各种符号
通配符
(通配符是用来找文件,根据文件名找文件的时候,使用该符号)
/opt/myfirst.txt
1. 文件有名字,可以用于找到该文件=============通配符
2. 文件有内有数据,内部的一堆字符串==============正则表达式- 当你在查找特定文件名,却不记得如何拼写时,通配符是帮你寻找的神器。
- 通配符,是专门用于处理文件名的特殊字符,而不是文件内容!
- 可以方便查找类似、但是不相同的文件名。
- 通配符是shell的内置语法、大部分linux命令都认识通配符
通配符语法
假设要找到如下的文件名
/opt/myfirst.txt| 字符 | 说明 | 示例 |
|---|---|---|
| * | 匹配任意字符数。 您可以在字符串中使用星号 (*****)。 | ls /opt/my*.txt |
| ? | 在特定位置中匹配单个字母。 | ls /opt/myfis?.txt |
| [ ] | 匹配方括号中的字符。[abd],[a-z] | ls /opt/myfirs[a-z].txt |
| ! | 在方括号中排除字符 [!abcd] [!a-z] | ls myfirs[!a-g].txt |
| - | 匹配一个范围内的字符。 记住以升序指定字符(A 到 Z,而不是 Z 到 A)。 | [a-z] 小写的a一直到z的序列 [A-Z] [0-9a-zA-Z] |
| ^ | 同感叹号、在方括号中排除字符,用法和感叹号一样 | ls [^a-c]yfirst.txt |
测试数据
mkdir /test ;cd /test
touch yuchao.txt yuc.txt cc.txt yuchao01.log yuyu.log cc.sh*匹配任意字符
cd /test/
#找出所有txt结尾的文件
#找出以y开头的txt文件
#找出以y开头t结尾的文件 ?
#查看以.sh结尾的shell脚本文件
#找出机器上所有的以y开头且是sh脚本的文件
# 找出机器上 所有的sh文件,且文件名是?以小写字母开头的sh文件
# 找出机器上,所有的以数字开头的sh文件
# 找出机器上,大写字母或是数字开头的sh文件
# 这个意思是?找出机器上的单个字符的sh文件,文件名是大写字母或是数字的
#查看以yu开头、txt结尾的文件
#查看以yu开头、log结尾的文件
#查看所有以yu开头的文件
#找出以c开头的文件
#找出文件名包含了chao的文件ls find
cd /test/
#找出所有txt结尾的文件
ls *.txt
#找出以y开头的txt文件
ls y*.txt
#找出以y开头t结尾的文件
ls y*t
#查看以.sh结尾的shell脚本文件
ls *.sh
#找出机器上所有的以y开头且是sh脚本的文件
find / -name 'y*.sh'
# 找出机器上 所有的sh文件,且文件名是?以小写字母开头的sh文件
find / -name '[a-z]*.sh'
# 找出机器上,所有的以数字开头的sh文件
find / -name '[0-9]*.sh'
# 找出机器上,大写字母或是数字开头的sh文件
find / -name '[A-Z0-9].sh'
# 这个意思是?找出机器上的单个字符的sh文件,文件名是大写字母或是数字的
find / -name '[A-Z0-9].sh'
#查看以yu开头、txt结尾的文件
ls yu*.txt
#查看以yu开头、log结尾的文件
ls yu*.log
#查看所有以yu开头的文件
ls yu*
#找出以c开头的文件
ls c*
#找出文件名包含了chao的文件
ls *chao*? ,匹配任意一个字符(用得少),相当于占位符,占1位
可以执行吗?
[yuchao-linux-242 root /test]#ls ?.sh
不能执行,找不就当的字符开头的.txt文件就不能执行
如何查找特定字符数量的文件?
找出所有sh脚本文件,必须用?符号
最方便的办法,不考虑前面文件名有多长
ls *.sh
必须用?去找sh文件
?.txt 所有当字符.txt
??.txt 所有2个字符.txt
找出当前目录下所有txt ,必须用?符号
先不用问号
ls *.txt
必须使用问号,不得有其他符号
[242-yuchao-class01 root /test]#ls ?.txt;ls ??.txt; ls ???.txt
0.txt h.txt H.txt &.txt
cc.txt
Q&a.txt yuc.txt
注意,不要去写 这样的符号,比较无聊
当然你得看懂这个写法
ls ?*.txt[] 匹配方括号里的内容
实测,[a-z] 找到a到z之间的所有字母,不区分大小写了
只能限定的使用[abc]或[ABC]
[242-yuchao-class01 root /test]#ls yu[abc].txt
yua.txt yub.txt yuc.txt
[242-yuchao-class01 root /test]#ls yu[ABC].txt
yuA.txt yuB.txt yuC.txt
具体你想还使用,匹配所有的大写,所有小写,使用unix风格的即可
ls [[:upper:]].log
ls [[:lower:]].log
找出以yu开头后续是单个小写字母的txt文件
ls yu[[:lower:]].txt
ls yu[[:upper:]].txt创建测试数据,如
[yuchao-linux-242 root /test]#touch {a..g}.log
[yuchao-linux-242 root /test]#ls
a.log b.log cc.sh cc.txt c.log c.sh d.log e.log f.log g.log yuchao01.log yuchao.txt yuc.txt yuyu.log
找出a-z之间任意一个字符的log
[242-yuchao-class01 root /test]#ls [a-z].log
a.log b.log c.log d.log e.log f.log g.log
或许是bash的问题
unix(posix) ,匹配大写字母[[:upper:]],小写字母 [[:lower:]]
ls [[:upper:]].log
ls [[:lower:]].log
↓
linux(centos), [A-Z] ,[a-z] ,表示[a-zA-Z]
通配符的写法,是有历史发展来源的
比如在unix时代
找出a-c之间任意一个字符的log
创建测试数据
[yuchao-linux-242 root /test]#touch yu{1..5}.log
[yuchao-linux-242 root /test]#touch yc{1..5}.log
[yuchao-linux-242 root /test]#touch y{1..5}.log
找出以yu1 yu2 yu3 相关的log文件
[242-yuchao-class01 root /test]#ls yu[123].log
yu1.log yu2.log yu3.log
[242-yuchao-class01 root /test]#ls yu[1-3].log
yu1.log yu2.log yu3.log
找出以y开头相关的log ,用中括号去找
[242-yuchao-class01 root /test]#ls y[0-9a-z].log
y1.log y2.log y3.log y4.log y5.log
[242-yuchao-class01 root /test]#
[242-yuchao-class01 root /test]#
[242-yuchao-class01 root /test]#ls y[a-z0-9][0-9a-z].log
yc1.log yc3.log yc5.log yu2.log yu4.log
yc2.log yc4.log yu1.log yu3.log yu5.log
只找出文件名是三个字符的log文件
ls [a-z0-9][a-z0-9][0-9a-z].log
找出系统中所有文件名是两个字符的txt文件
find / -name '??.txt'
仅仅是这一题
find / -name '[a-zA-Z0-9][a-zA-Z0-9].txt'[!字符区间] 取反方括号的内容
[cu] 匹配和c和u字符创建如下测试数据
[yuchao-linux-242 root /test]#ls
a.log cc.sh c.log d.log f.log yc1.log yc3.log yc5.log yu2.log yu4.log yuchao01.log yuc.txt
b.log cc.txt c.sh e.log g.log yc2.log yc4.log yu1.log yu3.log yu5.log yuchao.txt yuyu.log
找出除了以abcd开头的log文件,两种写法
ls [!abcd]*.log
找出除了abcd开头的单个字母的log文件
ls [!abcd].log
找出所有文件名包含了y和u字符的文件
只要文件名中有y和u字符的文件,就给列出来
ls *[yu]*
以y或u开头的文件
ls [yu]*
排除所有名字里包含y和u字符开头的文件,注意加上星号
ls [!yu]*
排除所有名字里包含y和u的sh文件
ls *[!yu]*.sh
找出任意除了y和u的单个字符的sh文件
ls [!yu].sh
找出任意除了y和u开头的sh文件
ls [!yu]*.shfind找文件与通配符
记好、通配符用于解决什么问题?
