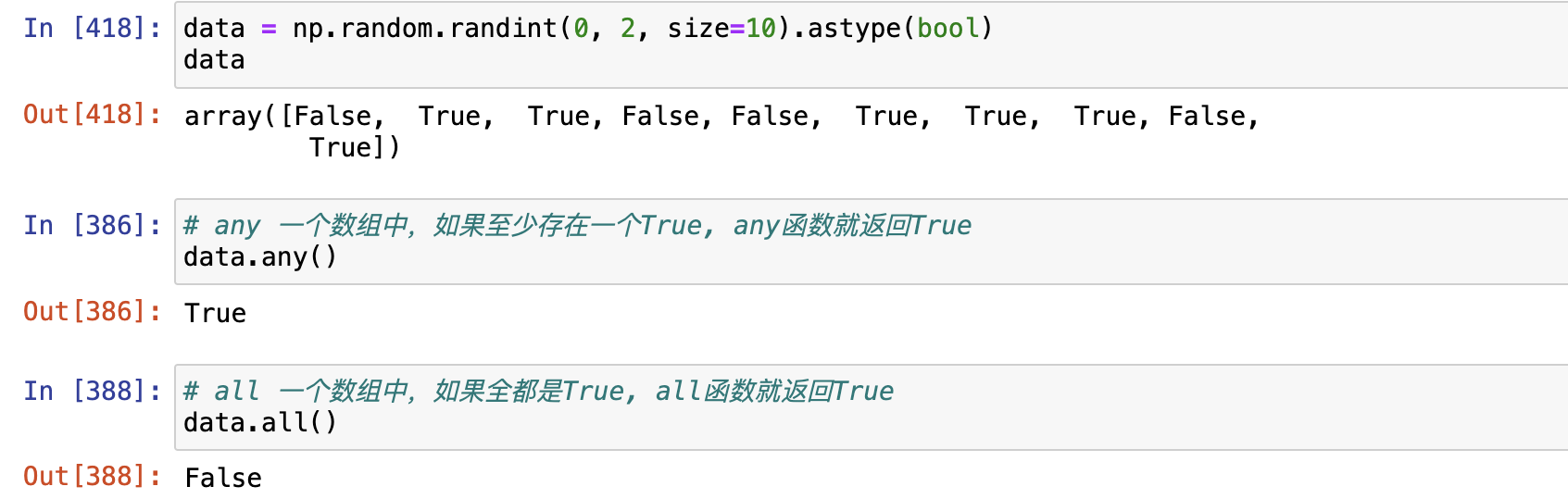
any() 和 all()
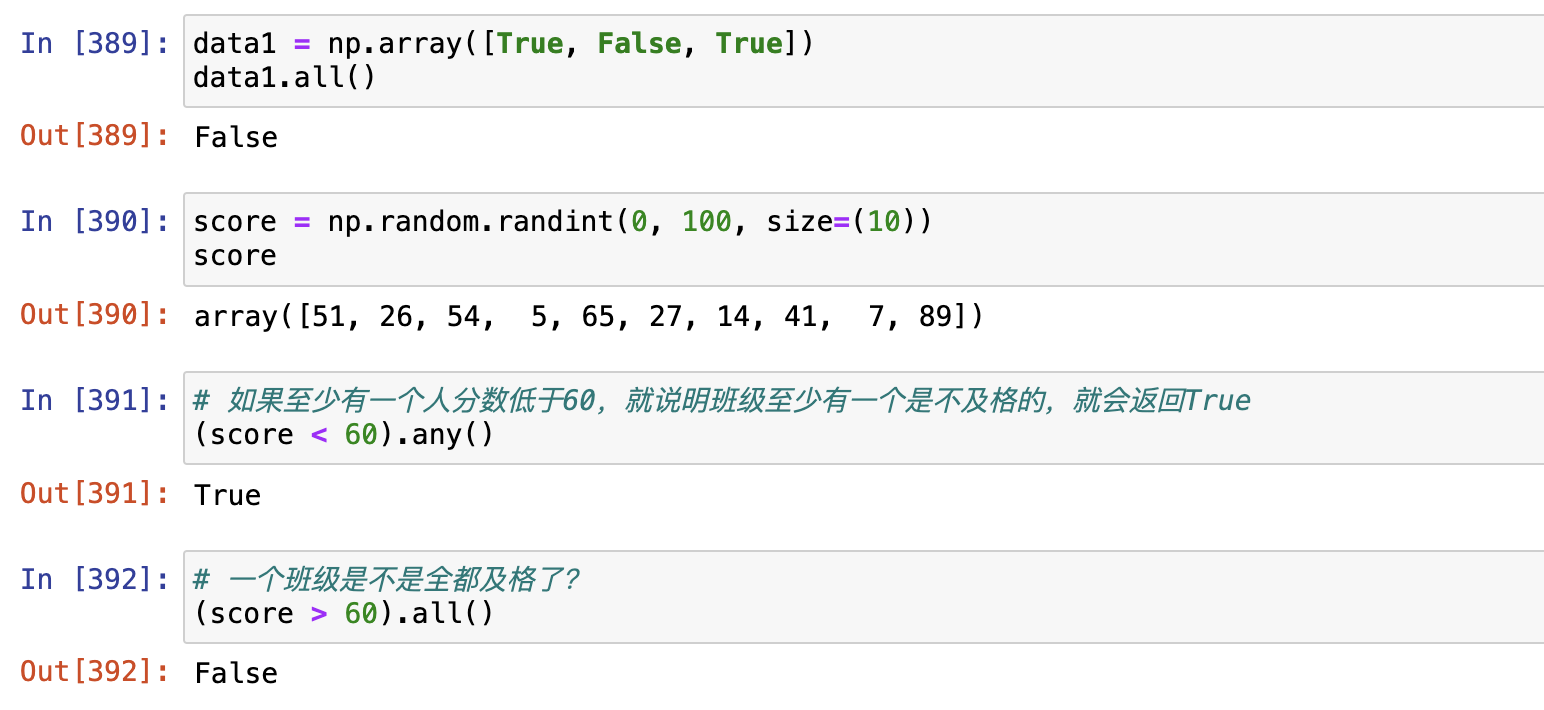
常用聚合函数
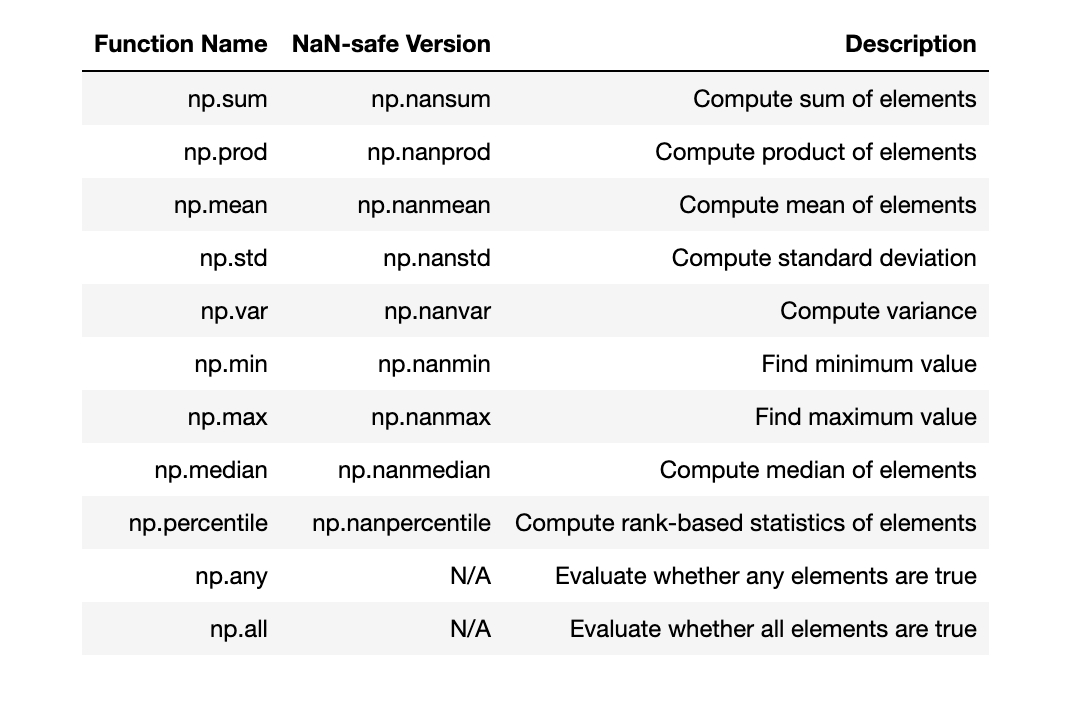
习题
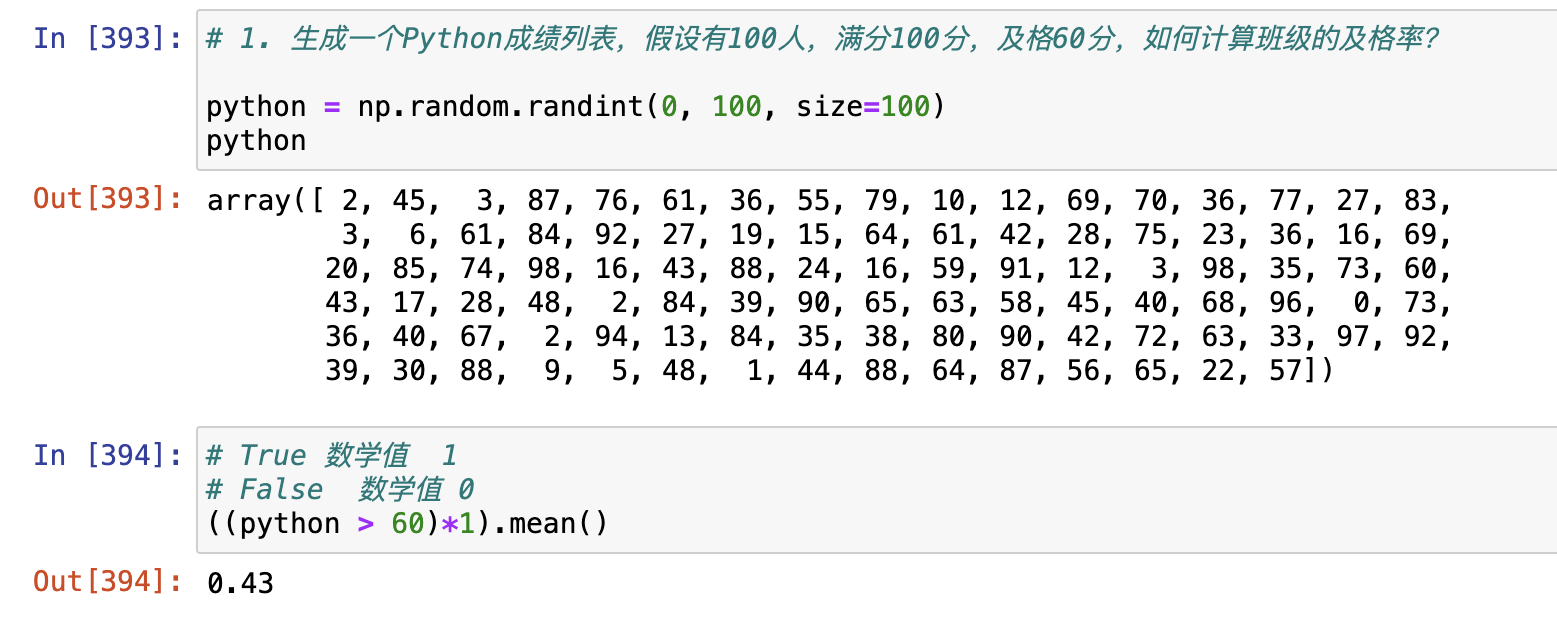
1. 生成一个Python成绩列表,假设有100人,满分100分,及格60分,如何计算班级的及格率?
2. 标准化就是将一组数据进行如下规则的转换: 减去期望值再除以样本方差,请封装一个函数来实现
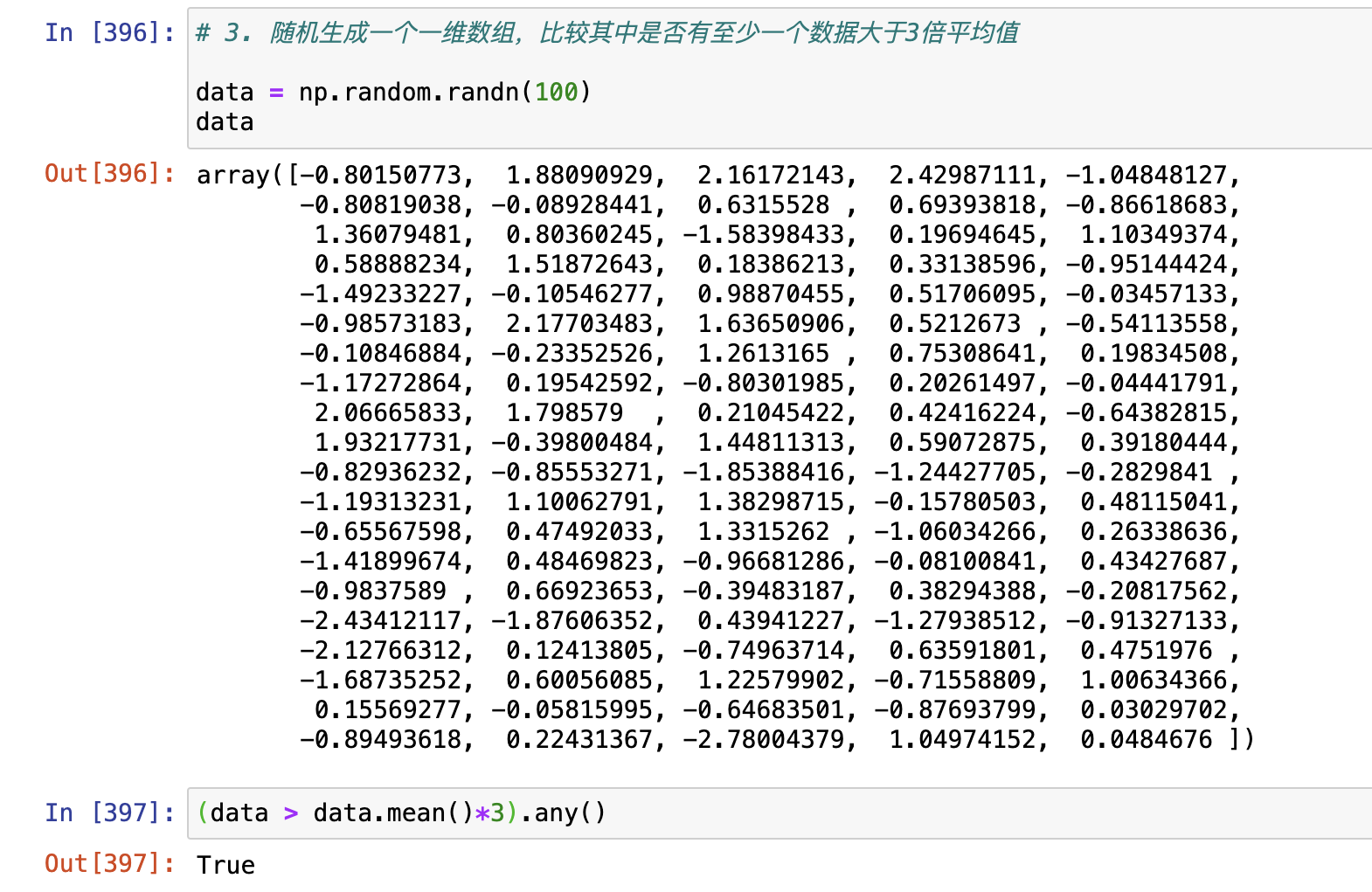
