时间相关函数
cast()函数
CAST函数用于将一个值转换为指定的数据类型,转换成任何类型都可以- 但cast()没有办法格式化
它的语法如下:
CAST ( expression AS data_type )To_char()
TO_CHAR()函数用于将日期或时间类型的数据格式化为字符串- format可以定制,比如
YYYY/MM-DD - format还可以用来提取date类型的年月日
-- 语法如下
TO_CHAR(expression, format)
-- 举个例子
SELECT TO_CHAR(your_date_column, 'YYYY-MM-DD') AS formatted_date
FROM your_table;
-- 举个例子,如下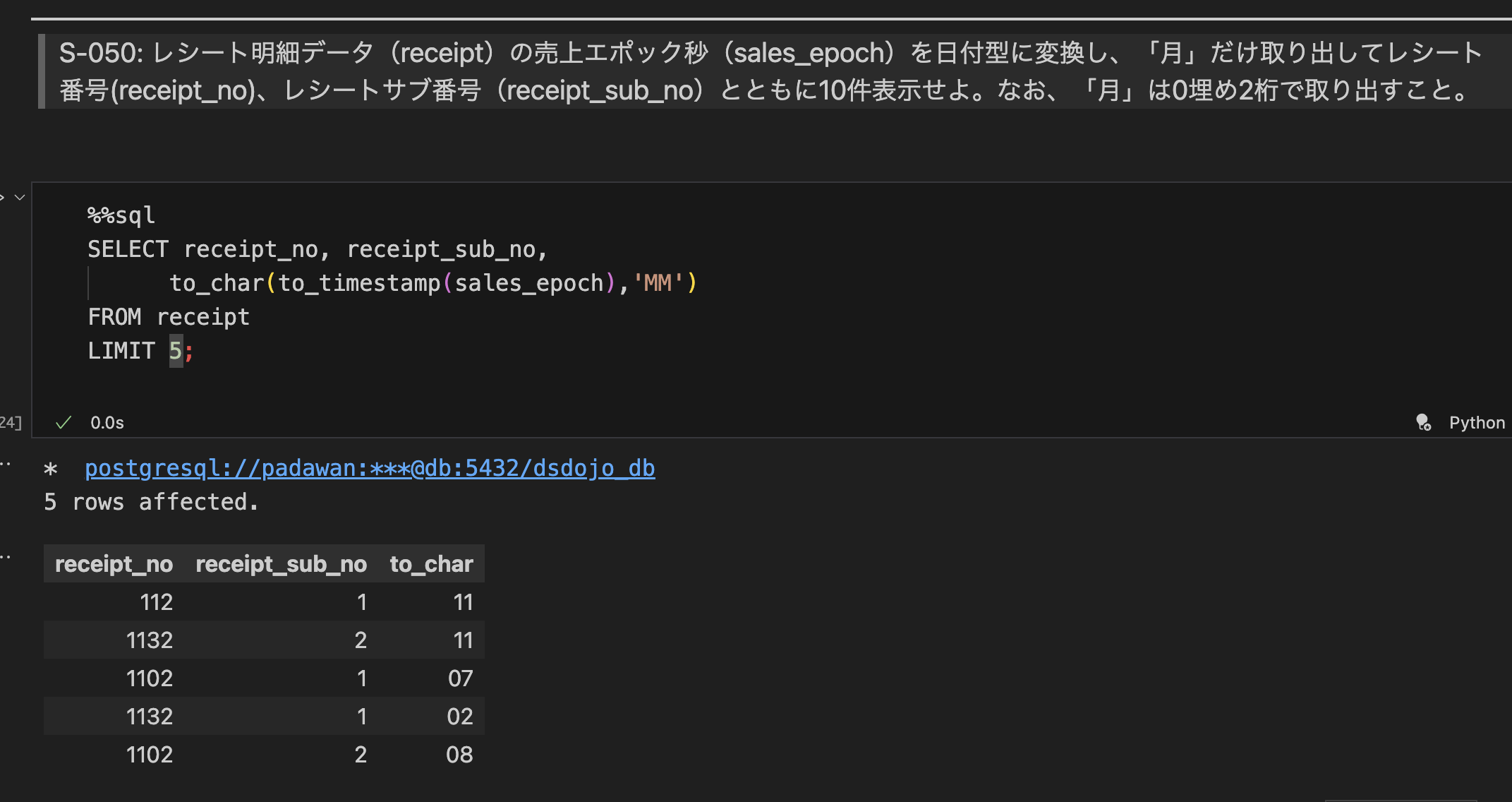
to_date()
- format指的是你给的日期字符串的format,不是你想变成的日期表达形式,比如
YYYY/MM-DD - 比如说想变成
YYYY/MM-DD这个样子,只能使用字符串形式表达 - 时间格式支持
YYYY-MM-DD或YYYY-DD-MM,取决于你指定的format。 - 不写gei ding
SELECT
TO_DATE('2024-05-13', 'YYYYMMDD') AS converted_date
from tableto_timestamp()
- 转化为时间戳类型
SELECT TO_TIMESTAMP('2024-05-13 12:34:56', 'YYYY-MM-DD HH24:MI:SS') AS timestamp_value;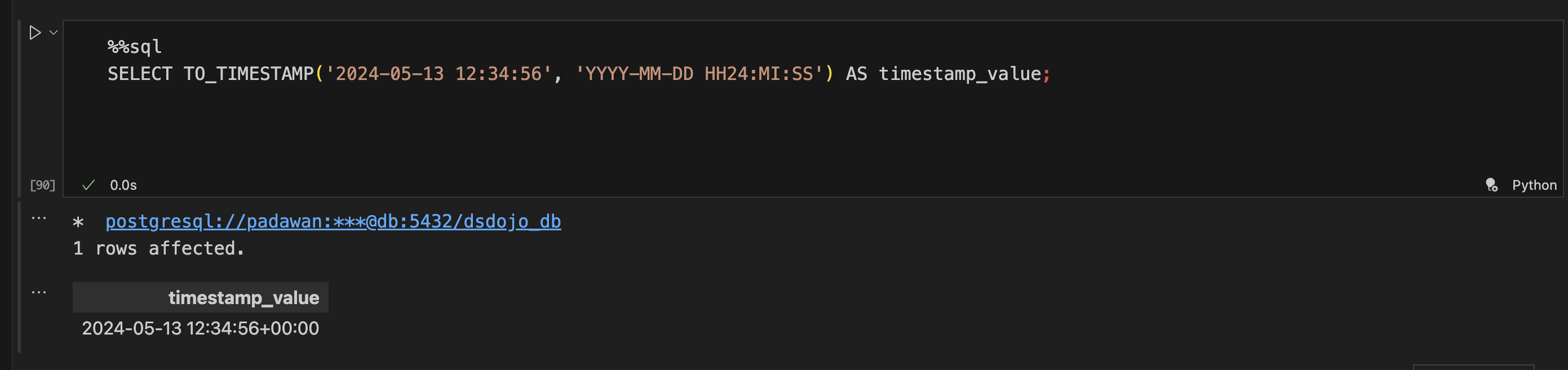
unix时间戳类型转换为date类型
unix时间戳:
unix时间戳是int类型
比如
1620978678123
普通时间戳:
普通时间戳是字符串类型
比如:
- ISO 8601 标准格式:
2024-05-14T12:34:56Z - 年-月-日 时:分:秒 格式:
2024-05-14 12:34:56 - 年/月/日 时:分:秒 格式:
2024/05/14 12:34:56 - 年月日时分秒 格式:
20240514123456