- 关于文件名的搜索
搜索/etc下所有包含hosts相关字符的文件
find /etc -name '*hosts*'
搜索/etc下的以ifcfg开头的文件(网卡配置文件)
ifcfg*
find /etc -name 'ifcfg*'
只查找以数字结尾的网卡配置文件(ifcfg开头的)
find /etc -name 'ifcfg*[0-9]'
找到系统中的第一块到第四块磁盘,注意磁盘的语法命名
/dev/sda sdb sdd sdc sde sdf
/dev/sda1
/dev/sda2
/dev/sda3
ls /dev/sd[abcd]
找找sdb硬盘有几个分区,请考虑到* ? [] 通配符
ls /dev/sdb
这个不对,不严谨
ls /dev/sdb*
等于找到
/dev/sdb
ls /dev/sdb1
ls /dev/sdb2
ls /dev/sdb3
正确的写法
[0-9]
ls /tmp/dev/sdb[0-9]
还有写法吗?问号
ls /tmp/dev/sdb?练习二
测试数据源准备
[yuchao-linux01 root ~/test_shell]$touch {a..h}.log
[yuchao-linux01 root ~/test_shell]$touch {1..10}.txt
[yuchao-linux01 root ~/test_shell]$ls
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt a.log b.log c.log d.log e.log f.log g.log h.log
[yuchao-linux01 root ~/test_shell]$
找出a到e的log文件
ls [a-e].log
找出除了3到5的txt文件
ls [!3-5].txt
ls [^3-5].txt
找出除了2,5,8,9的txt文件
两个写法
ls [!2589].txt
ls [!2,5,8,9].txt
尖角号一样和感叹号
[242-yuchao-class01 root ~]#ls [^2,5,8,9].txt
1.txt 3.txt 4.txt 6.txt 7.txt
[242-yuchao-class01 root ~]#ls [^2589].txt
1.txt 3.txt 4.txt 6.txt 7.txt
找出除了a,e,f的log文件
ls [!aef].log
ls [^aef].log
ls [^a,e,f].log特殊符号
什么是特殊符号
比起通配符来说,linux的特殊符号更加杂乱无章,但是一个专业的linux运维
孰能生巧,这些都不是问题路径相关
| 符号 | 作用 |
|---|---|
| ~ | 当前登录用户的家目录,对目录操作的命令,cd ,ls,touch,mkdir,find,cat |
| - | 上一次工作路径,仅仅是在shell命令行里的作用 |
| . | 当前工作路径,表示当前文件夹本身;或表示隐藏文件 .yuchao.linux |
| .. | 上一级目录 |
引号相关
引号意义,为什么要用引号
- 在于区分一个字符串的边界
- 因为linux识别,命令,参数,文件对象,中间是以空格区分的
- echo 'hello world'
'' 单引号、所见即所得,引号里的所有内容,原样输出
[242-yuchao-class01 root ~]#echo 'hello&*('
hello&*(
[242-yuchao-class01 root ~]#echo 'hello!!*('
hello!!*(
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo 'hello!!*($(pwd)'
hello!!*($(pwd)
"" 双引号、可以解析变量、及引用、linux命令
[242-yuchao-class01 root ~]#echo 'hello!!*($(pwd)' "现在时间是$(date)"
hello!!*($(pwd) 现在时间是Mon Apr 11 11:04:53 CST 2022
[242-yuchao-class01 root ~]#echo "现在时间是 $(date '+%F %T')"
现在时间是 2022-04-11 11:08:26
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo '现在时间是 $(date '+%F %T')'
现在时间是 $(date +%F %T)
[242-yuchao-class01 root ~]#name='吴彦祖'
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo "别人都喊我${name}"
别人都喊我吴彦祖
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#echo '别人都喊我${name}'
别人都喊我${name}
`` 反引号、可以解析命令
输出一段话
当前时间是:时间格式化
引号嵌套
[242-yuchao-class01 root ~]#echo "当前时间是:`date '+%F %T'`"
当前时间是:2022-04-11 11:11:23
作用同上
$(linux命令)
无引号,一般我们都省略了双引号去写linux命令,但是会有歧义,比如空格,建议写引号重定向符号
> stdout覆盖重定向
ls *.txt > all_txt.file
>> stdout追加重定向
ls *.txt >》 all_txt.file
< stdin重定向
数据流代号
0 stdin 数据输入,如键盘的输入,如文件数据的导入
1 stdout ,cat /etc/passwd
2 stderr , cat /etc/passwdddddddddddddddddddddd
2>&1 stderr重定向
把stderr当做stdout进行处理
[242-yuchao-class01 root ~]#ls /opt/ttttttttt > /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
[242-yuchao-class01 root ~]#
2>&1 stderr追加重定向
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#ls /opt/ttttttttt >> /tmp/opt.file 2>&1
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#cat /tmp/opt.file
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory
ls: cannot access /opt/ttttttttt: No such file or directory命令执行
command1 && command2 # command1成功后执行command2
编译安装软件
make && make install
例子,多个 && 多个命令成功后,向后执行
#ls && cd /opt && pwd
错误演示
[242-yuchao-class01 root ~]#lssss && cd /opt && pwd
-bash: lssss: command not found
[242-yuchao-class01 root ~]#ls && cd /optt && pwd
command1 || command2 # command1失败后执行command2
[242-yuchao-class01 root ~]#ls /optt || cd /opt || ls /tmp
ls: cannot access /optt: No such file or directory
[242-yuchao-class01 root /opt]#
command1 ; command2 # 无论command1成功还是失败、后执行command2
分号,执行多个linux命令
[242-yuchao-class01 root /opt]#cd /opt ; pwd ;cd ~;
/opt
\ # 转义特殊字符,还原字符原本含义
需要和双引号结合使用
[242-yuchao-class01 root ~]#touch "\$name的文件"
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#ls
$name的文件
$() # 执行小括号里的命令
[242-yuchao-class01 root ~]#echo "opt下的内容是$(ls /opt)"
opt下的内容是mm8888888.sh
M.sh
myfirst.txt
`` # 反引号,和$()作用一样
[242-yuchao-class01 root ~]#echo "opt下的内容是`ls /opt`"
opt下的内容是mm8888888.sh
M.sh
myfirst.txt
创建一个log文件,以当前时间命名
文件名是 "nginx_日期.log"
当你进行引号嵌套时,请你这样用,
最外层用双引号,内层用单引号
touch "nginx_`date '+%F#%T'`.log"
| # 管道符
管道符,是命令二多次加工处理
找出某进程
ps -ef|grep 进程名
{} # 生成序列
生成英文字母序列,数字序列,用于文件拷贝的文件名简写##引号练习
单引号
结论、单引号是所见即所得,单引号里面是什么,输入就是什么,没有任何改变,特殊符号也都失去了其他作用。
如下写法都不好使了
- 命令
- 变量
- 特殊符号
命令
touch 'nginx_$(date).log'
变量
名字是$age.log
touch '名字是$age.log'务必使用双引号,别用无引号
[242-yuchao-class01 root ~]#touch now_`date '+%F %T'`.log
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#ll
total 0
-rw-r--r-- 1 root root 0 Apr 11 11:56 11:56:20.log
-rw-r--r-- 1 root root 0 Apr 11 11:56 now_2022-04-11
[242-yuchao-class01 root ~]#
因此,在结合特殊命令时,请加上双引号,表示限定字符串区间
touch "now_`date '+%F %T'`.log"Linux时间格式化
date +"%Y-%m-%d %H:%M:%S" # +后面不能有空格,+前面要有空格
2024-03-19 15:14:43