3. 随机生成一个一维数组,比较其中是否有至少一个数据大于3倍平均值
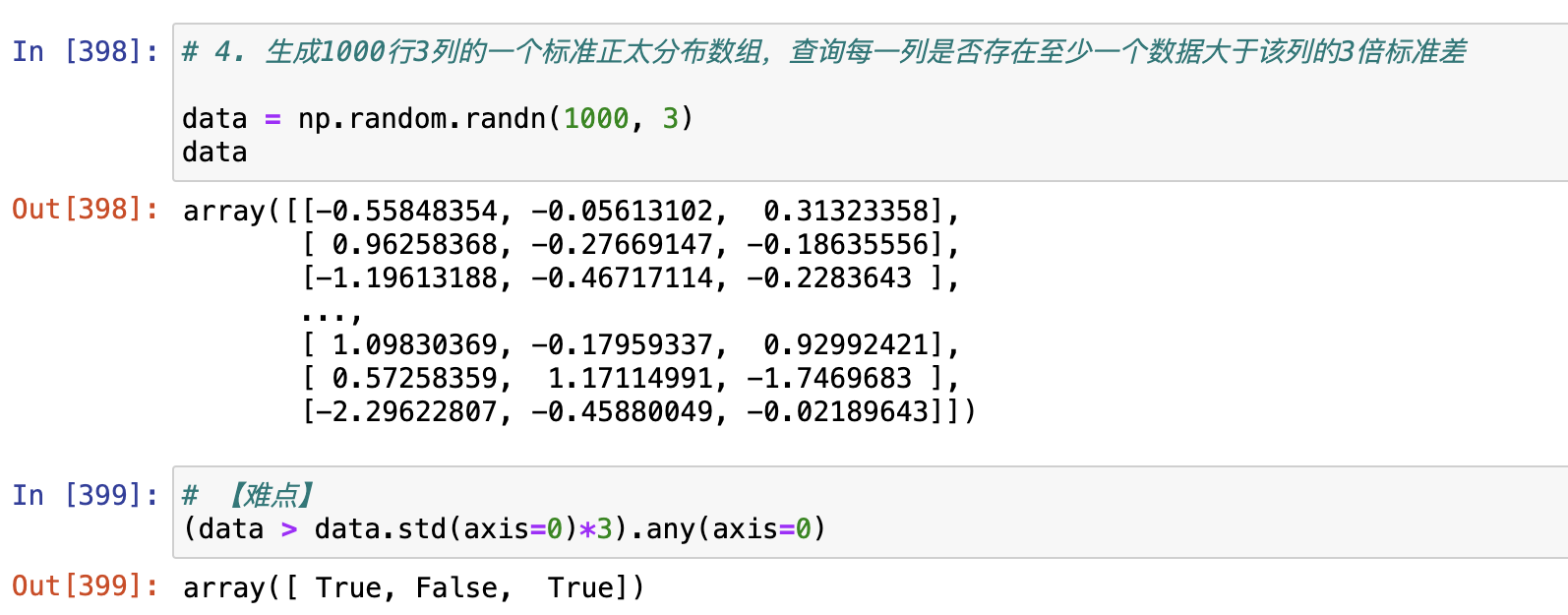
4. 生成1000行3列的一个标准正太分布数组,查询每一列是否存在至少一个数据大于该列的3倍标准差
5. 如何检查两个形状相同的数组数值是完全一致的?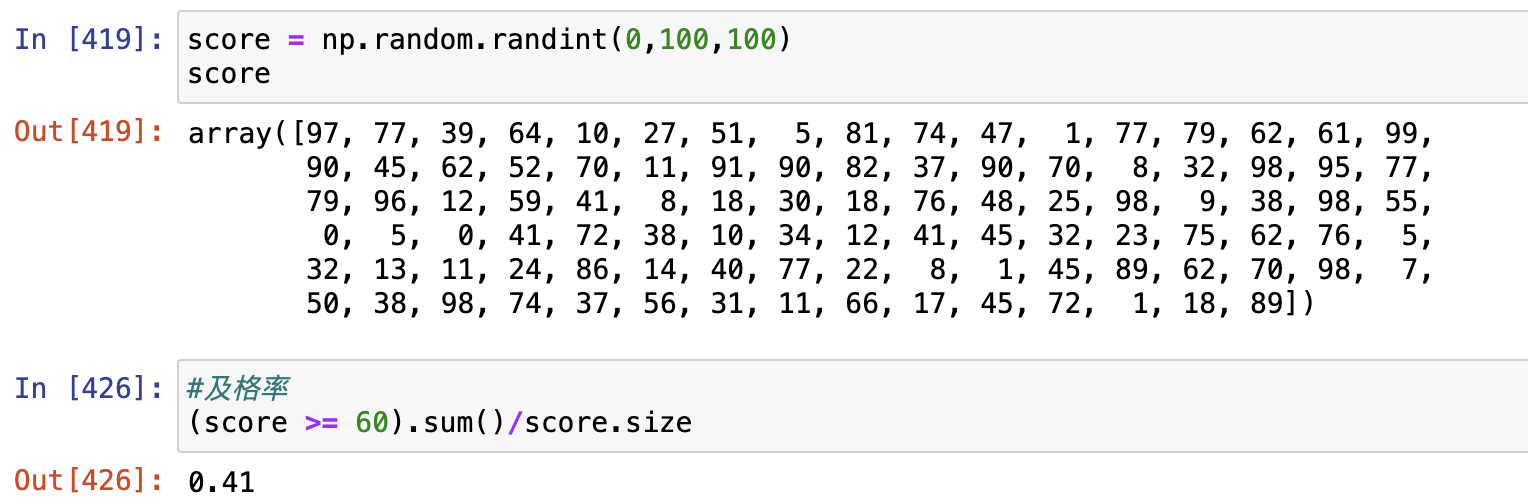
或者


Numpy数组操作
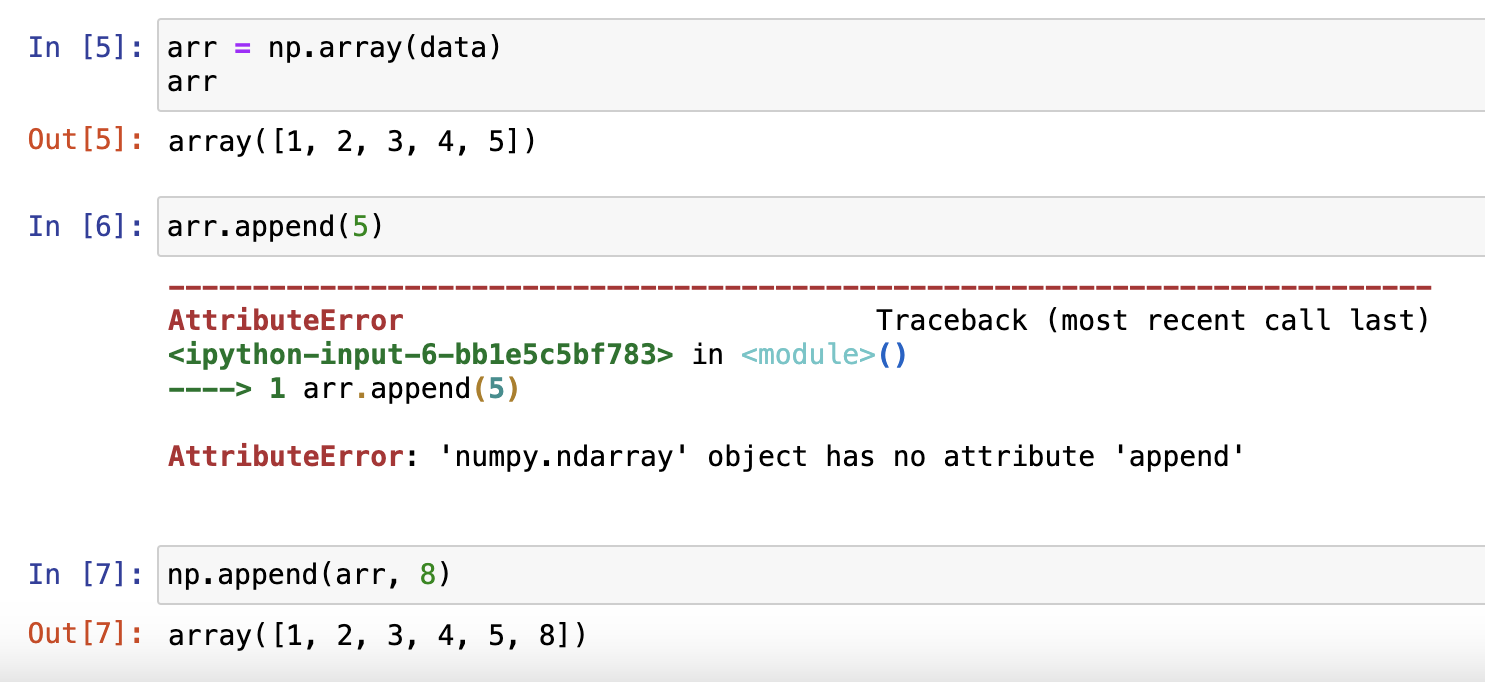
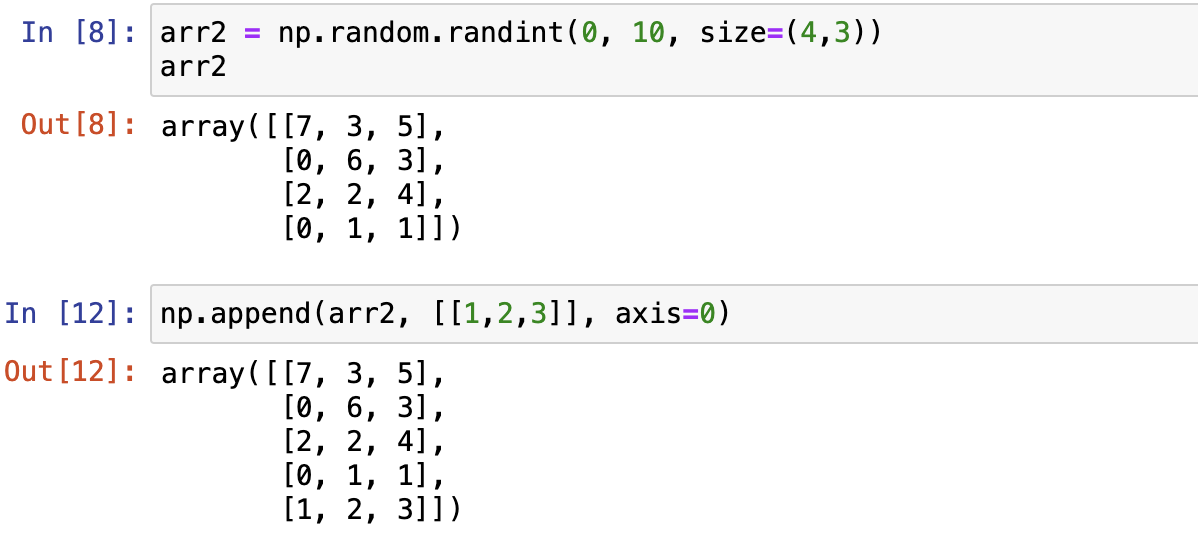
- numpy.append()
- numpy.insert()