在这些示例中,时间戳以不同的形式表示日期和时间信息,方便人类阅读和理解。
- ISO 8601 标准格式:
unix时间戳类型转换为date类型
所以要先从整数类型的unix时间戳,转换成字符串类型的普通时间戳
由于返回的日期字符串类型不是
'YYYY-MM-DD'或'YYYY-DD-MM'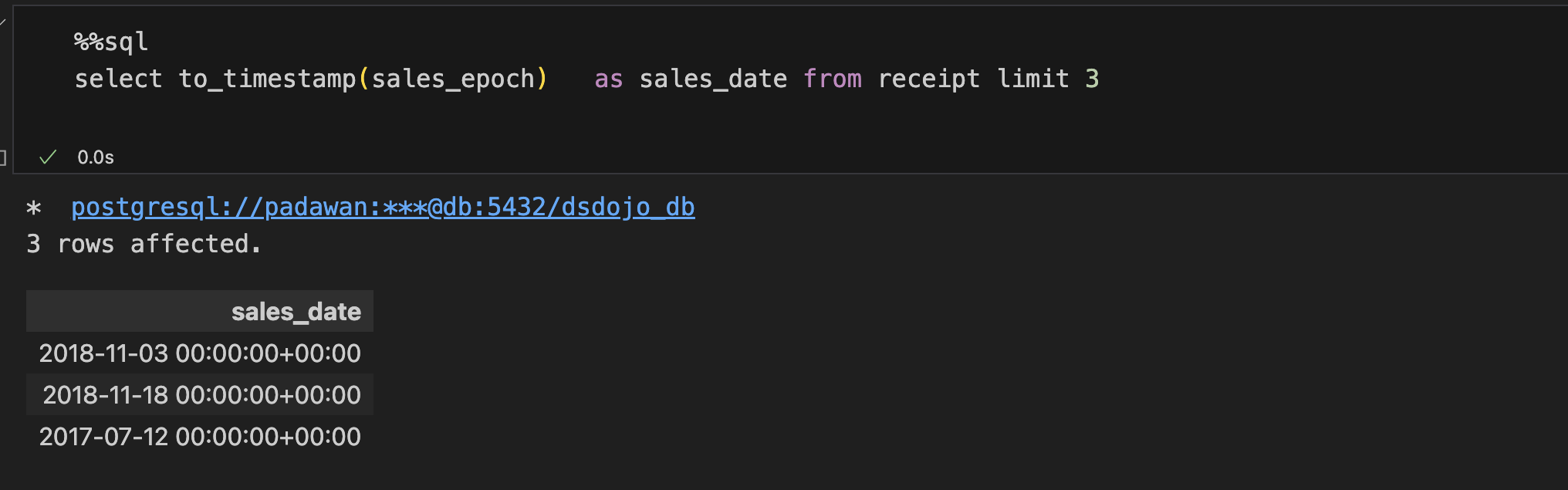
所以从普通时间戳转换为date类型时,使用cast()
-- 所以要先从整数类型的unix时间戳,转换成字符串类型的普通时间戳,再转化为date类型
select cast(to_timestamp(sales_epoch) as date) as sales_date from receipt提取年月日
SELECT EXTRACT(YEAR FROM datetime_column) AS year,
EXTRACT(MONTH FROM datetime_column) AS month,
EXTRACT(DAY FROM datetime_column) AS day,
EXTRACT(HOUR FROM datetime_column) AS hour,
EXTRACT(MINUTE FROM datetime_column) AS minute,
EXTRACT(SECOND FROM datetime_column) AS second
FROM your_table;获取当前日期
SELECT EXTRACT(YEAR FROM CURRENT_DATE) AS year,
EXTRACT(MONTH FROM CURRENT_DATE) AS month,
EXTRACT(DAY FROM CURRENT_DATE) AS day;数值型转换为日期型
- 不能直接用cast
- 先转换为字符串类型,再由字符串类型转换为date类型
- 要转换为变长(varchar)而不是定长(char)
select to_date(cast(sales_ymd as varchar)) as sales_ymd from customerdate_trunc()
date_trunc() 是 PostgreSQL 中用于截断日期或时间到指定精度的函数。这个函数可以用来截断日期或时间到年、月、日、小时等级别。