echo $(date +"%Y-%m-%d %H:%M:%S")
2024-03-19 15:14:43
echo "现在时间是$(date '+ %Y-%m-%d %H:%M:%S')"
现在时间是2024-03-19 15:14:43反引号
反引号中的linux命令是可以执行的,且反引号中只能写可执行的linux命令
系统会首先执行反引号里的命令,然后再进行下一步的处理。
linux命令
- 时间查看
echo 的作用在于,在终端打印某些信息,常用在脚本执行的时候,告诉用户,脚本执行到了哪里
- 启动nginx
echo "正在启动nginx中:$(/usr/sbin/nginx)"
- 显示工作路径
echo "当前我再:`/usr/bin/pwd`"
- 创建文件夹
echo "正在创建文件夹 `mkdir /opt`"
变量解析
echo "变量name的值是:$name"证明,反引号,$() 都是优先执行命令,再执行其他普通命令
双引号
当输出双引号内的内容是,如果内容里有linux命令、或者变量、特殊转义符等
会优先解析变量、命令、转义字符,然后得到最终的内容
- 绝大多数场景,都会优先用双引号,因为能识别特殊符号,可以做很多事
linux命令执行(引号嵌套)
变量解析(引号嵌套)
- PATH查看
总结
在双引号中,是可以加载变量的解析,以及反引号,和$() 这样的命令解析的无引号
没有引号、很难确定字符串的边界,很容易出现各种故障
例如date "+%F %T"这样的命令特殊符号练习
重定向符号
; 分号
表示命令的结束,效果和下面这个一样
- bash
ls ; 多个命令之间的分隔符
- bash
ls ;cd ;pwd 某些配置文件的注释符,在文件数据中,表示注释符
常见的配置文件,注释符号(#居多)
符号
- 配置文件注释符号
- shell命令注释符号
| 管道符
如生活中的管道,能够传输物质
Linux管道符 | 用于传输数据,对linux命令的处理结果再次处理,直到得到最终结果
ps -ef|grep nginx&& 符
- 命令1 && 命令 2
# 安装nginx,且启动nginx
yum install nginx -y && systemctl start nginx|| 符
只有前面命令失败、才执行后面命令
# 用户创建
判断用户已经存在了,就删掉用户
useradd wenjie || userdel -f wenjie$() 符
执行linux命令
- 时间查看
- 创建文件以时间命名
- 搜索文件、删除文件
使用$(),找到当前目录下的文件,且删除
坑,文件名如果有问题,这个方法不适用
步骤1,删除文件, rm -f 文件名
步骤2 rm -f $(ls *.log)
- 启动、关闭、nginx{} 序列符
- 字母序列
- 数字序列
- 文件名简写
用在文件拷贝时
修改linux的dns文件,但是要提前备份 ,文件名加上.bak
[242-yuchao-class01 root ~]#cp /etc/resolv.conf /etc/resolv.conf.bak
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#ls /etc/resolv.conf*
/etc/resolv.conf /etc/resolv.conf.bak
这个写法,支持简写,再生成一个备份文件,叫做 .ori
[242-yuchao-class01 root ~]#cp /etc/resolv.conf{,.ori}- 变量分隔符
${name}
{a..z}
{A..Z}
{0..9}.jpg正则
关于学习正则
正则表达式这个知识点的学习,在于先学习正则符号的意义,以及如何使用正则提取你需要的数据。 它不像linux的命令,有一些固定的含义,也不像服务搭建,有固定的流程。 因此你要做的就是把这些正则练习题,不看答案的情况下,能写出来;以及自己独立思考出来另外的办法,一种、甚至多种办法,解决同一个问题,都是可以的。
正则表达式,数据处理的人去用,数据分析的,爬虫工程师 前端、后端开发,对各种数据提取,构造 运维人员 提取文件数据的关键信息,做分析 日志分析,提取网站的链接 http://www.taobao.com https://www.jd.com http://yuchaoit.cnps -ef | grep 'nginx'
以及在学完正则后、结合sed、awk、grep三剑客命令,去记忆一些通用的用法,解决常见的运维需求,例如对日志信息提取,等,这个我们学完后再统一正则。
正则表达式的知识体系,是足够写一整本书的知识点,所以你在短短一两天内想快速掌握,必然是个辛苦活,所以先听课,再完成作业,加上后期的不断学习,不断练习,也就自然熟能生巧,掌握常见正则用法了。
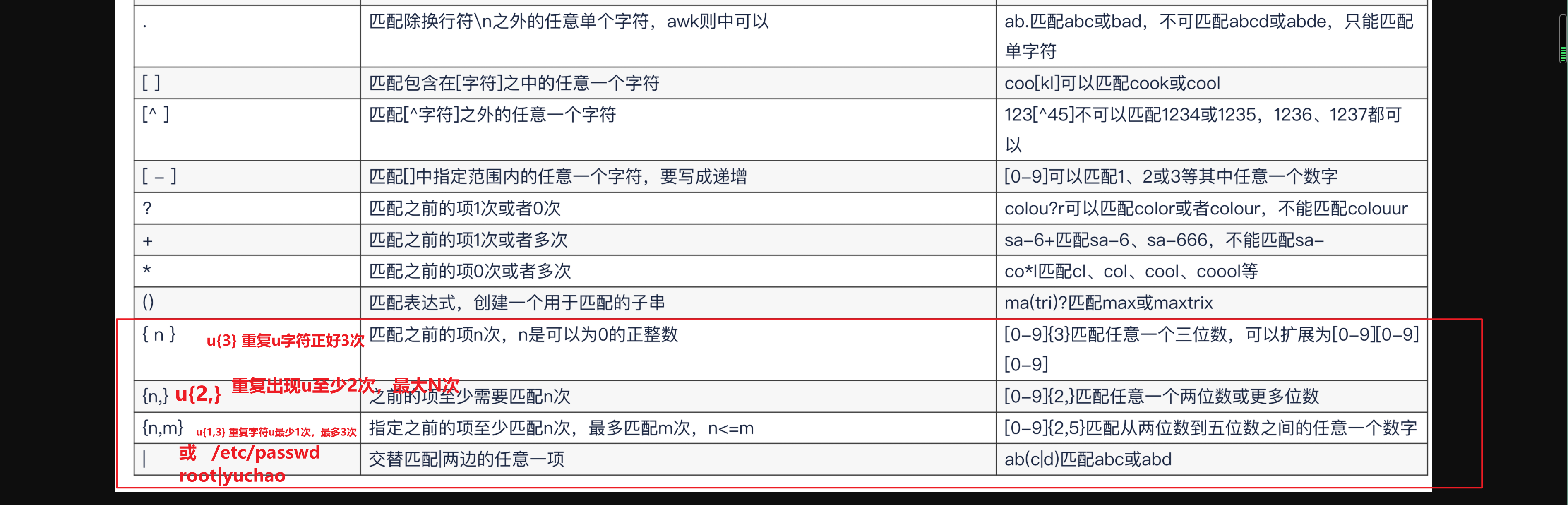
基础语法
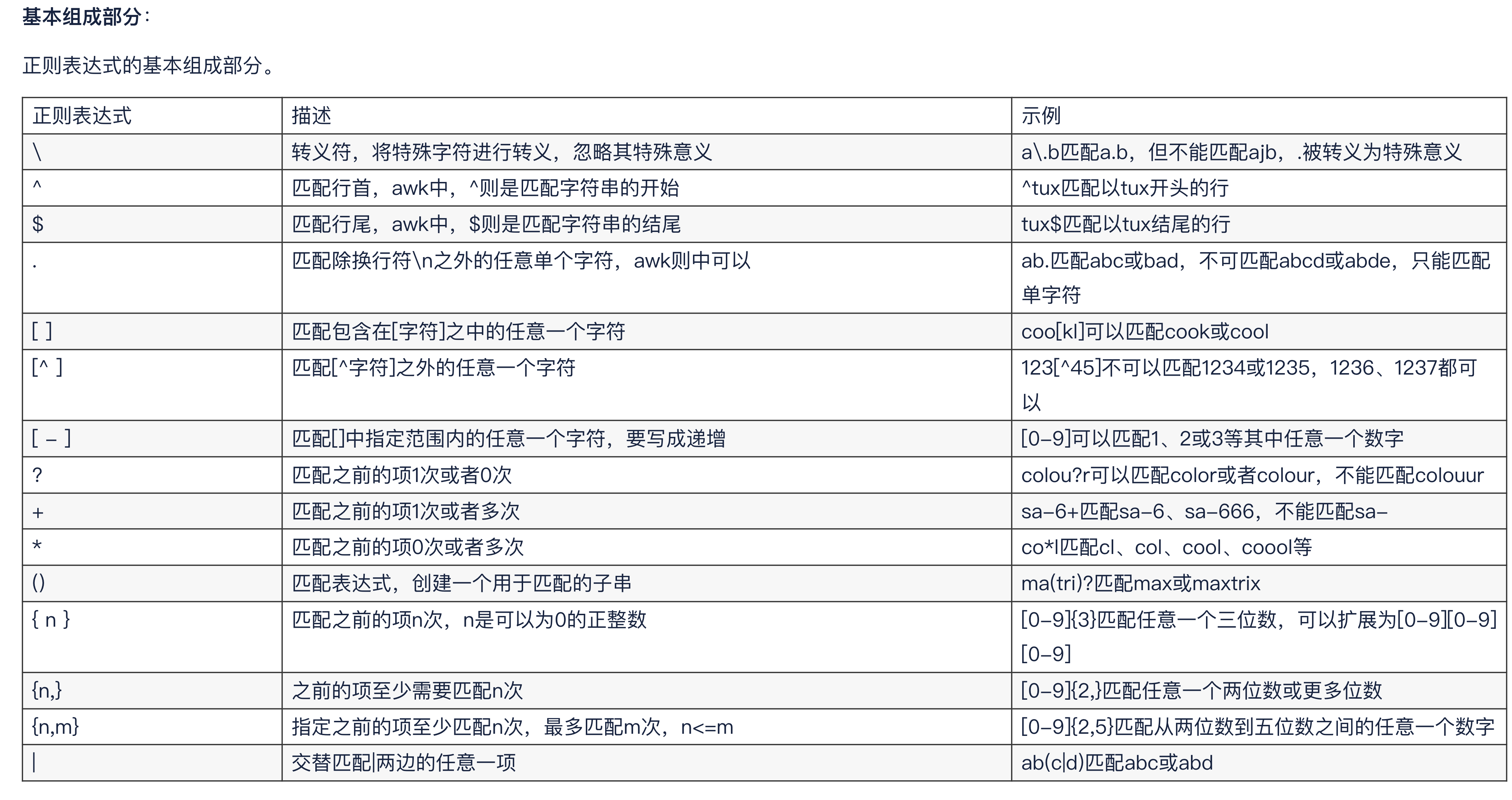
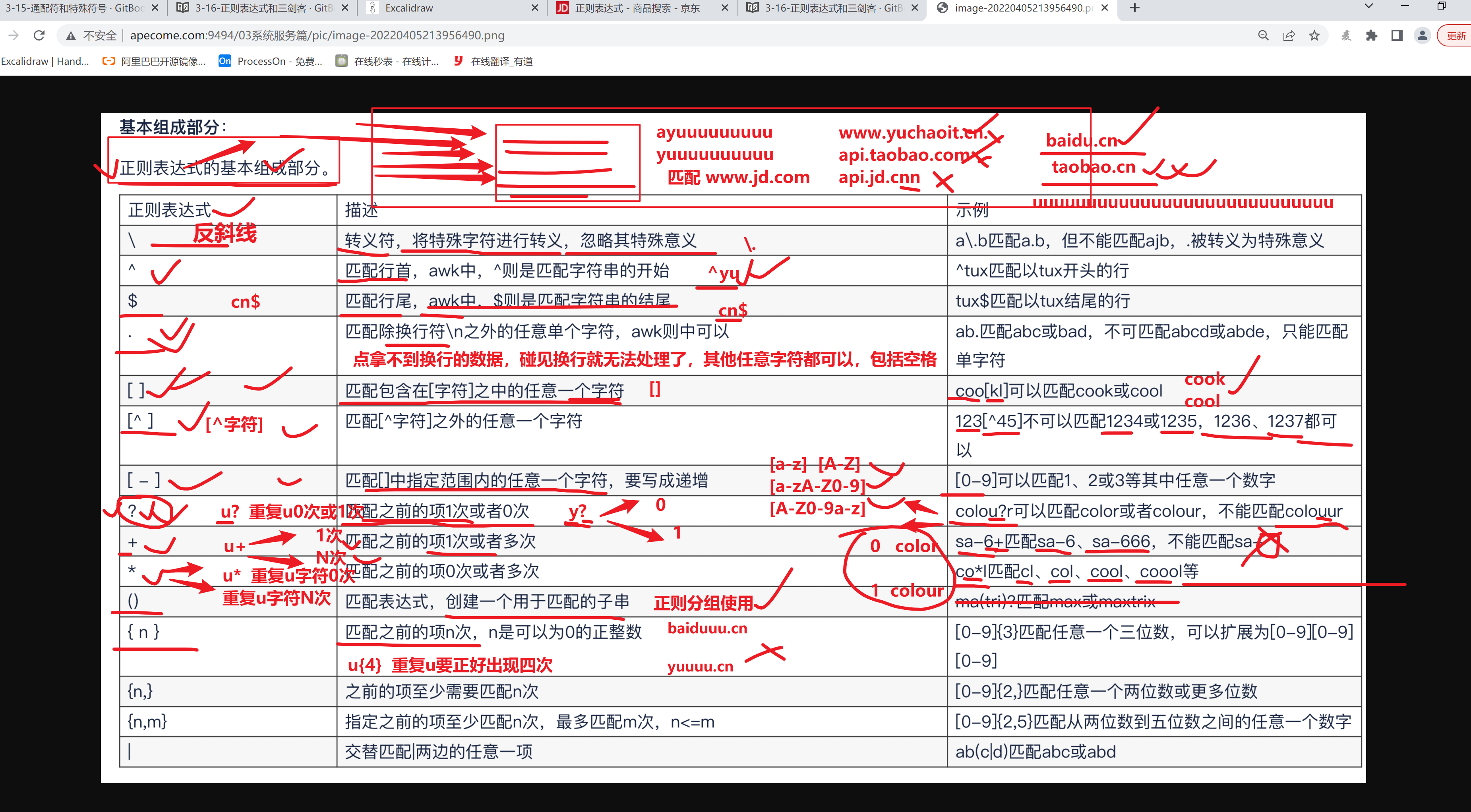
--
什么是正则表达式
- 正则表达式就是为了
处理大量的字符串而定义的一套规则和方法。 - 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤(grep),替换(sed)或输出(awk)需要的字符串。
- Linux 正则表达式一般以行为单位处理文件数据的,文件数据
wwwwwwwwwwwww
eeeeeeeeeeee
qweqweqweqwe
234134r1234r34t243t
linux的换行符 \n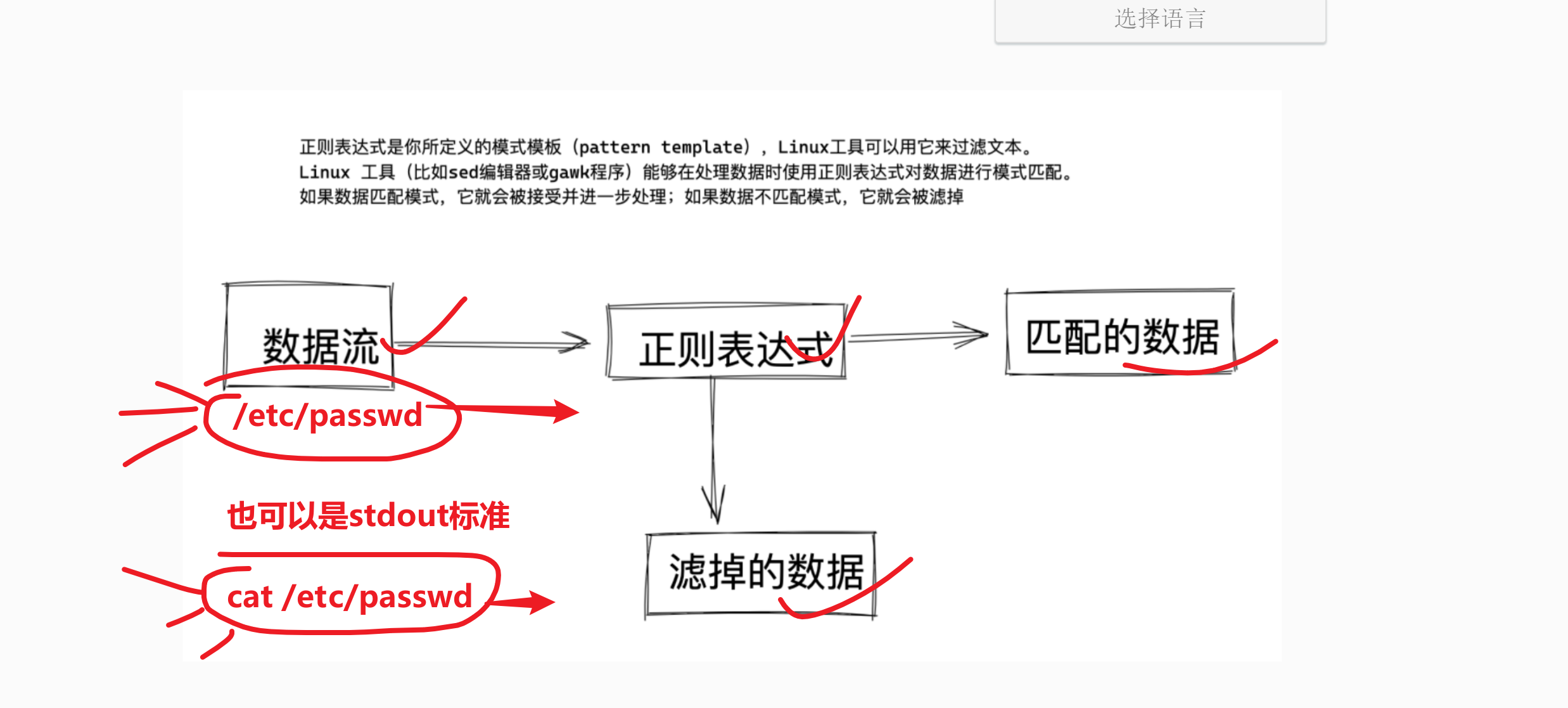
如何用正则表达式
通常Linux运维工作,都是面临大量带有字符串的内容,如
- 配置文件
- 程序代码
- 命令输出结果
- 日志文件
且此类字符串内容,我们常会有特定的需要,查找出符合工作需要的特定的字符串,因此正则表达式就出现了
- 正则表达式是一套规则和方法
- 正则工作时以单位进行,一次处理一行
- 正则表达式化繁为简,提高工作效率
- linux仅受三剑客(sed、awk、grep)支持,其他命令无法使用
学正则的注意事项
正则表达式应用非常广泛,很多编程语言都支持正则表达式,用于处理字符串提取数据。
- bash
java python golang javascripts sed awk grep Linux下普通命令无法使用正则表达式的,只能使用linux下的三个命令,结合正则表达式处理。
- sed
- grep
- awk
通配符是大部分普通命令都支持的,用于查找文件或目录
而正则表达式是通过三剑客命令在文件(数据流)中过滤内容的,注意区别
以及注意字符集,需要设置
LC_ALL=C,注意这一点很重要
关于字符集设置
你会发现很多shell脚本里都有这么一个语句如下
LC_ALL=C
这个变量赋值的动作,是等于还原linux系统的字符集
因为我们系统本身是支持多语言的
德文
英文
中文
每一个语言都有其特有的语言,字符,计算机为了统一字符,生成了编码表
比如你平时喜欢让linux支持中文,如果你的系统编码是中文,很可能导致你的正则出错,因此要还原系统的编码
LANG='zh_CN.UTF-8'
执行一个还原本地所有编码信息的变量
LC_ALL=C
用法如下
[242-yuchao-class01 root ~]#export LC_ALL=C作用是修改linux的字符集,通过locale命令可以查看本地字符集设置
linux通过如下变量设置程序运行的不同语言环境,如中文、英文环境。
[root@yuchao-tx-server ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=zh_CN.UTF-8一般我们会使用$LANG变量来设置linux的字符集,一般设置为我们所在的地区,如zh_CN.UTF-8
[root@yuchao-tx-server ~]# echo $LANG
en_US.UTF-8为了让系统能正确执行shell语句(由于自定义修改的不同语言环境,对一些特殊符号的处理区别,如中文输入法,英文输入法下的标点符号等,导致shell无法执行)
我们会使用如下语句,恢复linux的所有的本地化设置,恢复系统到初始化的语言环境。
[root@yuchao-tx-server ~]# export LC_ALL=C通配符和正则的区别
1.从语法上就记住,只有awk、gred、sed才识别正则表达式符号、其他都是通配符
只有用这3个命令的操作,你写下的特殊符号,才是正则表达式---提取数据流的关键信息
其他linux命令的操作,都是通配符的概念,以及------查找文件名2.从用法上区分
- 表达式操作的是文件、目录名(属于是通配符)
- 表达式操作的是文件内容(正则表达式)
3.比如如下符号区别
通配符和正则表达式 都有 * ? [abcd] 符号
通配符中,都是用来标识任意的字符
如 ls *.log,可以找到a.log b.log ccc.log
正则中,都是用来表示这些符号前面的字符,出现的次数,如
grep 'a*'实际案例
通配符,一般用于对文件名的处理,查找文件
如ls命令结合*
意思是匹配任意字符
[root@yuchao-tx-server test]# ls *.log
1.log 2.log 3.log 4.log 5.log
而三剑客,结合*符号,是处理文件内容,如grep
此时的*作用就不一样了通配符,一般用于对文件名的处理,查找文件
如ls命令结合*
意思是匹配任意字符
[root@yuchao-tx-server test]# ls *.log
1.log 2.log 3.log 4.log 5.log
而三剑客,结合*符号,是处理文件内容,如grep
此时的*作用就不一样了正则表达式分类
使用正则表达式的问题是、有两大类正则表达式规范、linux不同的应用程序,会使用不同的正则表达式。
例如
- 不同的编程语言使用正则(python,java)
- Linux实用工具(sed、awk、grep)
- 其他软件使用正则(mysql、nginx)
正则表达式是通过正则表达式引擎(regular expression engine)实现的。正则表达式引擎是 一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
在Linux中,有两种流行的正则表达式引擎:
基于unix标准下的正则表达式符号规则有两类:
POSIX基础正则表达式(basic regular expression,BRE)引擎
比较常见,简单的,早期unix系统中就存在的一些符号
POSIX扩展正则表达式(extended regular expression,ERE)引擎
又额外的出现了一堆特殊字符,叫做扩展正则表达式
解释posix