- numpy.delete()
上述数组操作的方法都不是实例化方法,无法对数组对象直接操作,需要np.方法(不改变原数组,输出的是副本)
- numpy.reshape()
- numpy.ndarray.flat
- numpy.ndarray.flatten()
- numpy.transpose
上述方法可以直接arr.方法,也可以np.方法,(arr.方法相当于直接操作数组对象,改变原数组,建议使用np.方法)
添加元素
numpy.append 函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中
注意:
- 插入的维度要保证所有数组的长度是相同的
- 如果没有指定轴,数组会被扁平处理
- 如果两数组维度不同,会报错
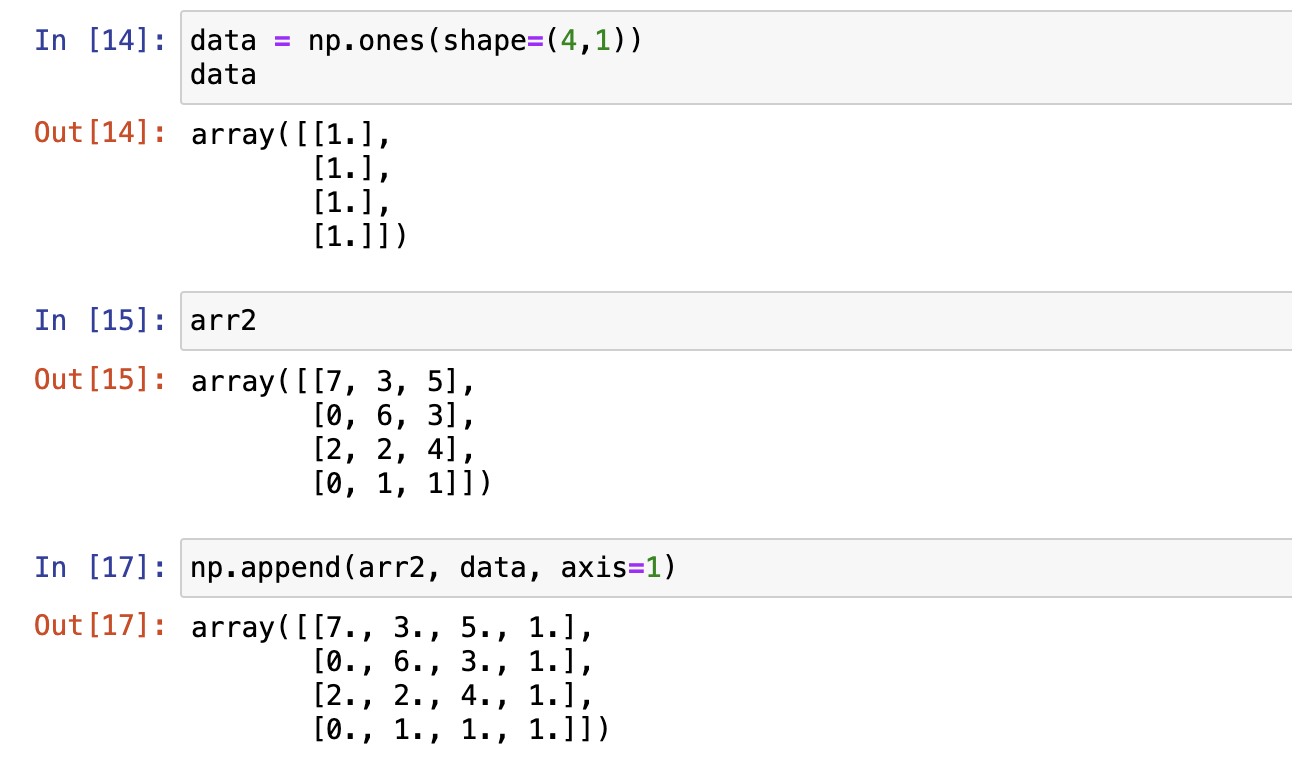

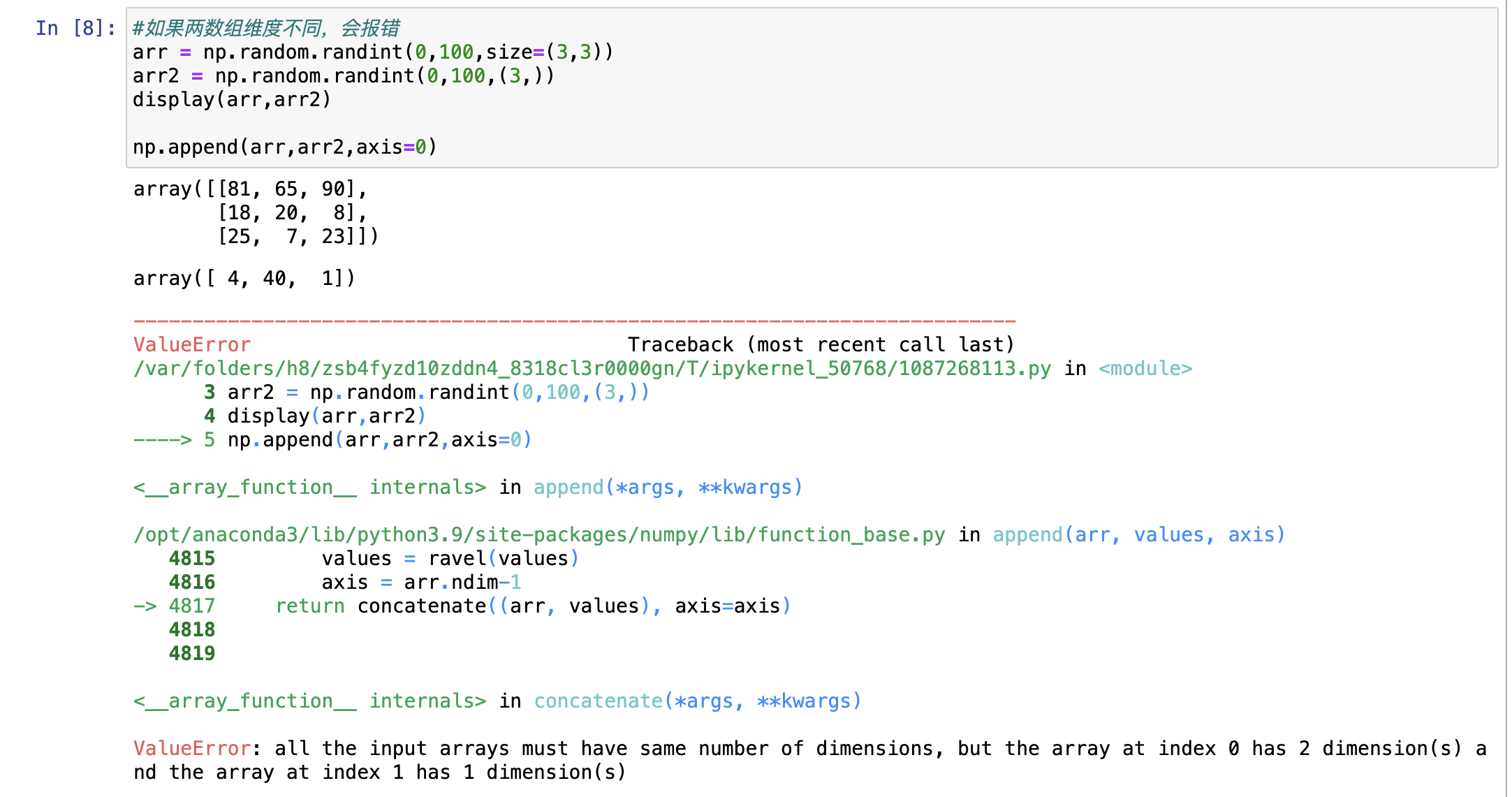
插入元素
numpy.insert ()在给定索引之前,沿给定轴在输入数组中插入值
如果未提供轴,则输入数组会被展开
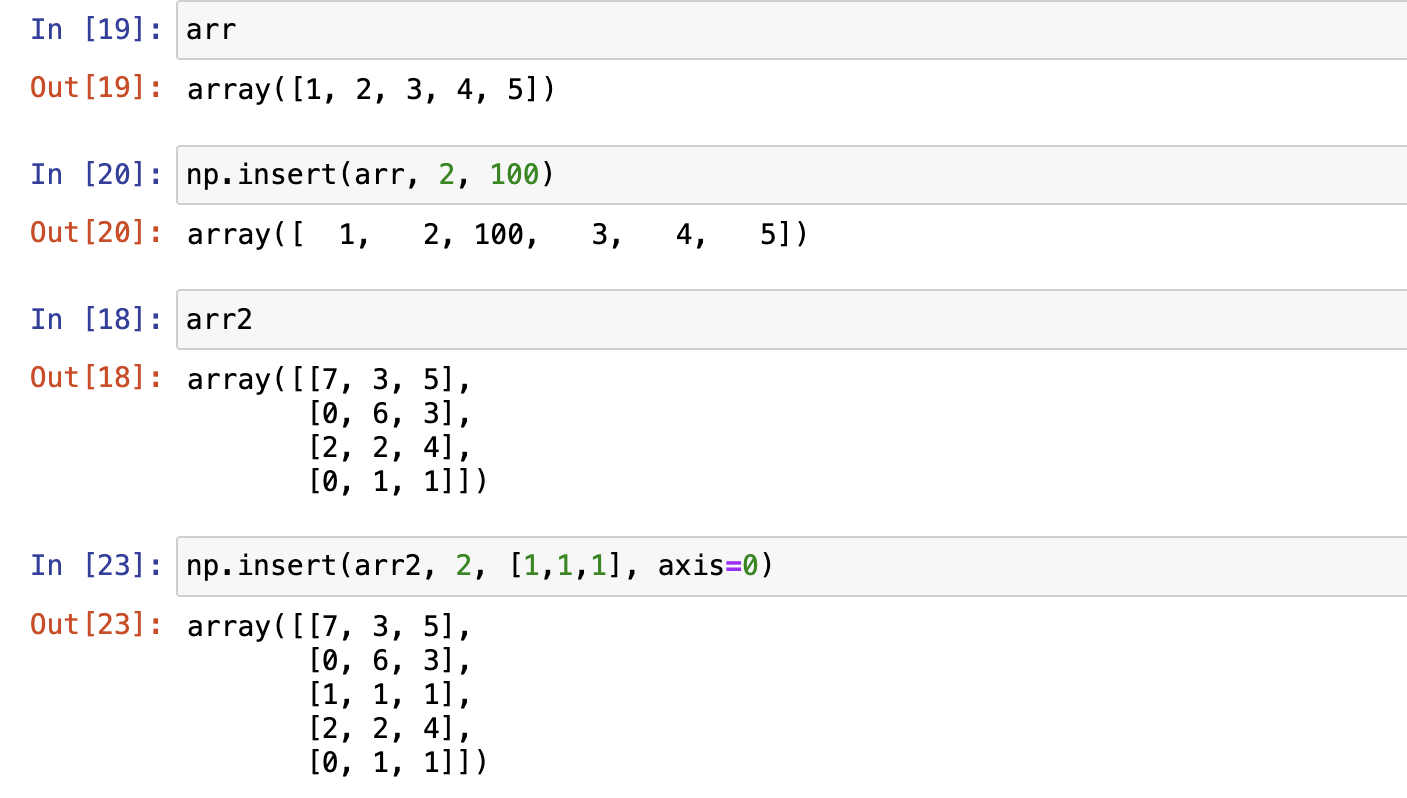
删除元素
numpy.delete 函数返回从输入数组中删除指定子数组的新数组。
如果未提供轴参数,则输入数组将展开。
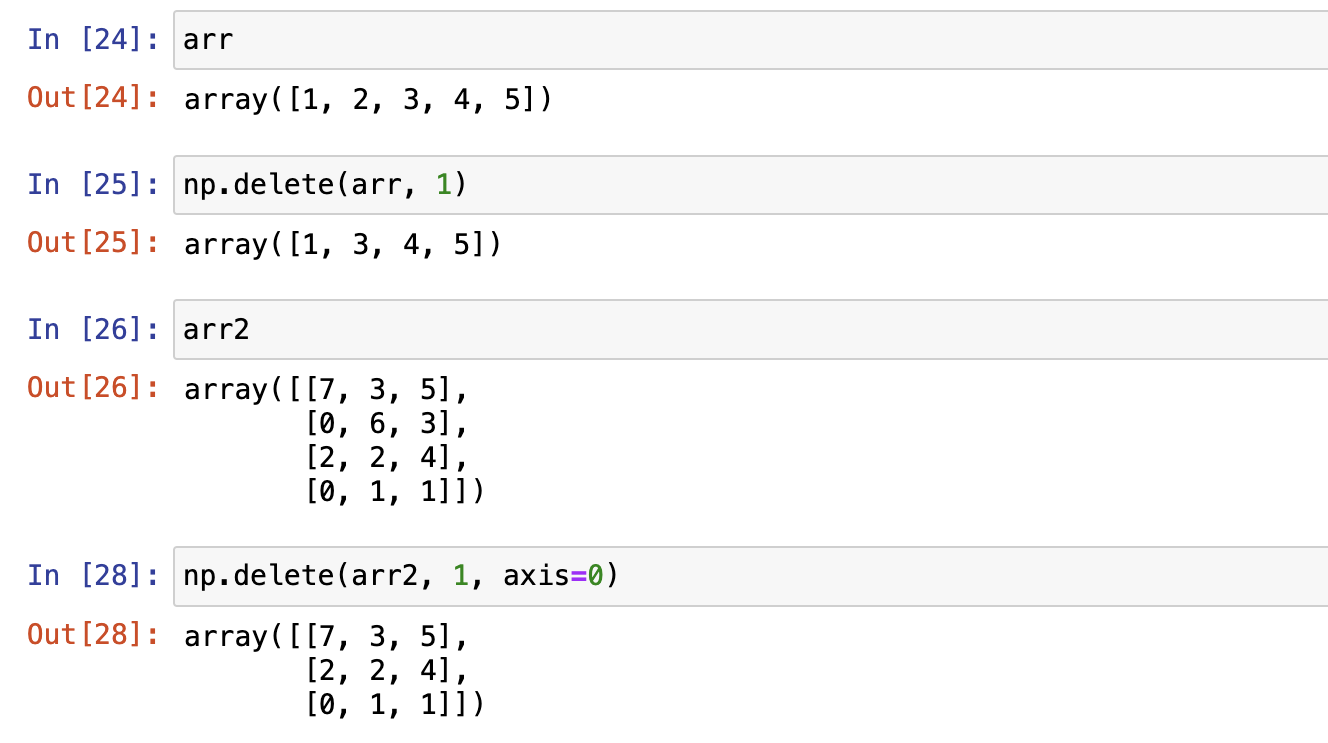
数组变形reshape