以下是 date_trunc() 的基本语法和一些示例:
date_trunc('precision', timestamp)precision是截断日期的精度,可以是year,month,day,hour,minute,second等。timestamp是要截断的时间戳。
Extract()
EXTRACT() 函数用于从日期时间值中提取特定部分,例如年、月、日、小时、分钟等,并返回整数值。在 PostgreSQL 中,它的语法如下:
示例:
假设你有一个名为 orders 的表,其中包含一个日期时间列 order_date,你想提取订单日期的年份和月份。
SELECT EXTRACT(YEAR FROM order_date) AS order_year,
EXTRACT(MONTH FROM order_date) AS order_month
FROM orders;这将返回订单日期的年份和月份。
EXTRACT() 函数在计算时会将日期时间值转换为本地时区,因此它返回的结果可能会受到时区设置的影响。
extract可以提取unix时间戳
select extract(epoch from age('2023-12-23 09:54:56','2013-12-23 07:34:56'))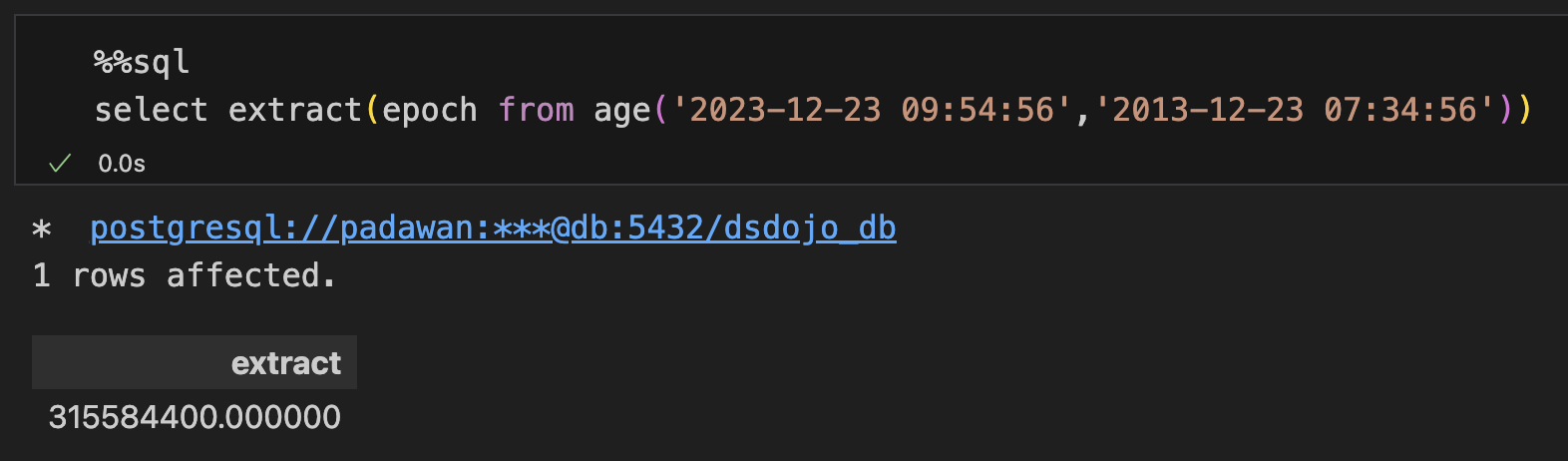
extract可以提取星期几
- 返回值:星期天被表示为0,星期一表示为1,以此类推,星期六表示为6。
SELECT extract(dow from to_date('2024-05-12','YYYY-MM-DD'));举2个例子:
- 要从一堆日期中找出星期一的日期
sqlSELECT date_column FROM your_table WHERE EXTRACT(DOW FROM date_column) = 1;- 计算从当周星期一开始的经过的天数
sqlselect EXTRACT(DOW FROM (sales_ymd - 1)) AS elapsed_days FROM receipt
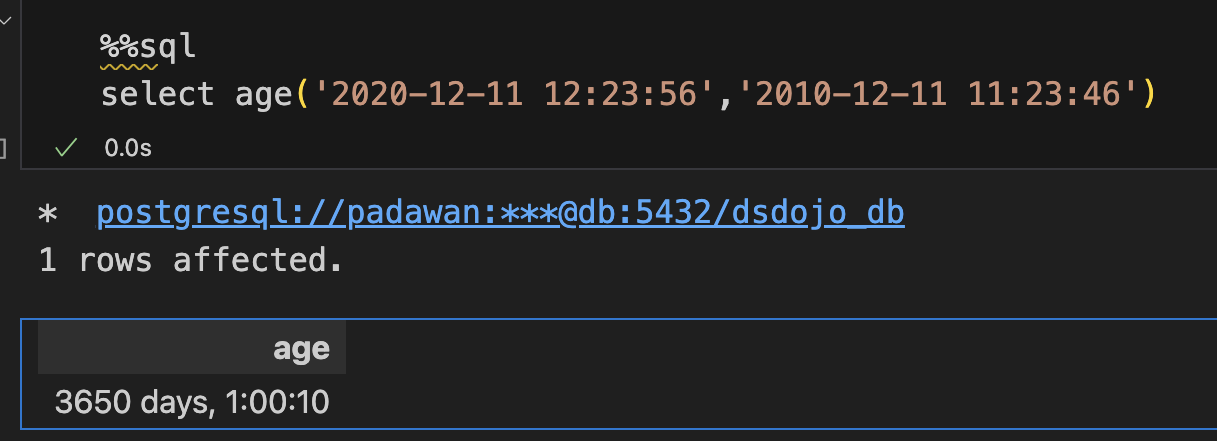
age()