POSIX(Portable Operating System Interface)是Unix系统的一个设计标准。
当年最早的Unix,源代码流传出去了,加上早期的Unix不够完善,于是之后出现了好些独立开发的与Unix基本兼容但又不完全兼容的OS,通称Unix-like OS两类、正则表达式符号
为什么强调这个事
因为grep
awk
sed
在处理正则时,默认也只认识 基础正则表达式
如果你写了分区,或者,这样的符号,必须给grep,加上额外的参数,让它识别这些扩展正则linux规范将正则表达式分为了两种
- 基本正则表达式(BRE、basic regular expression)
BRE对应元字符有
^ $ . [ ] *
其他符号是普通字符
; \- 扩展正则表达式(ERE、extended regular expression)
ERE在在BRE基础上,增加了
( ) { } ? + | 等元字符- 转义符
反斜杠 \
反斜杠用于在元字符前添加,使其成为普通字符基本正则表达式(BRE)
测试文本数据
[242-yuchao-class01 root ~]#cat -n t1.log
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
Good good study , day day up!
my name is wu yan zu .关于单引号、双引号
- 没使用变量的话,请你都用单引号
grep与正则
接下来会以,过滤,查找文件内容,也就是结合grep来学习正则表达式NAME
grep, egrep, fgrep - print lines matching a pattern
SYNOPSIS
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]例如传入的pattern(模式是) ,我们可以统称你写的正则是模式
grep '关键字,模式,正则表达式' 数据流^m,以m开头的行
[242-yuchao-class01 root ~]#grep '^m' t1.log
my name is wu yan zu .
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
-n 显示行号
[242-yuchao-class01 root ~]#grep '^m' t1.log -n
13:my name is wu yan zu .
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
-o 只显示grep找出来的结果,而不是那一行所有的信息
[242-yuchao-class01 root ~]#grep '^m' t1.log -n -o
13:m^ 尖角符
语法
写于最左侧,如
^yu 逐行匹配,找到以yu开头的内容结合grep用法,-i 忽略大小写,可以找到更多的数据匹配
找出以yu开头的行
grep '^yu' t1.log -i
找出以m开头的行,且显示行号
[242-yuchao-class01 root ~]#grep '^m' t1.log -i -n
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
13:my name is wu yan zu .
找出m或M开头的行
[242-yuchao-class01 root ~]#grep '^m' t1.log -i -n
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
13:my name is wu yan zu .只显示grep每次匹配到的结果,而不是匹配到的文本行数据
找出以my开头的行
[242-yuchao-class01 root ~]#grep '^my' t1.log -i -n -o
[242-yuchao-class01 root ~]#grep '^my' t1.log -i -n -o
6:My
8:My
13:my
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '^my' t1.log -i -n
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
13:my name is wu yan zu .
匹配出qq那一行
[242-yuchao-class01 root ~]#grep 'qq' t1.log
My qq num is 877348180匹配行内容,且显示行号
找出包含i字符的行
[242-yuchao-class01 root ~]#grep 'i' t1.log
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my name is wu yan zu .
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep 'i' t1.log -n -o
2:i
4:i
4:i
6:i
6:i
6:i
7:i
7:i
8:i
13:i
找出以i开头的行
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '^i' t1.log
[242-yuchao-class01 root ~]#grep '^i' t1.log -i
I am teacher yuchao.
I teach linux,python!
I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
找出以i开头的行,且只显示匹配内容
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '^i' t1.log
[242-yuchao-class01 root ~]#grep '^i' t1.log -i
I am teacher yuchao.
I teach linux,python!
I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -n -o
1:I
2:I
4:I$ 美元符
语法
word$ 匹配以word结尾的行匹配所有以字符n结尾的行
[242-yuchao-class01 root ~]#grep 'n$' t1.log -n
6:My website is http://yuchaoit.cn
匹配所有以.结尾的行
[242-yuchao-class01 root ~]#grep '\.$' t1.log -n
1:I am teacher yuchao.
13:my name is wu yan zu .11.05
单、双引号区别
单引号、所见即所得,可以用于匹配如标点符号,还原其本义。
双引号、能够识别linux的特殊符号、或变量,需要借助转义符还原字符本义。
当需要引号嵌套时,一般做法是,双引号,嵌套单引号。
^$ 匹配空行
^字符
匹配以这个字符开头的行
字符$
匹配以这个字符结尾的行
^$
以空开头,空结尾===空行找出文件的空行
[242-yuchao-class01 root ~]#grep '^$' t1.log -n
3:
5:
9:
11:
12:. 点符
. 匹配除了换行符以外所有的内容、字符+空格,除了换行符。
. 点处理空格
.可以匹配到空格,以及任意字符以及拿不到空行
但是点,不匹配换行符。(拿不到换行符,什么意思?)
测试数据
cat -n t1.log
y
u
c
h
a o验证点和换行、空格的关系
[242-yuchao-class01 root ~]#grep '.' t2.log -on
1:y
2:u
3:c
4:h
6:a
6:
6:o. 匹配除换行符的所有字符
[242-yuchao-class01 root ~]#grep '.' t1.log -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
6:My website is http://yuchaoit.cn
7:Our school site is https://apecome.com
8:My qq num is 877348180
10:Good good study , day day up!
13:my name is wu yan zu .. 代表任意一个字符
如
y.
y..
[242-yuchao-class01 root ~]#grep 'y.' t1.log
I am teacher yuchao.
I teach linux,python!
My website is http://yuchaoit.cn
My qq num is 877348180
Good good study , day day up!
my name is wu yan zu .
练习,找出符合.ac正则的行
[242-yuchao-class01 root ~]#grep '.ac' t1.log -n
1:I am teacher yuchao.
2:I teach linux,python!
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '.ac' t1.log -no
1:eac
2:eac.$ 匹配任意字符结尾
. 任意一个字符
.$ 任意字符结尾
拿到每一行的结尾的符号
[242-yuchao-class01 root ~]#grep '.$' t1.log -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
6:My website is http://yuchaoit.cn
7:Our school site is https://apecome.com
8:My qq num is 877348180
10:Good good study , day day up!
13:my name is wu yan zu .拿到每一行的结尾字符
[242-yuchao-class01 root ~]#grep '.$' t1.log -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
6:My website is http://yuchaoit.cn
7:Our school site is https://apecome.com
8:My qq num is 877348180
10:Good good study , day day up!
13:my name is wu yan zu .. 和转义符
只想拿到每一行结尾的普通小数点 .,需要对点转义
grep '\.$' t1.log\ 转义符
转义字符,让有特殊意义的字符,现出原形,还原其本义。
\.