numpy.reshape 函数可以在不改变数据的条件下修改形状.
格式如下: numpy.reshape(arr, newshape, order='C')
- arr:要修改形状的数组
- newshape:整数或者整数数组,新的形状应当兼容原有形状
- order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'k' -- 元素在内存中的出现顺序。

数组迭代器
numpy.ndarray.flat
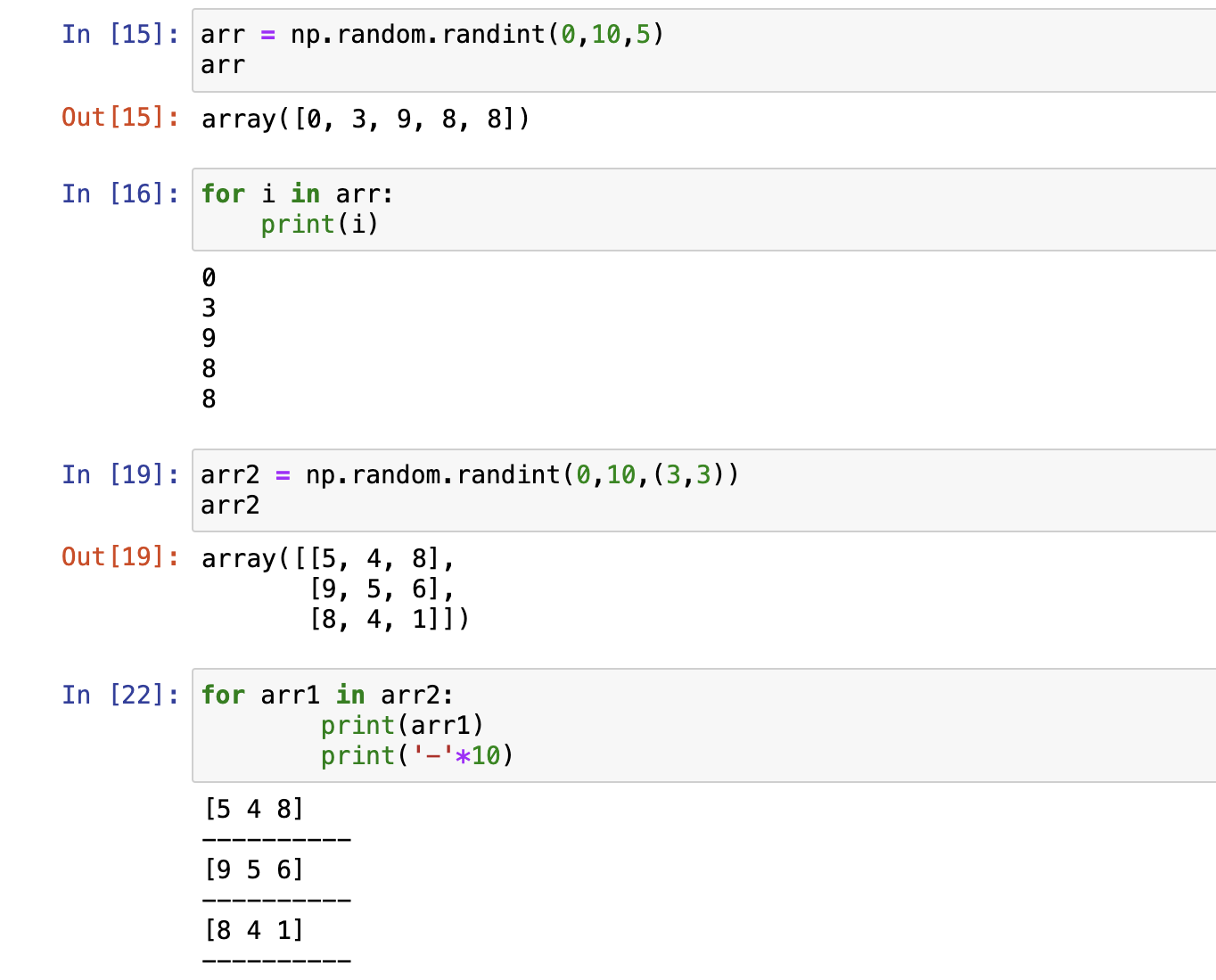
数组扁平处理
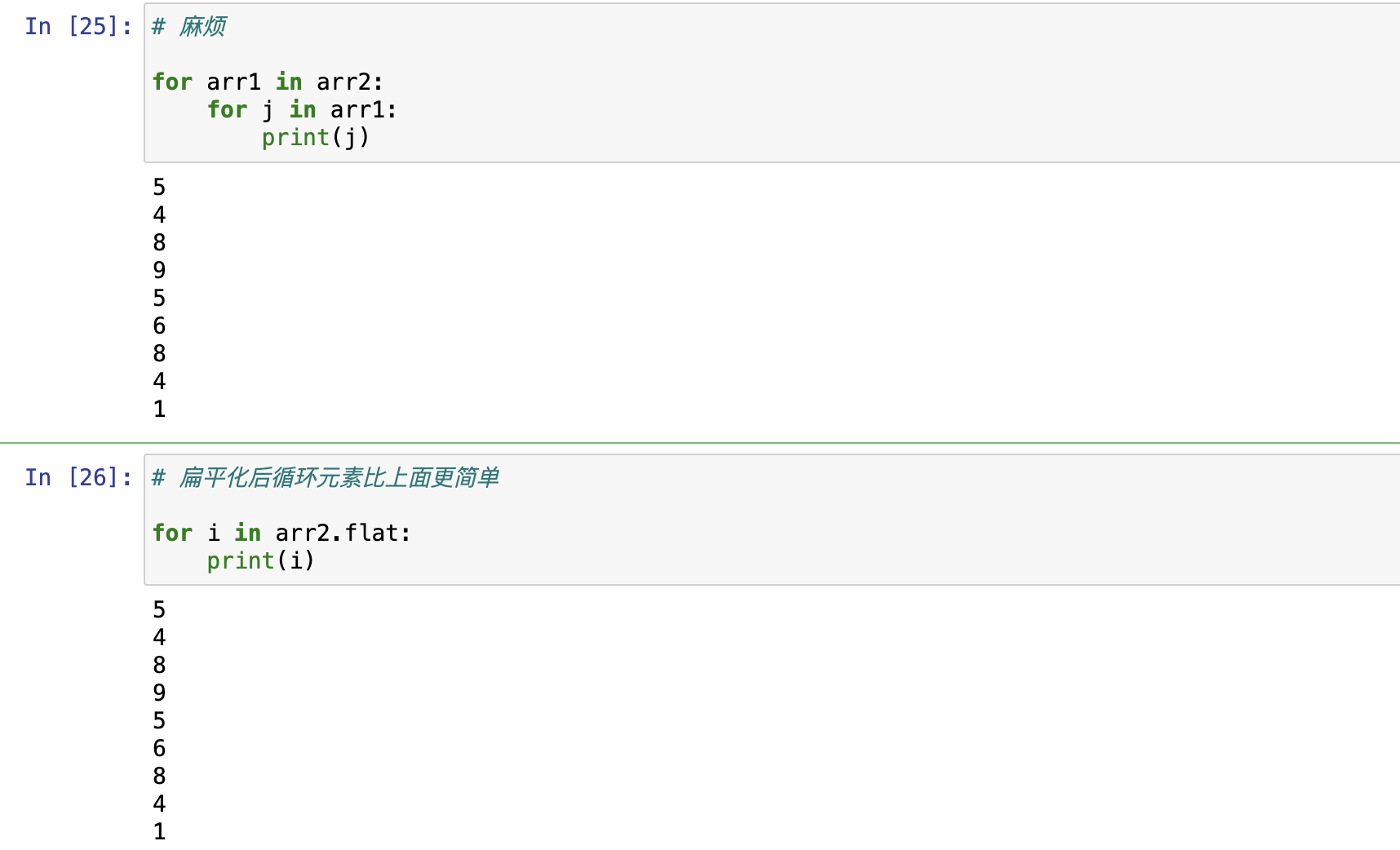