在 PostgreSQL 中,age() 函数用于计算两个日期之间的时间间隔,并以 INTERVAL 类型返回结果。以下是 age() 函数的语法:
age(end_date, start_date)end_date是较晚的日期。start_date是较早的日期。
各种计算函数
substr()
SUBSTR() 是一个 SQL 函数,用于从字符串中提取子字符串。它的语法通常如下:
SUBSTR(string, start, length)其中:
string是要从中提取子字符串的源字符串。start是要开始提取的位置。位置从 1 开始计数。length是要提取的子字符串的长度。
假设有一个字符串 'Hello, World!',我们来演示如何使用 SUBSTR() 函数从中提取子字符串。
SELECT SUBSTR('Hello, World!', 1, 5) AS substring;
-- 结果为Hello在这个例子中,我们提取了从第一个位置开始的长度为 5 的子字符串,结果为 'Hello'。
percentile_count()
- 是数据集中某一列的四分位点,如每个人销售总额的四分位点,在用每个人的销售总额和四分位点进行比较
以下是一个示例,演示了如何在 PostgreSQL 中使用 PERCENTILE_DISC() 函数来计算离散分布函数的值:
SELECT
PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY column_name) AS pct25
FROM
table_name;- 举个例子
S-055: レシート明細(receipt)データの売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額合計とともに10件表示せよ。カテゴリ値は順に1〜4とする。
>
> - 最小値以上第1四分位未満 ・・・ 1を付与
> - 第1四分位以上第2四分位未満 ・・・ 2を付与
> - 第2四分位以上第3四分位未満 ・・・ 3を付与
> - 第3四分位以上 ・・・ 4を付与- 第一张子表,先求每个人的销售总额,字段为customer_id,sum_amount
- 第二张子表,所有人销售总额数组的四分位点,就四个值