\$
转义符空格、换行、tab
使用该网址,验证换行符https://deerchao.cn/tools/wegester/使用这个网址来测试换行符的匹配
换行符、制表符
\b 匹配单词边界,如我想从字符串中“This is Regex”匹配单独的单词 “is” 正则就要写成 “\bis\b”
hello world
helloworld
\n 匹配换行符 ,表示newline,向下移动一行,不会左右移动
\r 匹配回车符,表示return,回到当前行的最左边
在windows中,换行符号是 \r\n
linux中,换行符就是\n
linux中输入 enter键,表示\r \n
linux换行符是\n,表示\r+\n 换行且回车,换行且回到下一行的行首
windows换行符是\r\n,表示回车+换行
\t 匹配一个横向的制表符,等于tab键* 星号
重复前一个字符0此或n次
[242-yuchao-class01 root ~]#grep 'w*' t1.log
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
Good good study , day day up!
my name is wu yan zu .
my name is wwwwwwwwwwwwwwwwwwwwwwwwu yifan.
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep 'w*' t1.log -no
6:w
13:w
15:wwwwwwwwwwwwwwwwwwwwwwww.* 符(占位占多位)
. 匹配任意一个字符
* 重复前一个字符0或N次
.* 找出任意内,[这一行有东西,没东西,]全给找出来,是*的作用
对比 . 和.*就理解了
只找出有字符的行
grep '.' t1.log
无论有无字符,都找出来这行
grep '.*' t1.log图解点 . 不匹配换行
首先,不匹配换行这事,是因为 . 的作用
.* 是重复前面这个字符0次或N次再次记住,.不处理换行的
通过如下命令证明
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '.*' t1.log
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
Good good study , day day up!
my name is wu yan zu .
my name is wwwwwwwwwwwwwwwwwwwwwwwwu yifan.
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep 'teach.*python' t1.log
I teach linux,python!
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep 'teach.*english' t1.log
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#例如关于多行数据
i love you
i hate you
love.*hate 这样的正则是不可用的,拿不到的数据的.*?(占多位)
.*:贪婪匹配,占多位
/*?:非贪婪匹配,占多位
#测试数据
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
I am glad to see you, god,you are a good god!^.*符号
^m 以m开头
.* 任意内容
^.* 以任意内容开头语法
^.* 表示以任意多个字符开头的行
只找出以i开头的行
[242-yuchao-class01 root ~]#grep '^i' t1.log -i
I am teacher yuchao.
I teach linux,python!
I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -o
I
I
I
找出任意以字母i开头,以及匹配到后续所有数据