numpy.ndarray.flatten() 返回一份展开的数组拷贝,对拷贝所做的修改,不会影响原始数组
numpy.ravel() 展平的数组元素,返回一个展开的数组引用,修改,会影响原始数组。

数组翻转
numpy.transpose 对换数组的维度
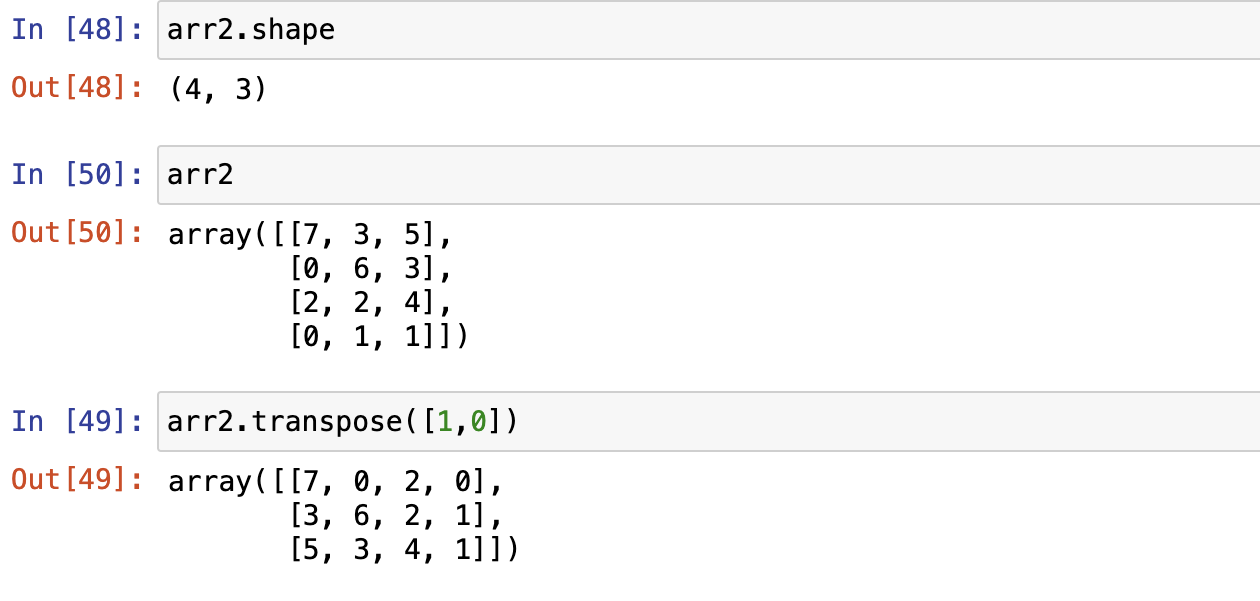
Numpy 数学函数
三角函数
np.sin(), np.cos(), np.tan()
接收的参数是弧度(np.pi),不是角度
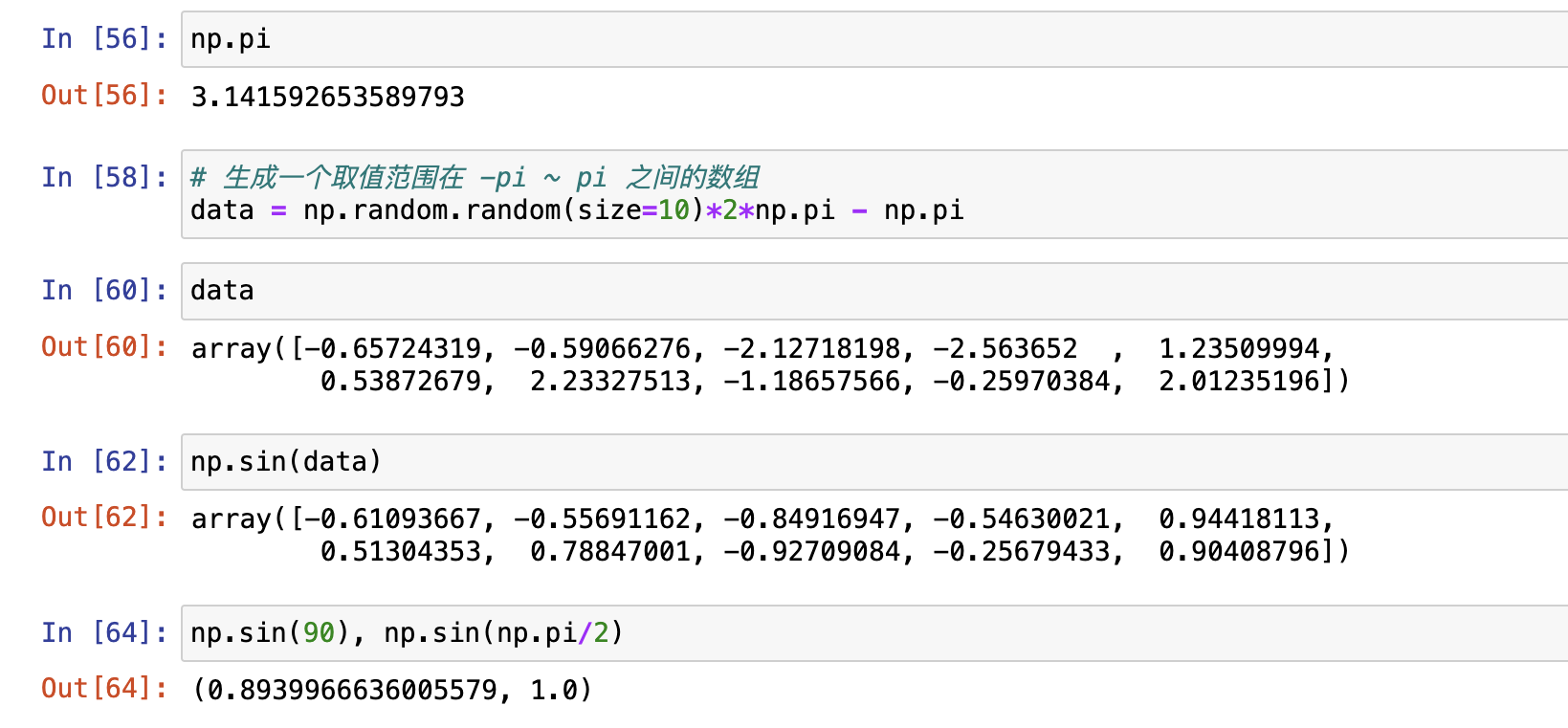
舍入函数
numpy.around()
- a: 数组
- decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置

算数函数
加减乘除: add(),subtract(),multiply() 和 divide()
numpy.power() 幂运算,可以做开方运算
numpy.mode() 求余运算
np.log() 自然底数的对数 np.log2(), np.log10()
Numpy 查找和排序
查找极值对应的索引
- numpy.argmax() 和 numpy.argmin()

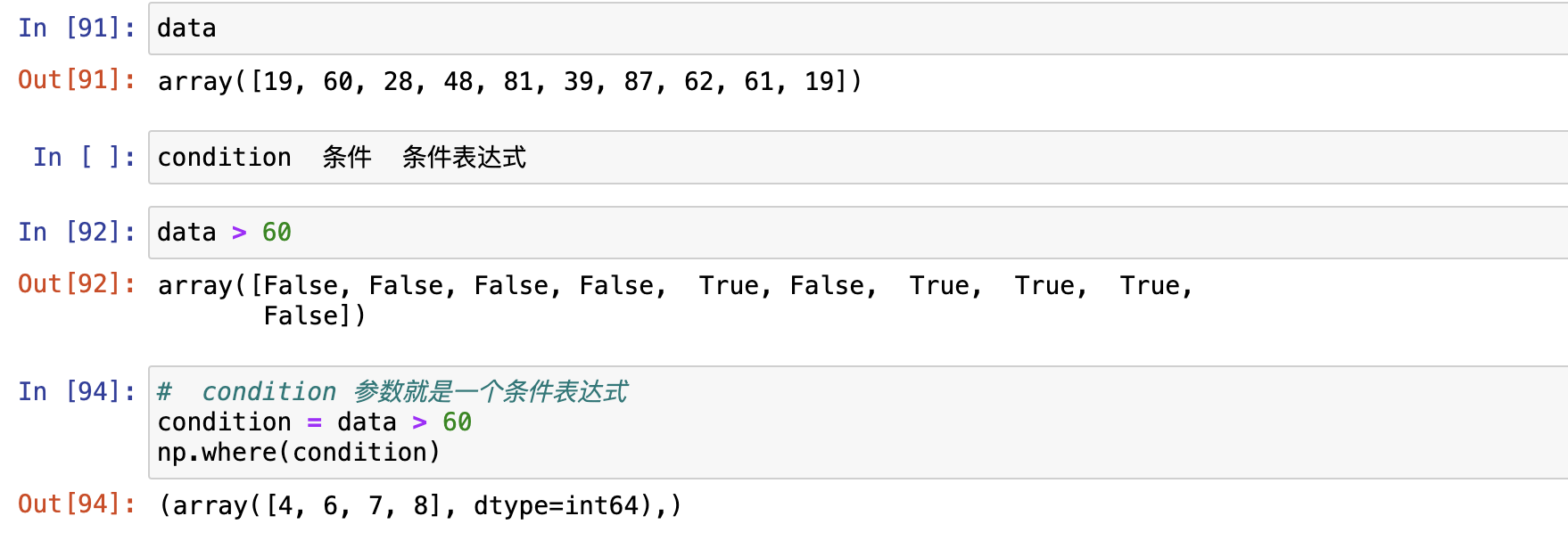
条件查找
numpy.where() 函数返回输入数组中满足给定条件的元素的索引