- 第三章子表,由于四分位点就四个值,但要将每个用户的销售总额分别和这四个值进行比较,所以使用笛卡尔积链接表一和表二,然后查询
-- 第一张子表,先求每个人的销售总额,字段为customer_id,sum_amount
WITH sales_amount AS(
SELECT
customer_id,
SUM(amount) AS sum_amount
FROM
receipt
GROUP BY
customer_id
),
-- 第二张子表,所有人销售总额数组的四分位点,就四个值
sales_pct AS (
SELECT
PERCENTILE_CONT(0.25) WITHIN GROUP(ORDER BY sum_amount) AS pct25,
PERCENTILE_CONT(0.50) WITHIN GROUP(ORDER BY sum_amount) AS pct50,
PERCENTILE_CONT(0.75) WITHIN GROUP(ORDER BY sum_amount) AS pct75
FROM
sales_amount
)
SELECT
a.customer_id,
a.sum_amount,
CASE
WHEN a.sum_amount < pct25 THEN 1
WHEN pct25 <= a.sum_amount AND a.sum_amount < pct50 THEN 2
WHEN pct50 <= a.sum_amount AND a.sum_amount < pct75 THEN 3
WHEN pct75 <= a.sum_amount THEN 4
END AS pct_group
FROM sales_amount a
CROSS JOIN sales_pct p -- 由于四分位点就四个值,但要将每个用户的销售总额分别和这四个值进行比较,所以使用笛卡尔积连表
LIMIT 10
;log()
在 PGSQL 中计算对数(logarithm)可以使用 LOG() 函数。LOG() 函数默认计算以 10为底的自然对数,其语法通常如下:
LOG(base, x)- 计算以e为底的对数
ln(x)求log,ln要注意的点!!!
数学上不能计算0的对数!!!!!!!!!