[242-yuchao-class01 root ~]#grep '^i.*' t1.log -i -o
I am teacher yuchao.
I teach linux,python!
I like english
找出任意以字母i开头的行,且以h结尾的行,且拿到其中所有数据
[242-yuchao-class01 root ~]#grep '^i.*h$' t1.log -i -o -n
4:I like english.*$ 符
以任意多个字符结尾的行
grep '.*$' t1.log
等于
grep '.*' t1.log尝试如下正则的意义
p.*$的作用
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep 'p.*$' -i -n t1.log
2:I teach linux,python!
6:My website is http://yuchaoit.cn
7:Our school site is https://apecome.com
10:Good good study , day day up!
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep 'p.*$' -i -n t1.log -o
2:python!
6:p://yuchaoit.cn
7:ps://apecome.com
10:p!###[ ] 中括号
中括号,有如下用法
####[abc]
[abc] 匹配括号内的小写a、b、c字符
[A-Z]提示,关于到大小写的精准匹配,就别添加忽略大小写参数了
[a-z]、 [A-Z] 、[a-zA-z]、[0-9]
[a-z] 匹配所有小写单个字母
[A-Z] 匹配所有单个大写字母
[a-zA-Z] 匹配所有的单个大小写字母
[0-9] 匹配所有单个数字
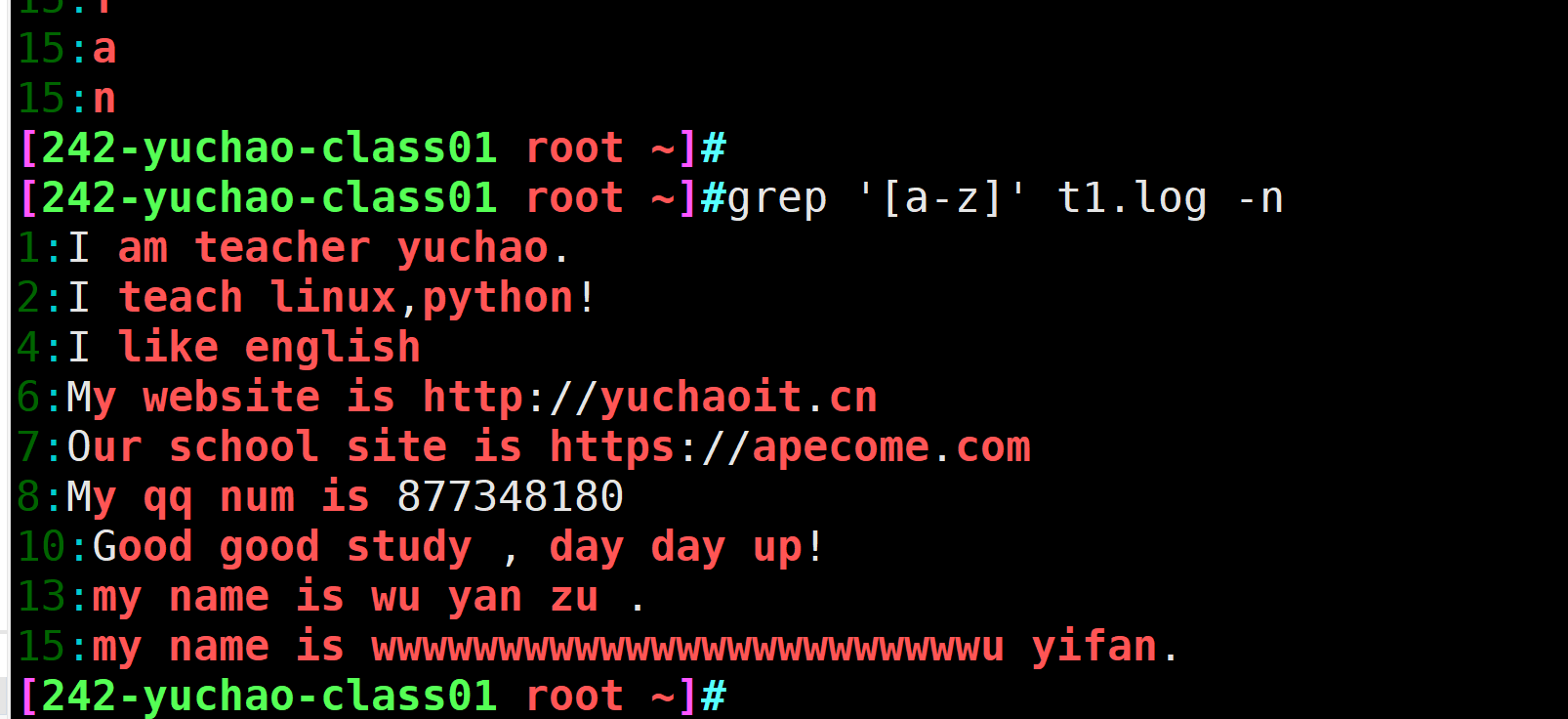
[a-zA-Z0-9] 匹配所有数字和字母[a-z] 匹配小写字母
等于找出文件中所有的小写字母
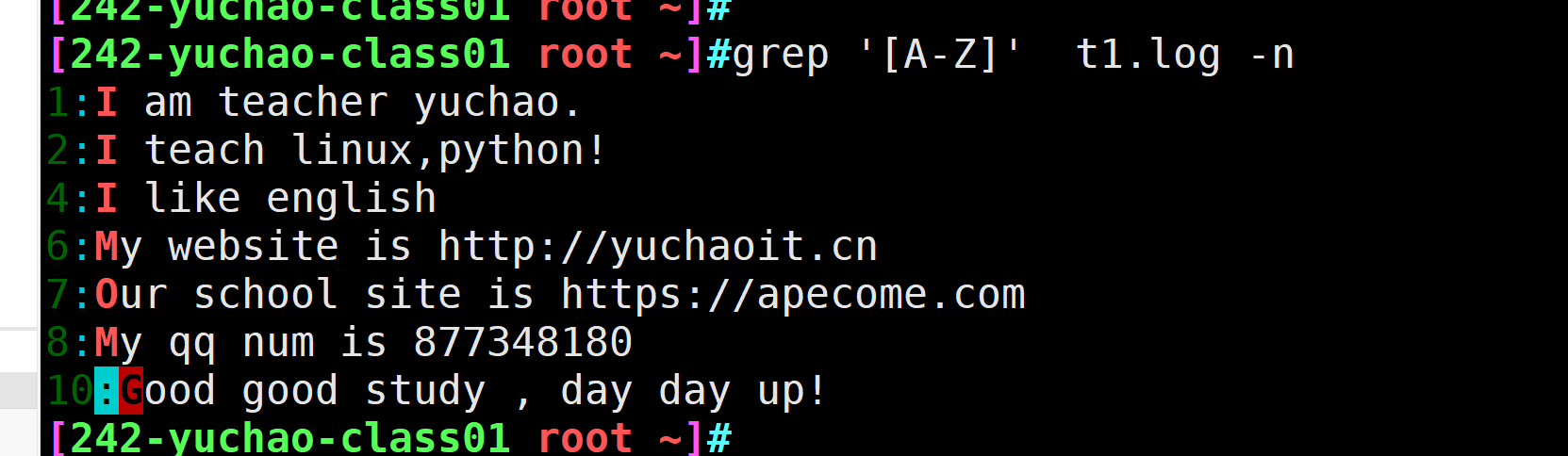
[A-Z] 匹配大写字母
[a-z0-9] 匹配小写字母和数字
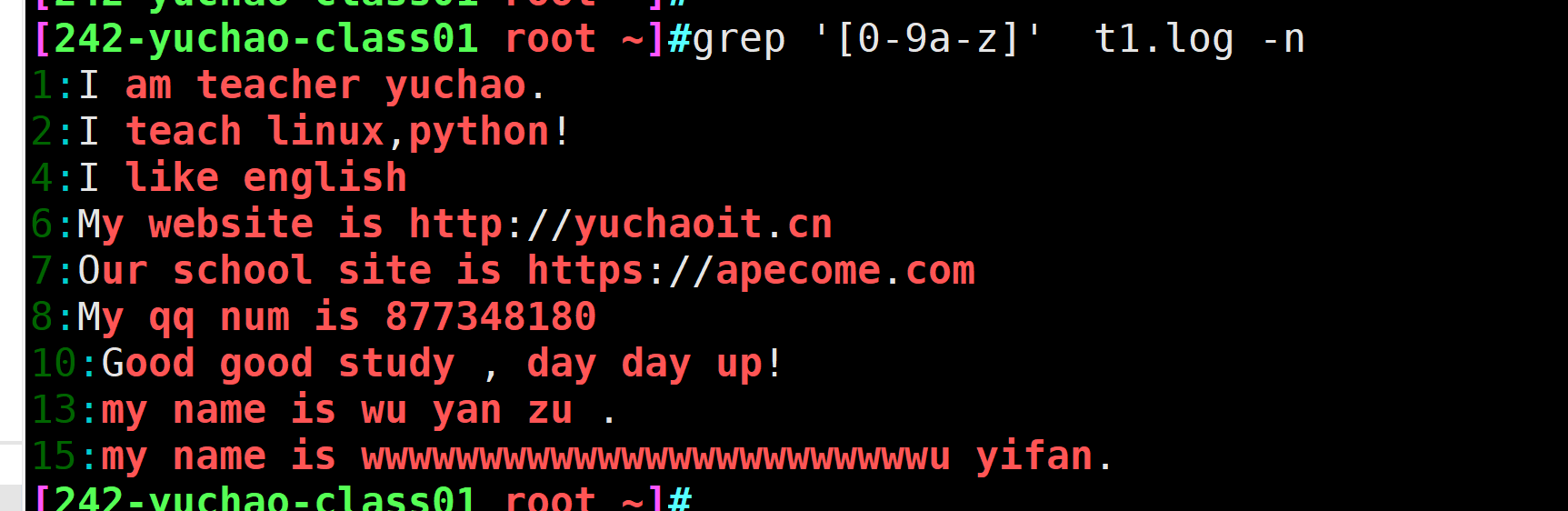
[0-9A-Z] 匹配大写字母和数字
grep '[0-9A-Z]' t1.log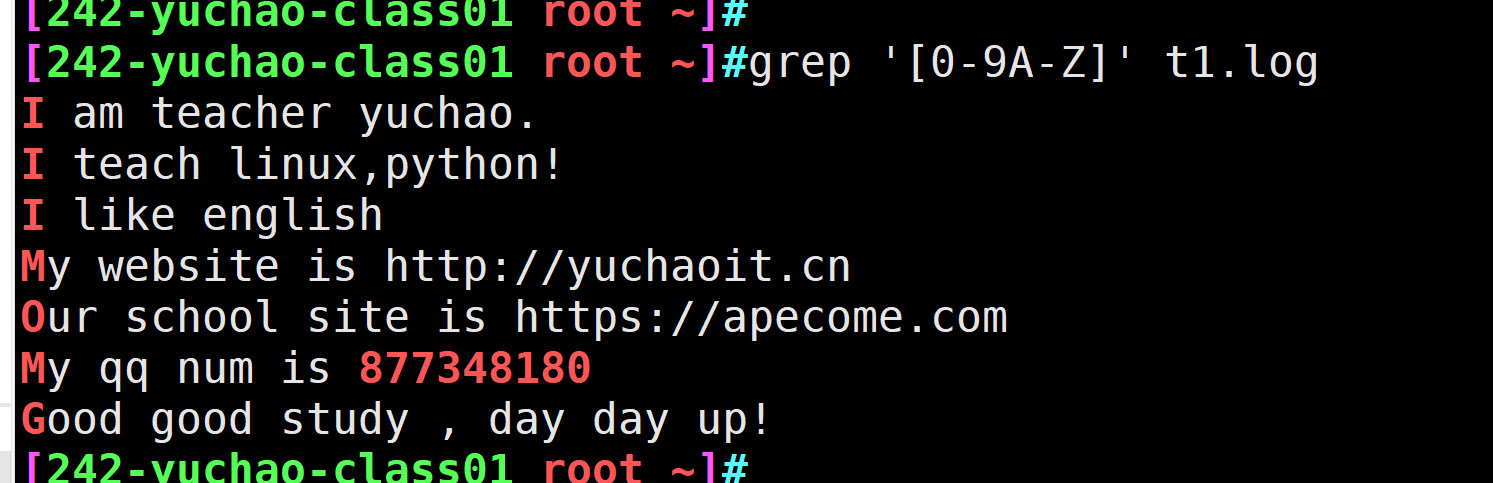
[a-z0-9A-Z] 匹配大写、小写字母、数字,没有空格,特殊符号
grep '[a-z0-9A-Z]' t1.log -n只想拿到特殊符号,对中括号里的字符进行取反即可
grep '[^a-z0-9A-Z]' t1.log -n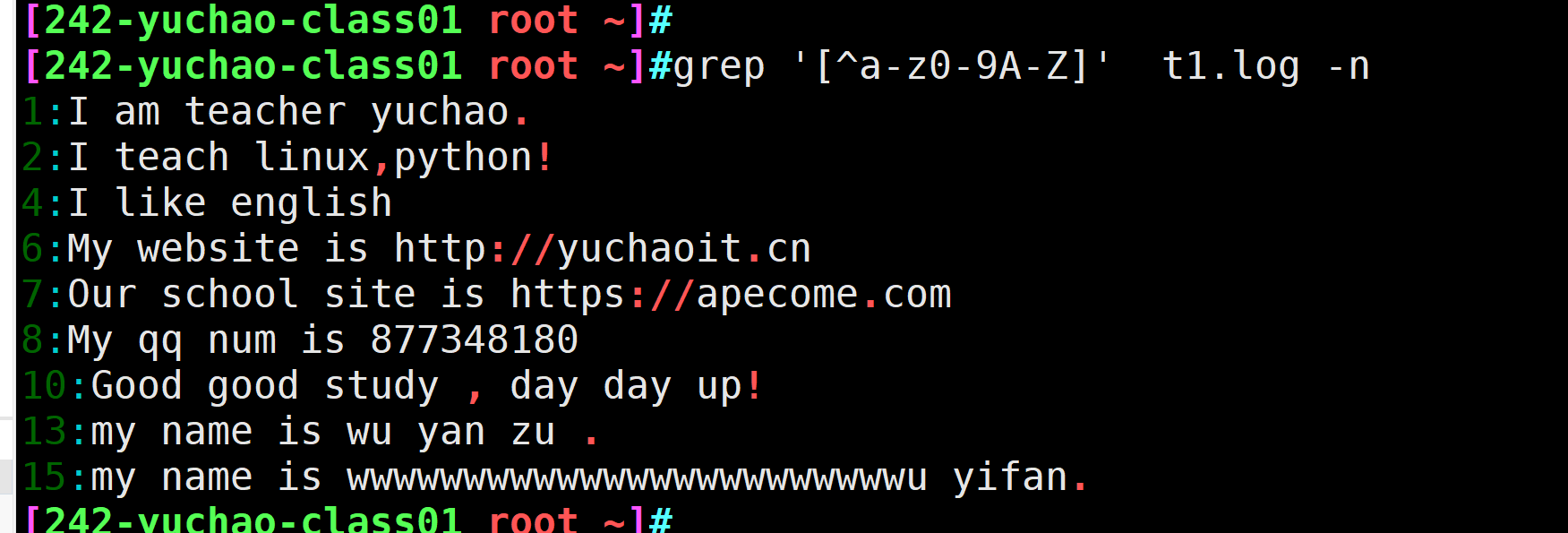
[^abc] 中括号取反
语法
语法
[^abc] 排除中括号里的a、b、c ,和单独的^符号,作用是不同的
[^a-z] 排除小写字母实践
#[^a-z] 排除小写字母
grep '[^a-z]' t1.log
#找出以I开头,且结尾不是.的行
grep -E '^I.*[^.]$' t1.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!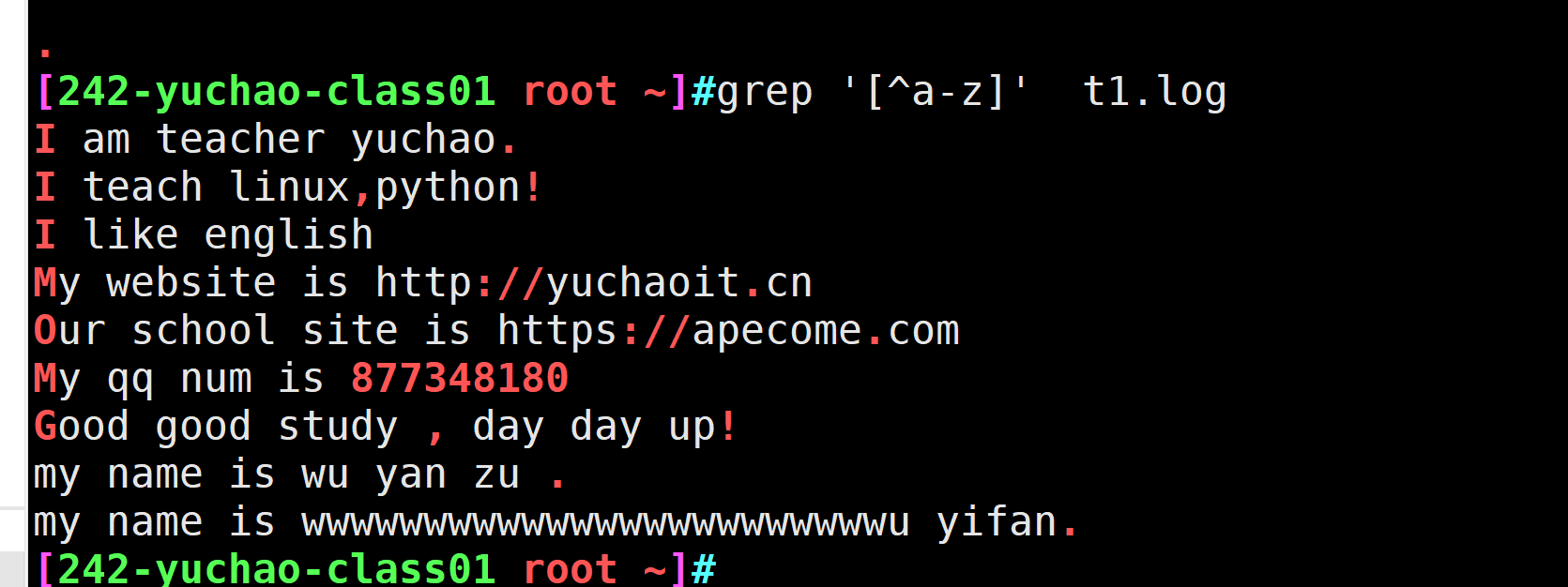
{ } 花括号(扩展正则)
grep命令和扩展正则结合使用
grep '基本正则表达式' t1.log
# 使用-E参数是最新扩展正则用法
grep -E '扩展正则表达式' t1.log
egrep '扩展正则表达式' t1.log####测试数据
[242-yuchao-class01 root ~]#cat t1.log
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
aaaaaaaa
aaaaaple
Good good study , day day up!
my name is wu yan zu .