快速排序
np.sort()与ndarray.sort()都可以,但有区别:
- np.sort()不改变输入
- ndarray.sort()本地处理,不占用空间,但改变输入
numpy.sort() 函数返回输入数组的排序副本

索引排序
几乎不用,了解即可,panda有更好的方法。
numpy.argsort() 函数返回的是数组值从小到大的索引值。

部分排序
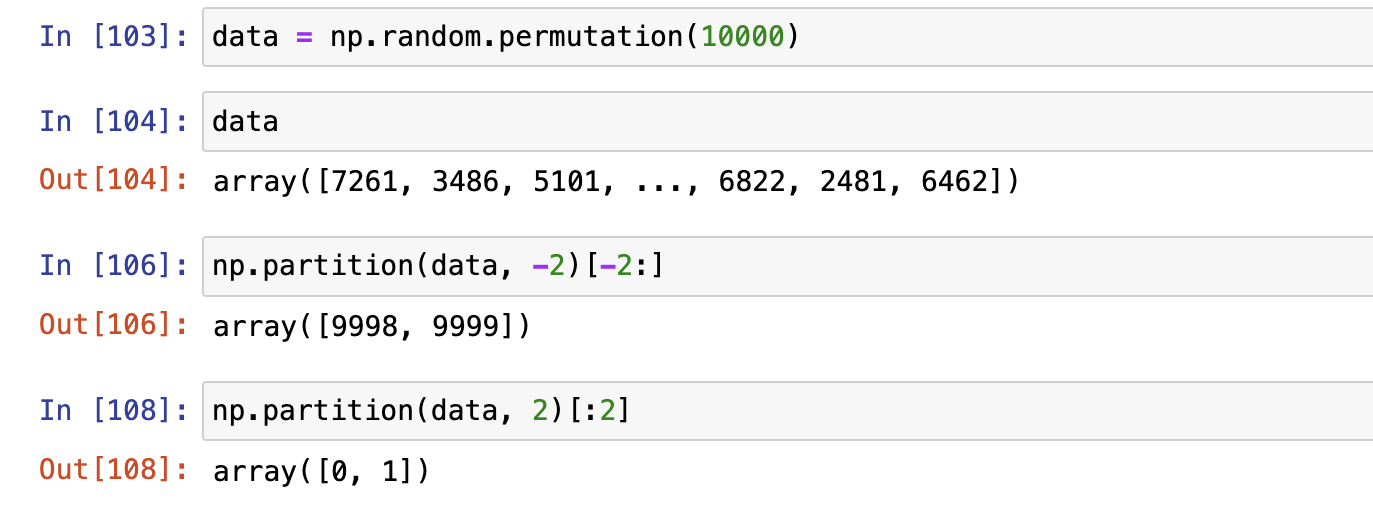
np.partition(a,k)
有的时候我们不是对全部数据感兴趣,我们可能只对最小或最大的一部分感兴趣。
- 当k为正时,我们想要得到最小的k个数
- 当k为负时,我们想要得到最大的k个数