所以稳妥起见,要先把0过滤掉,再求对数
举个例子:
-- レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を常用対数化(底10)して顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
with null_sum_amount as (
select customer_id,
sum(amount) as sum_amount
from receipt
where customer_id not like 'Z%'
group by customer_id
),
sum_amount_table as(
select customer_id,sum_amount
from null_sum_amount
where sum_amount != 0
)
select customer_id,
log(10,sum_amount) as log_sum_amount
from sum_amount_table
limit 2
-- 结果如下图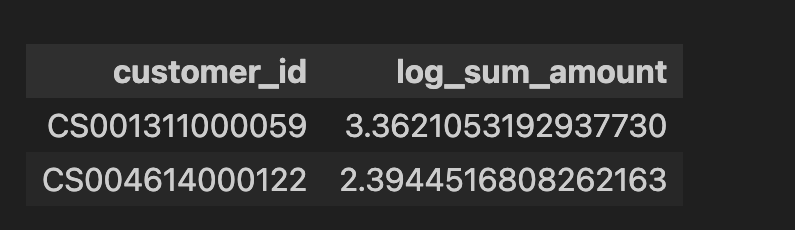
随机抽样
-- 顾客数据(customer)从中随机抽取1%的数据
SELECT * FROM customer WHERE random() <= 0.01-- 顾客数据(customer)从中随机抽取1%的数据
SELECT * FROM customer TABLESAMPLE BERNOULLI(1) REPEATABLE(42) LIMIT 10;- -使用 TABLESAMPLE 关键字进行表抽样,以便从表中获取随机样本。
- 使用 TABLESAMPLE 关键字时,你可以选择不同的抽样方法,其中包括 BERNOULLI 和 SYSTEM 方法。
REPEATABLE(42)表示设置了一个种子值为 42,这个种子值将用于确定随机抽样的方式。
标准化相关的函数
avg()
SELECT AVG(column_name) AS average_value
FROM table_name;方差
两个计算方差的函数:
VAR_POP(column_name): 计算总体方差VAR_SAMP(column_name): 计算样本方差
示例:
SELECT VAR_POP(column_name) AS variance_population,
VAR_SAMP(column_name) AS variance_sample
FROM table_name;标准差
两个计算标准差的函数:
STDDEV_POP(column_name): 计算总体标准差STDDEV_SAMP(column_name): 计算样本标准差
示例:
SELECT STDDEV_POP(column_name) AS stddev_population,
STDDEV_SAMP(column_name) AS stddev_sample
FROM table_name;计算地理距离
SELECT
ST_DISTANCE(ST_GEOGPOINT(lon1, lat1), ST_GEOGPOINT(lon2, lat2)) AS distance
FROM your_table;ST_DISTANCE()是一个地理空间函数,用于计算两个地理坐标点之间的距离,计算出的距离单位是米。- geometry1:地点1
- geometry1:地点2
sqlST_DISTANCE(geometry1, geometry2)ST_GEOGPOINT()是地理空间函数,用于创建一个地理坐标点。- 参数俩:经纬度
sqlST_GEOGPOINT(longitude, latitude)
pivot()
业务中几乎都是取完数据后在dataframe中处理,这里做个参考吧,不用太care
通常情况下,PIVOT 操作需要以下几个要素:
- 聚合函数:用于对数据进行汇总的函数,例如
SUM、COUNT、AVG等。 - 行标识:决定了最终生成的新列的行。
- 列标识:决定了最终生成的新列的列。
- 需要转换为列的值:这些值将成为新列的列头。
下面是一个简单的示例
-- 生成测试数据 ,假设有一个表存储了销售订单信息:
CREATE TABLE Sales (
OrderID int PRIMARY KEY,
ProductID int,
Quantity int,
OrderDate date
);
INSERT INTO Sales (OrderID, ProductID, Quantity, OrderDate)
VALUES
(1, 101, 10, '2024-05-01'),
(2, 102, 15, '2024-05-02'),
(3, 101, 20, '2024-05-03'),
(4, 103, 12, '2024-05-04');
-- 现在,如果想按照产品 ID 将销售数量进行汇总,可以使用 `PIVOT` 操作:
SELECT ProductID, [2024-05-01], [2024-05-02], [2024-05-03], [2024-05-04]
FROM (
SELECT ProductID, Quantity, OrderDate
FROM Sales
) AS SourceTable
PIVOT
(
SUM(Quantity)
FOR OrderDate IN ([2024-05-01], [2024-05-02], [2024-05-03], [2024-05-04])
) AS PivotTable;在这个例子中,PIVOT 操作将会将 OrderDate 列的不同日期作为新列的列头,并根据 ProductID 和 Quantity 来汇总数据。
经验UP ! UP !