my name is wwwwwwwwwwwwwwwwwwwwwwwwu yifan.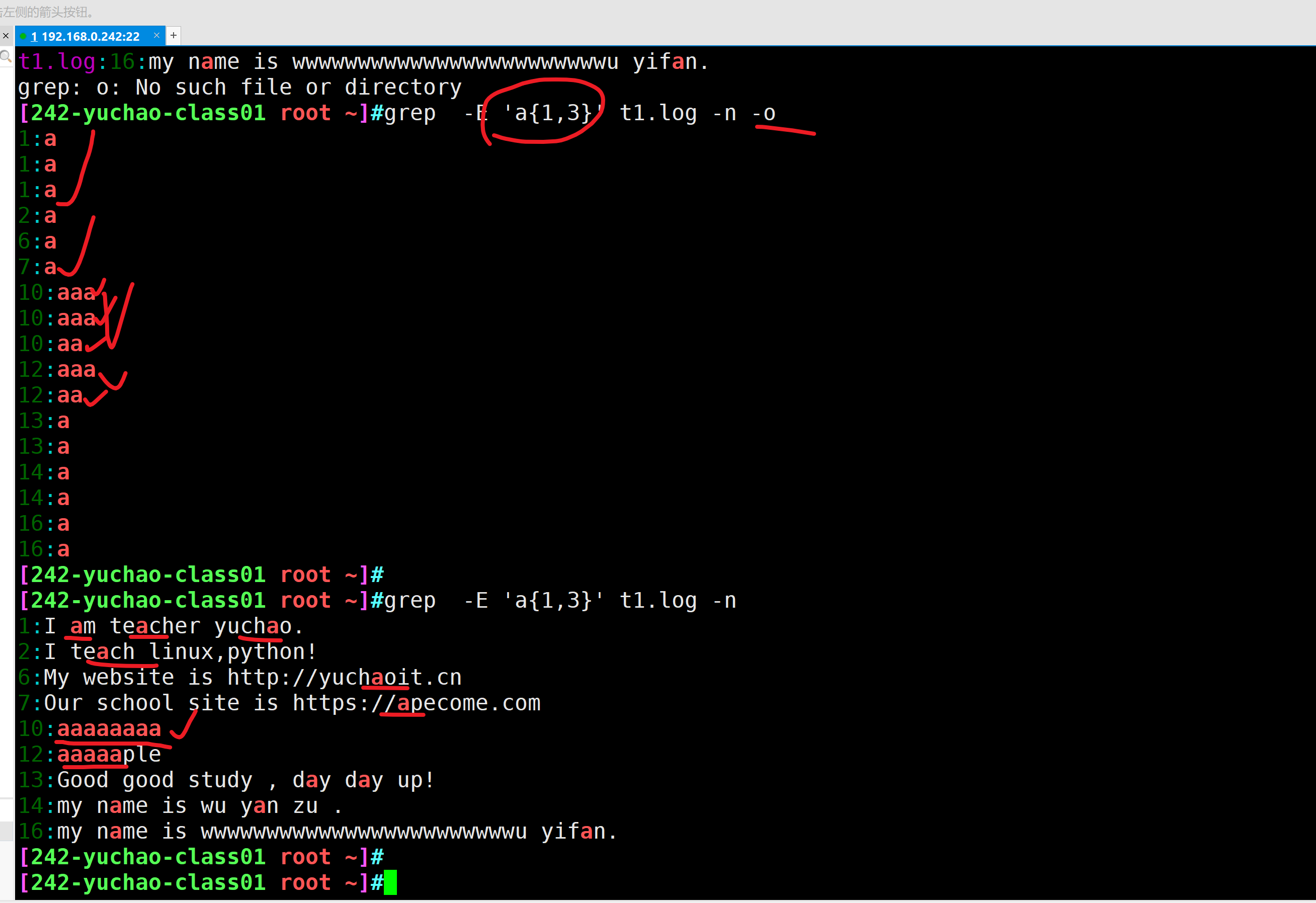
a\{n,m\}
a\{n,m\} 重复字符a,n到m次
a\{1,3\} 重复字符a,1到3次
# 建议用这个语法 ,使用-E参数
grep -E 'a{1,3}' t1.log####实践
####测试数据
测试数据
[root@yuchao-tx-server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my qq num is not 87777773333344444888811188880000
Goog good study , day day up!####实践
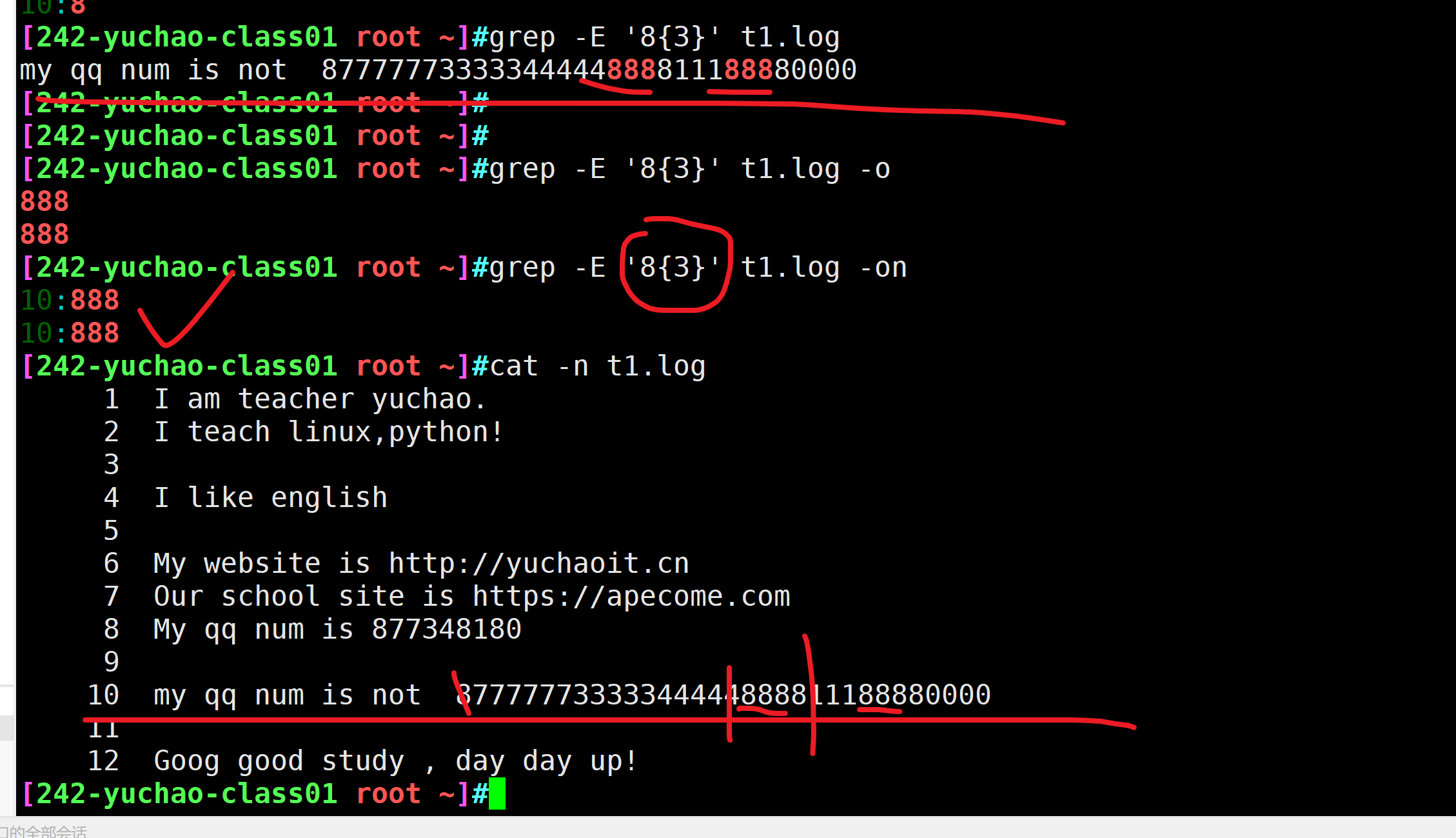
匹配数字8一次到3次
grep -E '8{1,3}' t1.log每次最少找出2个8、最多3个8
grep -E '8{2,3}' t1.loggrep 默认不认识扩展正则 {}
grep默认不认识扩展正则{},识别不到它的特殊作用,因此只能用转义符,让他成为有意义的字符。
解决办法
办法1
使用转义符 \{\}
办法2,让grep认识花括号,可以省去转义符
使用egrep命令
或者 grep -E匹配数字8一次到3次
grep -E '8{1,3}' t1.log每次最少找出2个8、最多3个8
grep -E '8{2,3}' t1.log每次只找出3个8
grep -E '8{3}' t1.loga\{n,\}
重复a字符至少n次,可以用简写了
8至少出现2次
grep -E '8{2,}' t1.log
8至少出现1次
grep -E '8{1,}' t1.loga\{n\}
重复字符a,正好n次。
重复8出现3次
grep -E '8{3}' t1.log a\{,m\}
匹配字符a最多m次。
重复8出现最多3次
grep -E '8{,3}' t1.log
grep -E '8{最少重复次数,最多重复次数}' t1.log扩展正则表达式(ERE)
这样记忆就好
- 基本正则表达式
- 属于早期正则表达式,支持一些基本的功能
- 与grep、sed命令结合使用
- 扩展正则表达式
- 后来添加的正则表达式
- 和egrep、awk命令结合
- 必须是grep -E 参数
###扩展正则表达式(ERE)
这样记忆就好
- 基本正则表达式
- 属于早期正则表达式,支持一些基本的功能
- 与grep、sed命令结合使用
- 扩展正则表达式
- 后来添加的正则表达式
- 和egrep、awk命令结合
####测试数据
测试数据
[root@yuchao-tx-server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my qq num is not 87777773333344444888811188880000
Goog good study , day day up!+ 加号
语法
+
重复前一个字符1次或多次
注意和*的区别,*是0次或多次,找不到的那一行,也会显示出来匹配一次或者多次0,没有0的行是不会显示的
0+
要求
每次找出一个、或者多个数字零
找出存在至少一次0的行
grep '0+' t1.log
[242-yuchao-class01 root ~]#grep -E '0+' t1.log -n
8:My qq num is 877348180
10:my qq num is not 87777773333344444888811188880000[0-9]+
从文中找出连续的数字,等于排除字母,特殊符号、空格
顺丰快递的数据库文件
地区:
手机号: 连续11位的数字 [0-9]{11}
姓名:
寄件人:
收件人: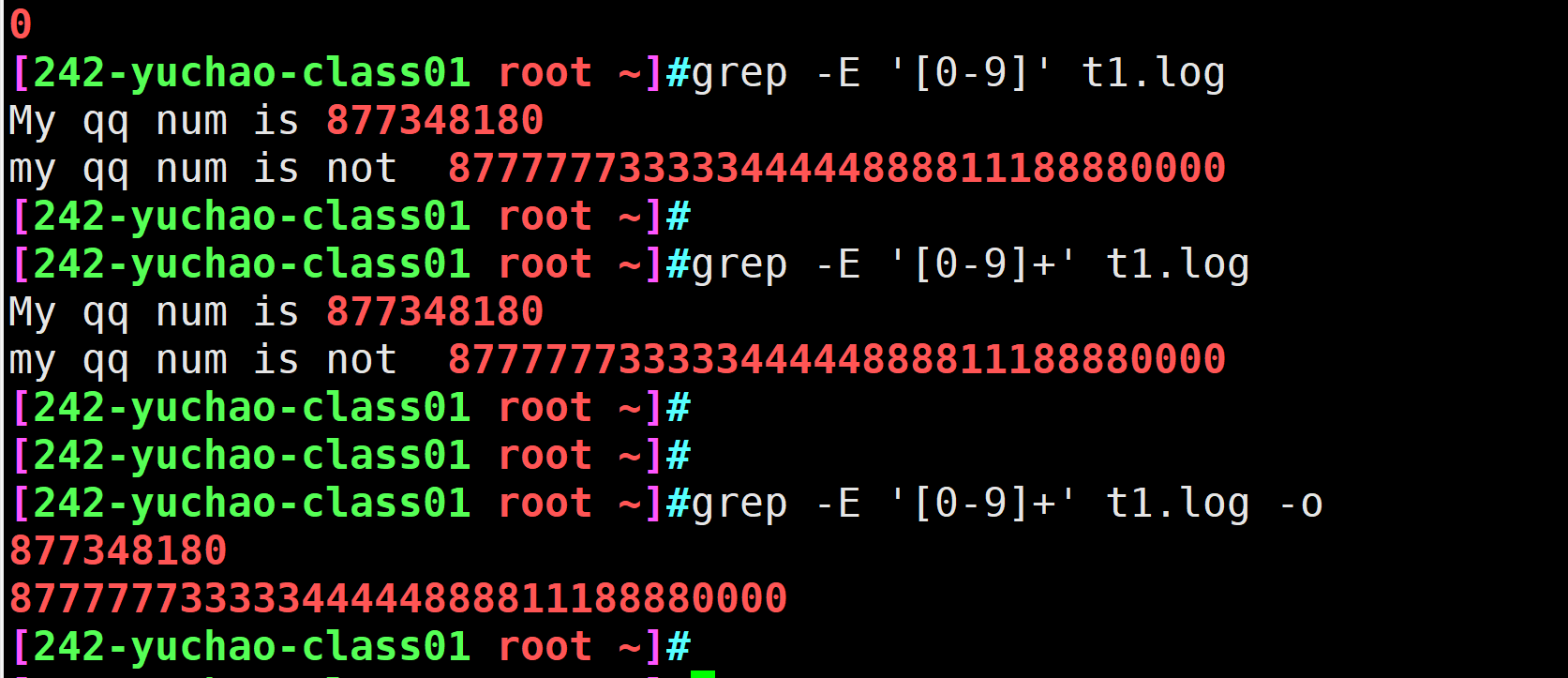
提取出文件中的连续的数字
grep -E '[0-9]' t1.log[a-z]+
找出连续的小写字母、等于排除大写字母、标点符号、数字,空格,找出每一个单词了吧
grep -E '[a-z]+' t1.log[A-Za-z0-9]+
注意,这里添加了+号,就是找的连续的字母数字了
缺少+号则是每次匹配单个字符
grep -E '[A-Za-z0-9]+' t1.log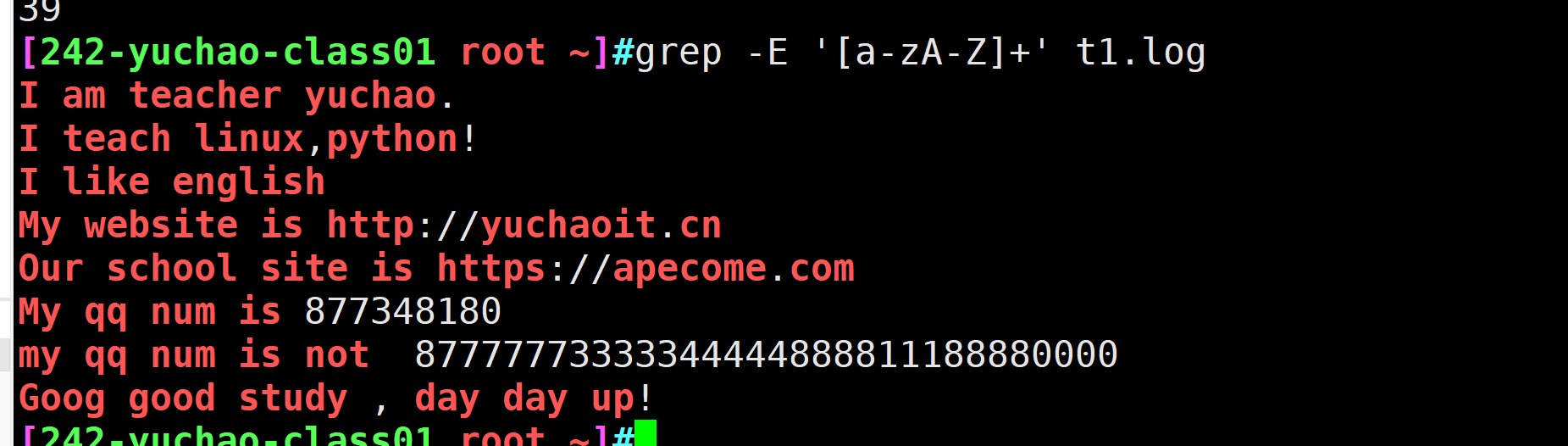
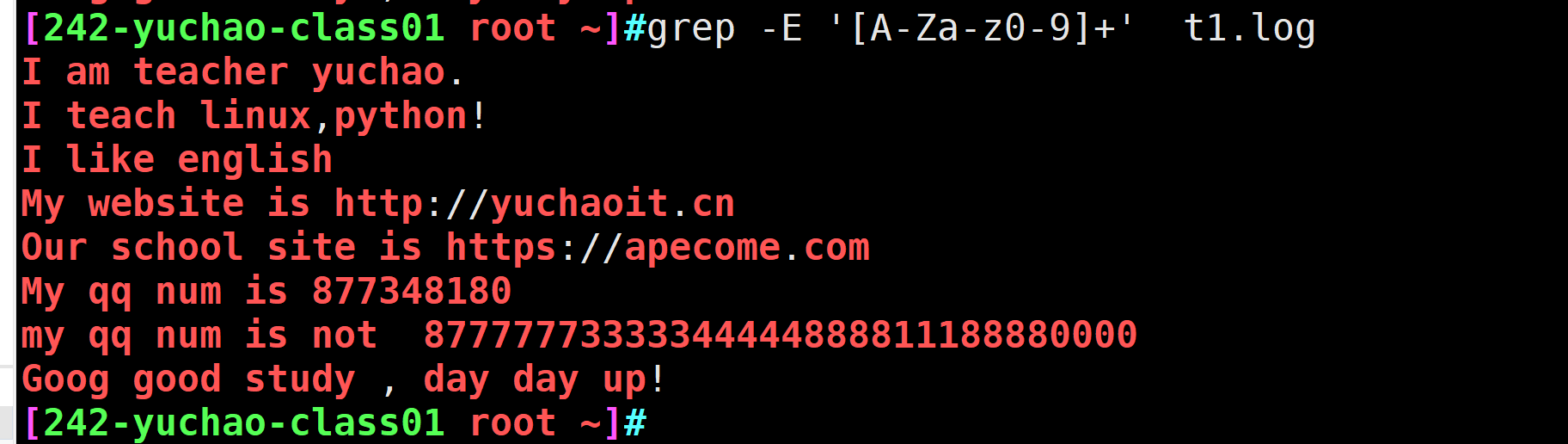
[^A-Za-z0-9]+]
此写法,找出除了数字、大小写字母以外的内容,如空格、标点符号。
你可以使用-o参数,看到每次匹配的内容。
*和+的区别
语法
*是重复0次、重复多次,因此没匹配到的行也过滤出来了
+是重复1次、多次、因此至少匹配到1次才看到例如,我们来找到字母o,看如下2个写法
'o+'
+号,是重复前面的字符1次或N次
重复找这个o1次,还是多次
grep -E 'o+' t1.log
重复这个9,零次,或者N次
'9*'####go*d和go+d和go?d区别
准备测试数据
[root@yuchao-tx-server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!关于寻找god、goooood、gd的区别
go*d 可以有0个或者n个字母o
go*d 可以找到啥
grep 'go*d' god.txt -n -i
god
goooooooooood
gd
go+d 可以有一个或n个字母o