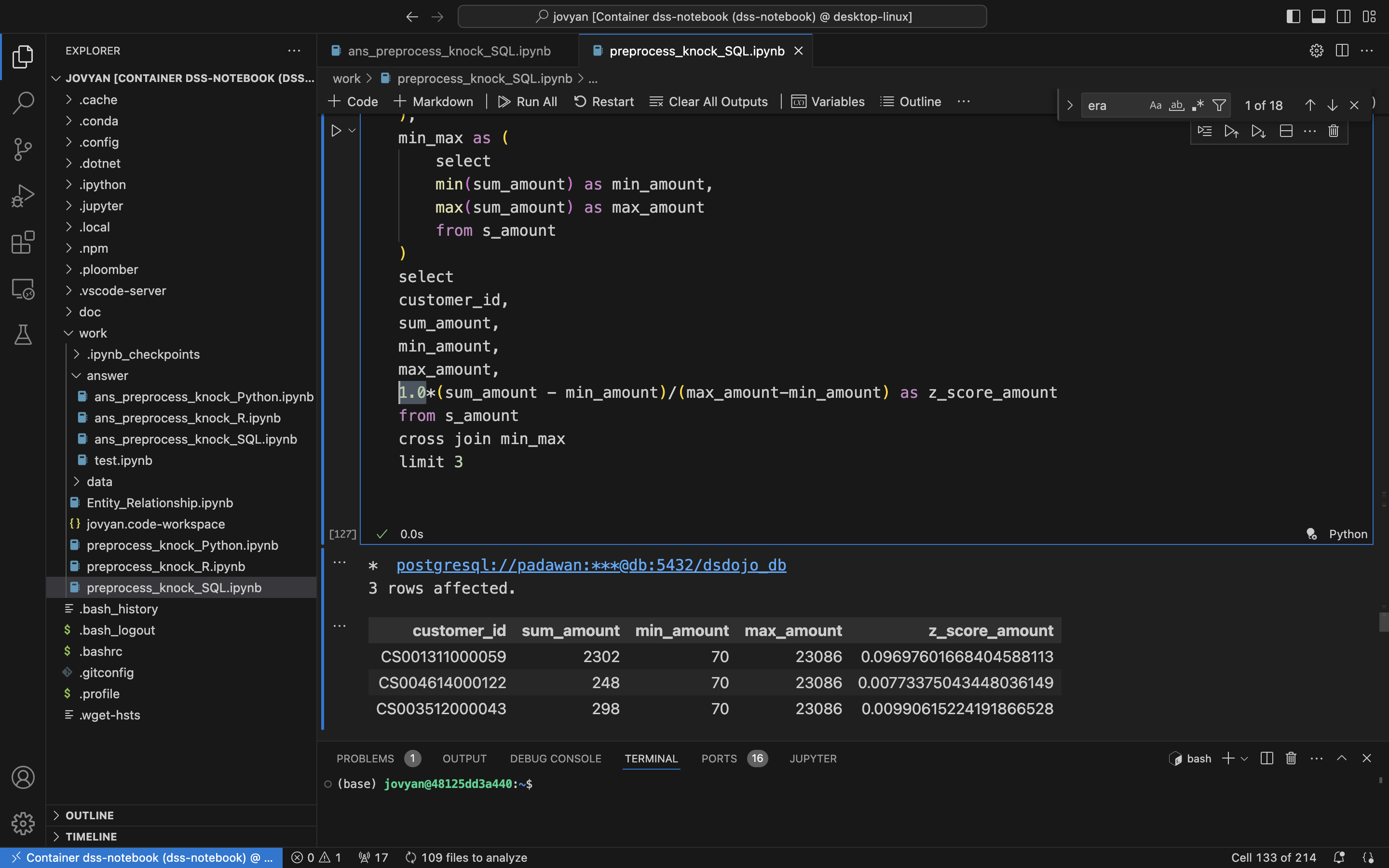
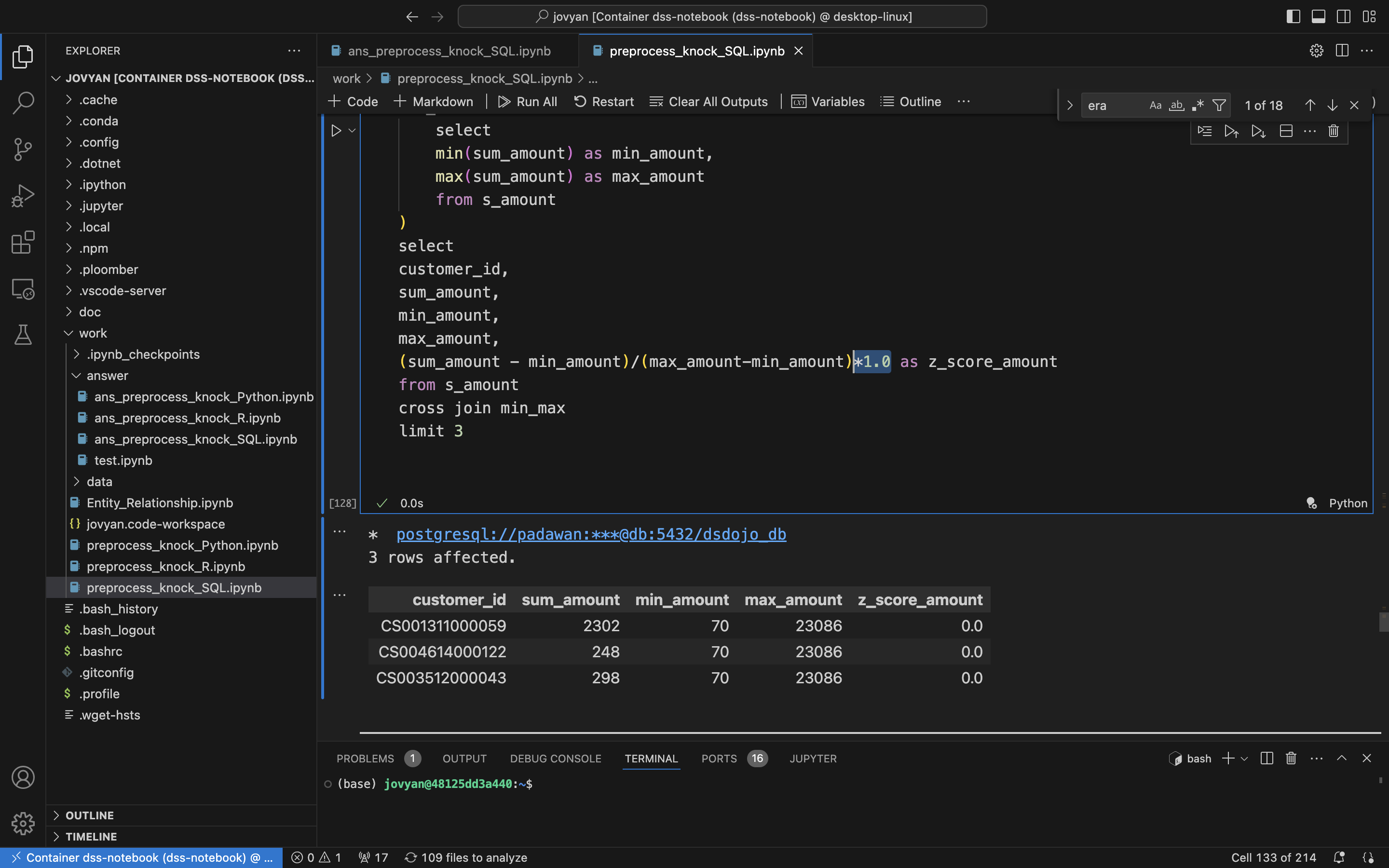
int转float的注意
- 1.0 乘的位置不同,理论上从int转换为float是一样的
- 但是就是执行除了不一样的结果,如下面两个图
- 所以就记得把1.0乘在前面的位置就好了
- 不只是sql,任何语言涉及到float都要,脑子里叮一下,单独注意一下