go+d 可以找到啥
扩展正则,使用-E才行
grep -E 'go+d' god.txt -n -i
god
goooooooooooood
go?d 可以有0个或者1个字母0
go?d 可以找到啥
[242-yuchao-class01 root ~]#grep -E 'go?d' god.txt -n -i -o
1:God
1:Gd
###| 或者符
####测试数据
[242-yuchao-class01 root ~]#cat t1.log
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
#my qq num is not 87777773333344444888811188880000
#
#Goog good study , day day up!#找出上文中除了空行和注释行的内容
grep -v '^#' t1.log | grep -v '^$'竖线在正则里是或者的意思
查看文件系统的inode数量和block信息
ext4文件系统
1.准备好分区,以及挂载该ext4
2. 使用dumpe2fs命令查看该分区信息即可,过滤inode和block相关信息
得看该分区,而不是挂载点
[242-yuchao-class01 root ~]#dumpe2fs /dev/sdc | grep -E -i '^inode|^block'
dumpe2fs 1.42.9 (28-Dec-2013)
Inode count: 1310720
Block count: 5242880
Block size: 4096
Blocks per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Inode size: 256
xfs_info
[242-yuchao-class01 root ~]#xfs_info /xfs_test/ |grep -E 'isize|block'
meta-data=/dev/sdd isize=512 agcount=4, agsize=3276800 blks
data = bsize=4096 blocks=13107200, imaxpct=25
log =internal bsize=4096 blocks=6400, version=2
realtime =none extsz=4096 blocks=0, rtextents=0查看内存和swap的容量信息
[242-yuchao-class01 root ~]#free -m | grep -E -i '^mem|^swap'
Mem: 1821 116 1370 9 334 1514
Swap: 2047 0 2047排除文件的空行、注释行
grep -v参数,对结果取反
排除空行
grep -v '^$' t1.log
排除注释行
grep -v '^#' t1.log
排除文件的空行、注释行
grep -v '^$' t1.log | grep -v '^#'
[242-yuchao-class01 root ~]#grep -v '^$' t1.log | grep -v '^#' -n
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
# 使用正则的或的用法
grep -E '^#|^$' t1.log -n -v###( ) 括号、分组符
语法
() 作用是将一个或者多个字符捆绑在一起,当做一个整体进行处理
1.可以用括号,把正则括起来,以及系统最多支持9个括号
小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体
括号内的数据,可以向后引用,
() () () () \1 \2 \3 \4
括号()内的内容可以被后面的"\n"正则引用,n为数字,表示引用第几个括号的内容
\1:表示从左侧起,第一个括号中的模式所匹配到的字符
\2:从左侧起,第二个括号中的模式所匹配到的字符测试数据
测试数据
[root@yuchao-tx-server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
I am glad to see you, god,you are a good god!要求仅仅匹配出glad和good
分组的第一个用法,将数据,正则当做一个整体处理
grep -E 'glad|good' god.log
括号用法
grep -E 'g(la|oo)d' god.log
g.........d分组与向后引用
向后引用用法, 在grep中不容易体现,
明天学sed,就会发现分组括号,向后引用更多用法了
语法
()
分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容
\n
引用前面()里的内容,例如(abc)\1 表示匹配abcabc测试数据
[root@yuchao-tx-server test]# cat lovers.log
I like my lover.
I love my lover.
He likes his lovers.
He love his lovers.提取love出现2次的行
[242-yuchao-class01 root ~]#grep -E '^.*(love).*\1.*' lovers.txt -o
I love my lover.
He love his lovers.提取/etc/passwd 中用户名和登录解释器名字一样的行